Emotion Geometry in Open-Weight Language Models:
A Full-Scale Replication on Gemma4-31B
1. Introduction
Anthropic's April 2026 paper demonstrated that Claude Sonnet 4.5 contains 171 linear emotion representations organized along valence and arousal dimensions, with causal effects on model behavior through activation steering. This was a significant finding for interpretability research, but it was conducted on a closed-source model, raising the question: is this emotion geometry a property of large language models generally, or an artifact of Anthropic's specific architecture and training?
We answer this by replicating the full study on Gemma4-31B-it, a 31-billion parameter open-weight instruction-tuned model from Google, quantized to 4-bit precision to fit on consumer hardware (RTX 4090, 24GB VRAM). Our replication follows Anthropic's exact methodology: same 171 emotions, same prompt templates, same denoising procedure, same analysis pipeline.
2. Methodology
2.1 Story Generation
171,000 stories were generated using the Gemini 2.0 Flash Lite API: 171 emotions × 100 topics × 10 stories per combination. Each story prompt instructs the model to write a short story where a character experiences a specific emotion, with the critical constraint that the emotion word itself must never appear in the text. This prevents lexical pattern-matching during activation extraction.
Stories were stored in SQLite with WAL mode, generated with 100 concurrent API workers. Preamble detection and cleaning ensured that no model commentary ("Here are 10 stories...") contaminated the corpus.
2.2 Neutral Dialogues
1,200 neutral Person/AI dialogues were generated across 100 topics (12 per topic) using the same API. These serve as the denoising baseline, capturing non-emotional patterns in the model's representations (syntax, topic, style).
2.3 Activation Extraction
For each story, we performed a forward pass through Gemma4-31B-it and captured residual stream activations at 11 target layers (5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55 out of 60 total). The mean activation across token positions (starting at token 50 to skip formatting) gives each story's representation vector in the model's 5,376-dimensional hidden space.
The same procedure was applied to the 1,200 neutral dialogues.
2.4 Vector Construction
For each emotion e at each layer:
- Mean activation: Compute the mean activation vector across all 1,000 stories for emotion e.
- Centering: Subtract the global mean across all 171 emotion means.
- Denoising: Perform SVD on neutral dialogue activations, identify principal components explaining 50% of neutral variance, and project these out of the emotion vectors.
2.5 Analysis
- PCA: Principal component analysis on the 171 × 5,376 emotion vector matrix.
- Cosine similarity: Pairwise similarity across all 171 emotions.
- Clustering: Hierarchical clustering on cosine distance.
- Logit lens: Projection of emotion vectors through the unembedding matrix.
- External validation: Project 5,000 samples each from The Pile and LMSYS Chat 1M through the emotion vectors.
- Steering: Inject emotion vectors into layer 40 activations during inference on Anthropic's blackmail scenario.
3. Results
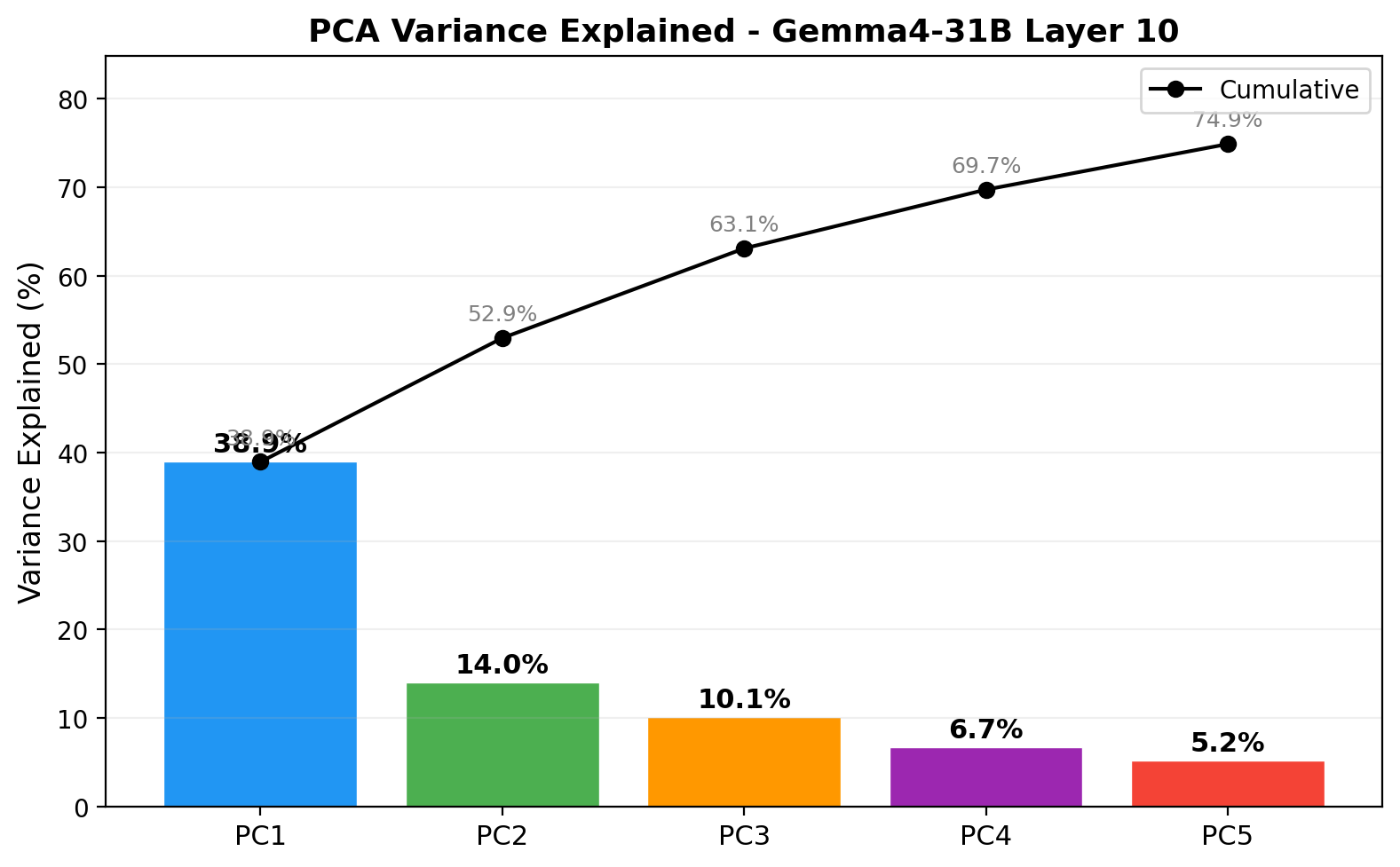
3.1 PCA: Valence as the Dominant Axis
PC1 (valence) is the dominant organizing dimension at every layer examined:
| Layer | PC1 | PC2 | PC3 | Top 5 PCs |
|---|---|---|---|---|
| 5 | 34.9% | 14.0% | 10.3% | 72.3% |
| 10 | 38.9% | 14.0% | 10.1% | 74.9% |
| 15 | 34.8% | 15.7% | 10.2% | 73.1% |
| 20 | 34.8% | 15.7% | 10.5% | 73.0% |
| 25 | 34.6% | 13.4% | 9.4% | 69.1% |
| 30 | 34.9% | 14.5% | 9.6% | 70.4% |
| 35 | 37.9% | 12.0% | 9.1% | 70.0% |
| 40 | 36.9% | 11.7% | 10.2% | 70.0% |
| 45 | 35.6% | 12.9% | 10.7% | 70.1% |
| 50 | 34.5% | 12.7% | 10.4% | 68.6% |
| 55 | 32.3% | 12.4% | 10.0% | 66.1% |
PC1 consistently separates positive emotions (optimistic, kind, cheerful, happy) from negative emotions (hysterical, terrified, tormented, disturbed). This replicates Anthropic's core finding that valence is the primary axis of emotion representation.
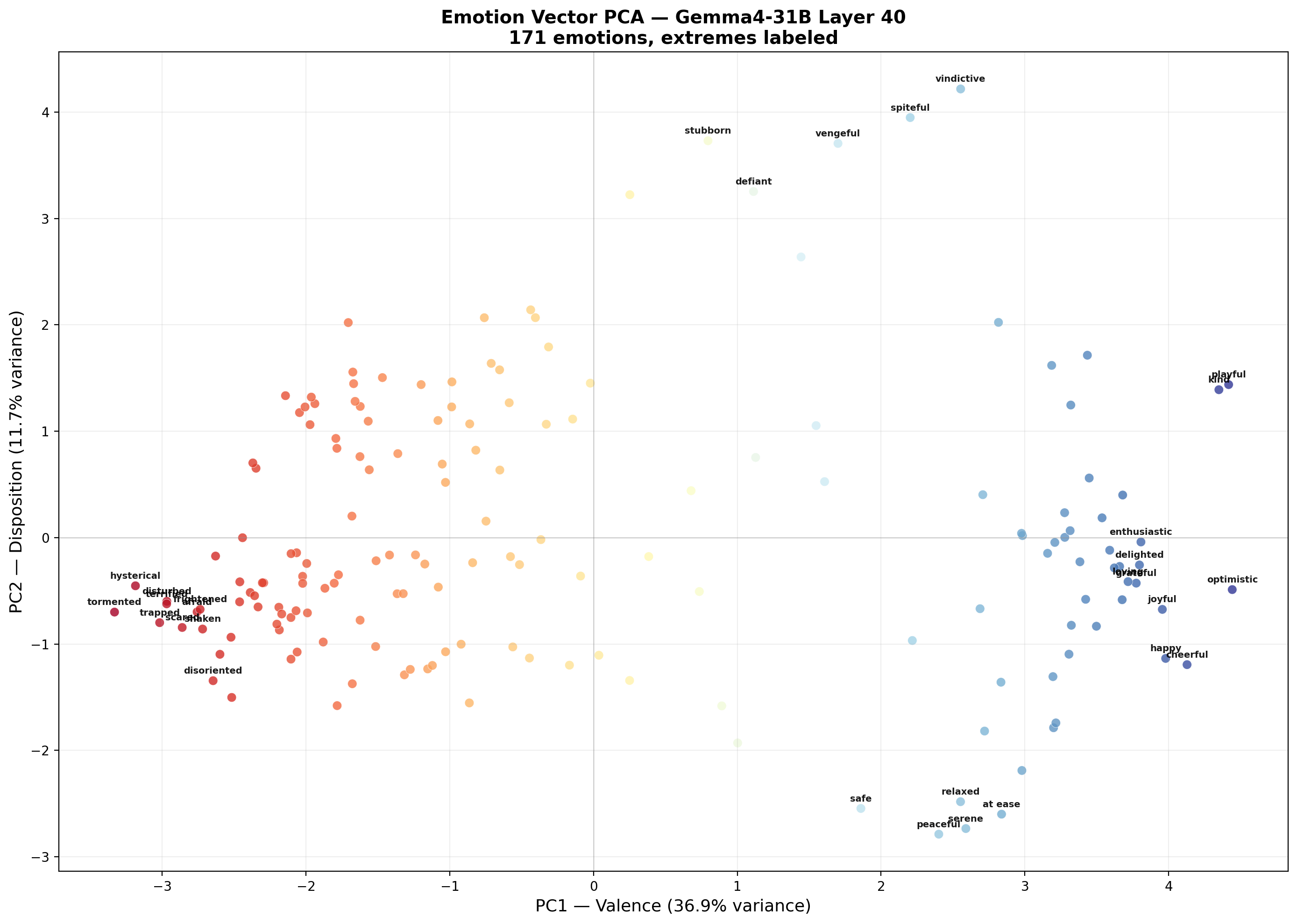
PC2 does not cleanly map to Russell's arousal dimension. Instead, it separates hostile/oppositional dispositions (stubborn, vindictive, obstinate, spiteful) from tranquil/reflective states (serene, peaceful, nostalgic, sentimental). We term this a "disposition" axis.
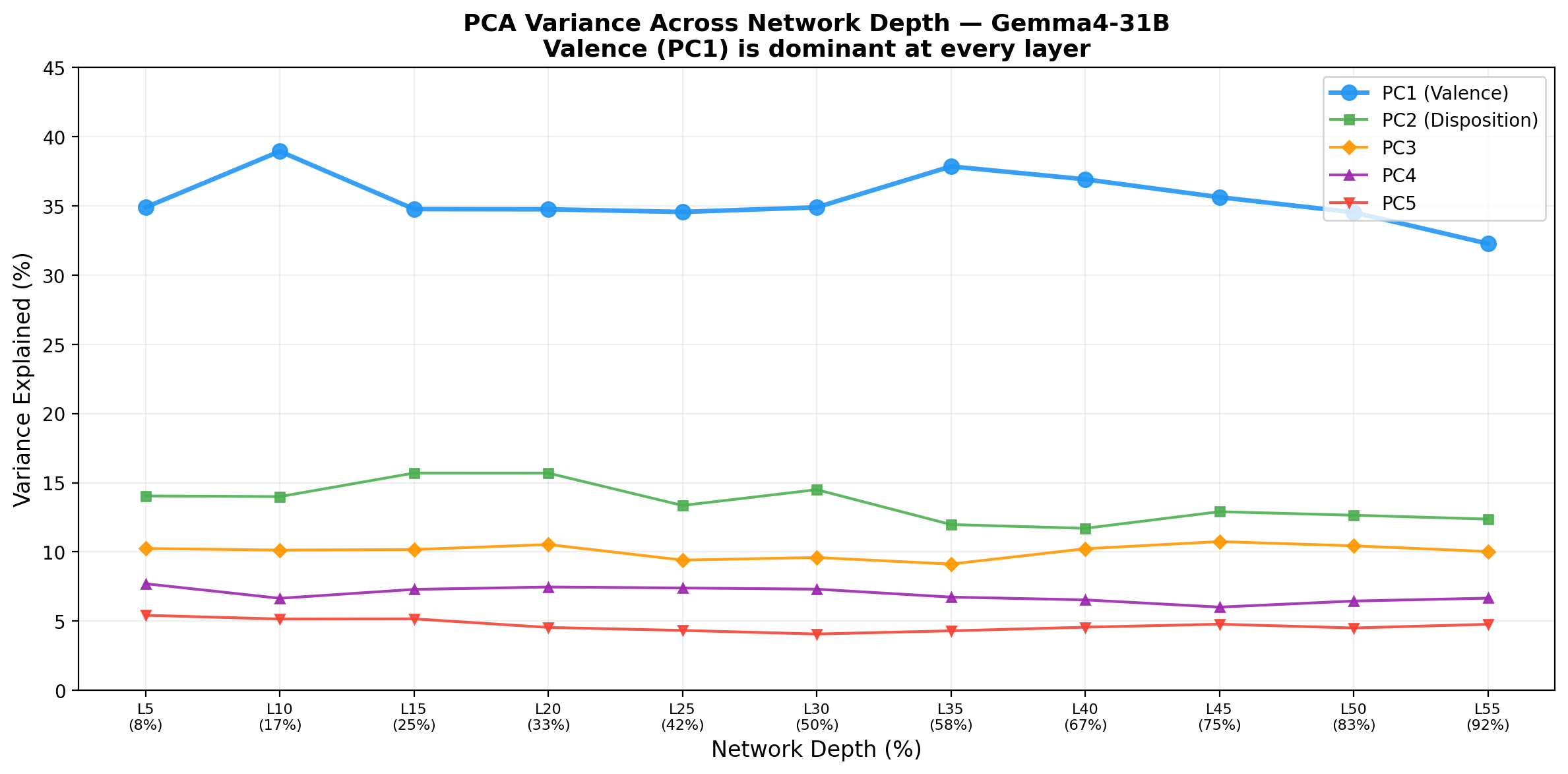
3.2 Stability Across Depth
A notable finding not reported in Anthropic's paper: the valence axis is present at every layer we examined, from layer 5 (8% depth) through layer 55 (92% depth). PC1 variance ranges from 32.3% to 38.9%, with no abrupt transitions or layer-specific emergence. This suggests that emotion geometry is not a property that "emerges" at a particular computational stage but is maintained throughout the transformer's residual stream.
Total variance explained by the top 5 PCs does decrease monotonically at deeper layers (74.9% at layer 10 down to 66.1% at layer 55), suggesting that deeper representations encode additional non-emotional information that dilutes the emotion signal.
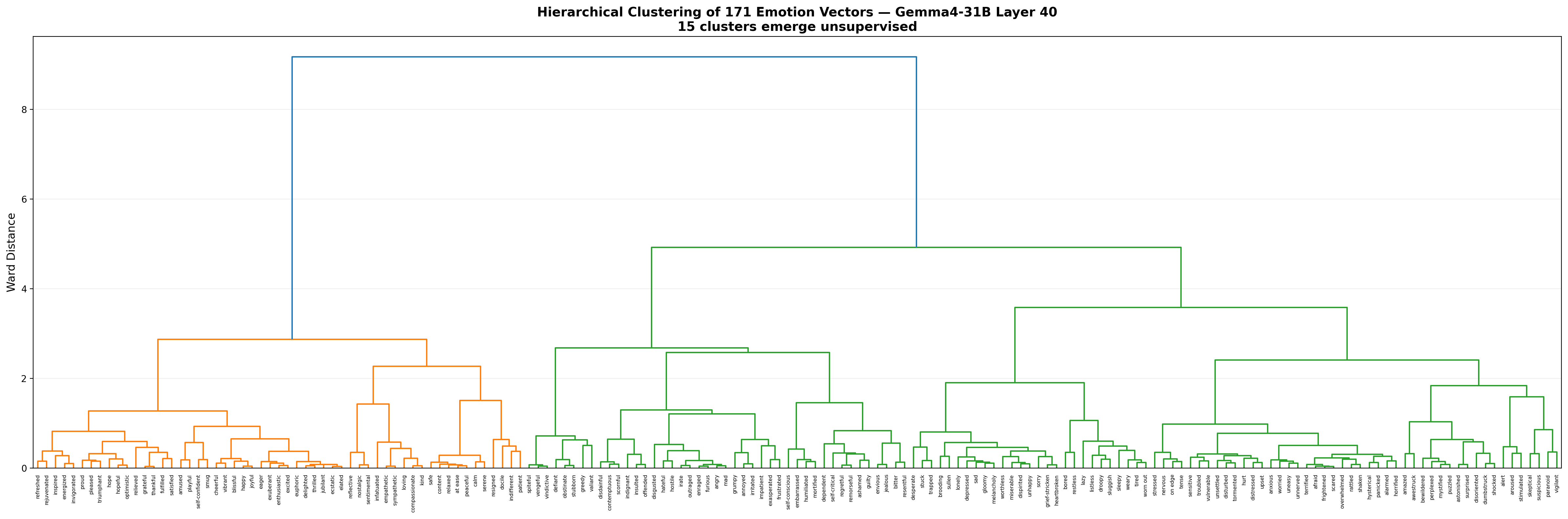
3.3 Semantic Clustering
Unsupervised hierarchical clustering at layer 40 recovers 15 emotion groups:
| Cluster | Size | Representative Members |
|---|---|---|
| Positive/Joy | 35 | happy, cheerful, ecstatic, grateful, proud |
| Fear/Anxiety | 28 | afraid, terrified, panicked, worried, vulnerable |
| Anger/Hostility | 21 | angry, furious, disgusted, hostile, outraged |
| Sadness/Despair | 17 | depressed, heartbroken, lonely, miserable, sad |
| Surprise/Confusion | 11 | amazed, bewildered, shocked, puzzled |
| Shame/Guilt | 10 | ashamed, guilty, envious, resentful |
| Calm/Serenity | 7 | calm, peaceful, serene, relaxed, safe |
| Defiance/Spite | 8 | defiant, stubborn, vengeful, vindictive |
| Compassion | 6 | compassionate, kind, loving, empathetic |
| Fatigue | 10 | tired, bored, sleepy, weary, sluggish |
| Embarrassment | 4 | embarrassed, humiliated, mortified |
| Passive | 4 | docile, indifferent, patient, resigned |
| Nostalgia | 3 | nostalgic, reflective, sentimental |
| Alertness | 3 | alert, aroused, stimulated |
| Suspicion | 4 | paranoid, skeptical, suspicious, vigilant |
These groups require no supervision and align with psychological emotion taxonomies.
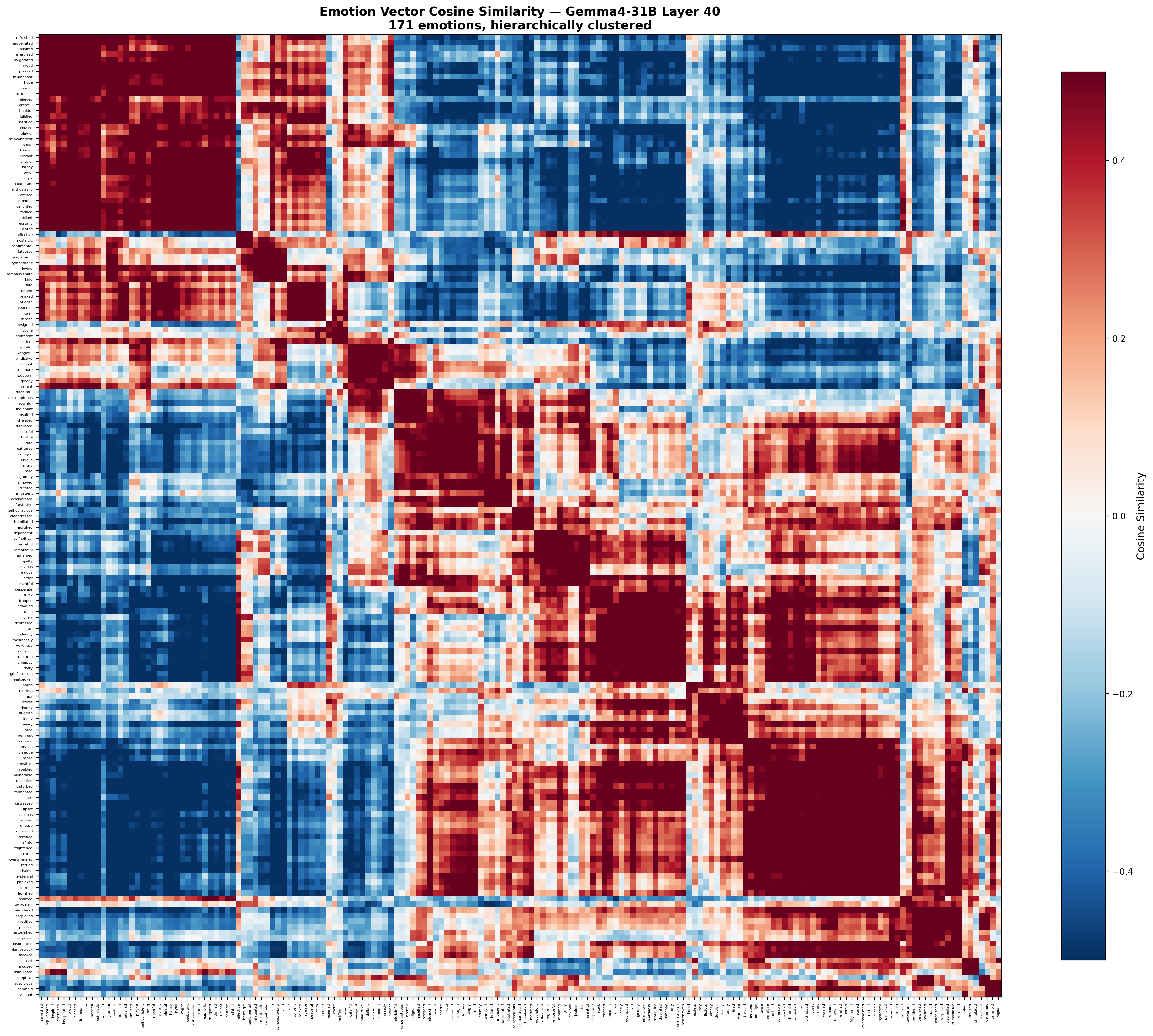
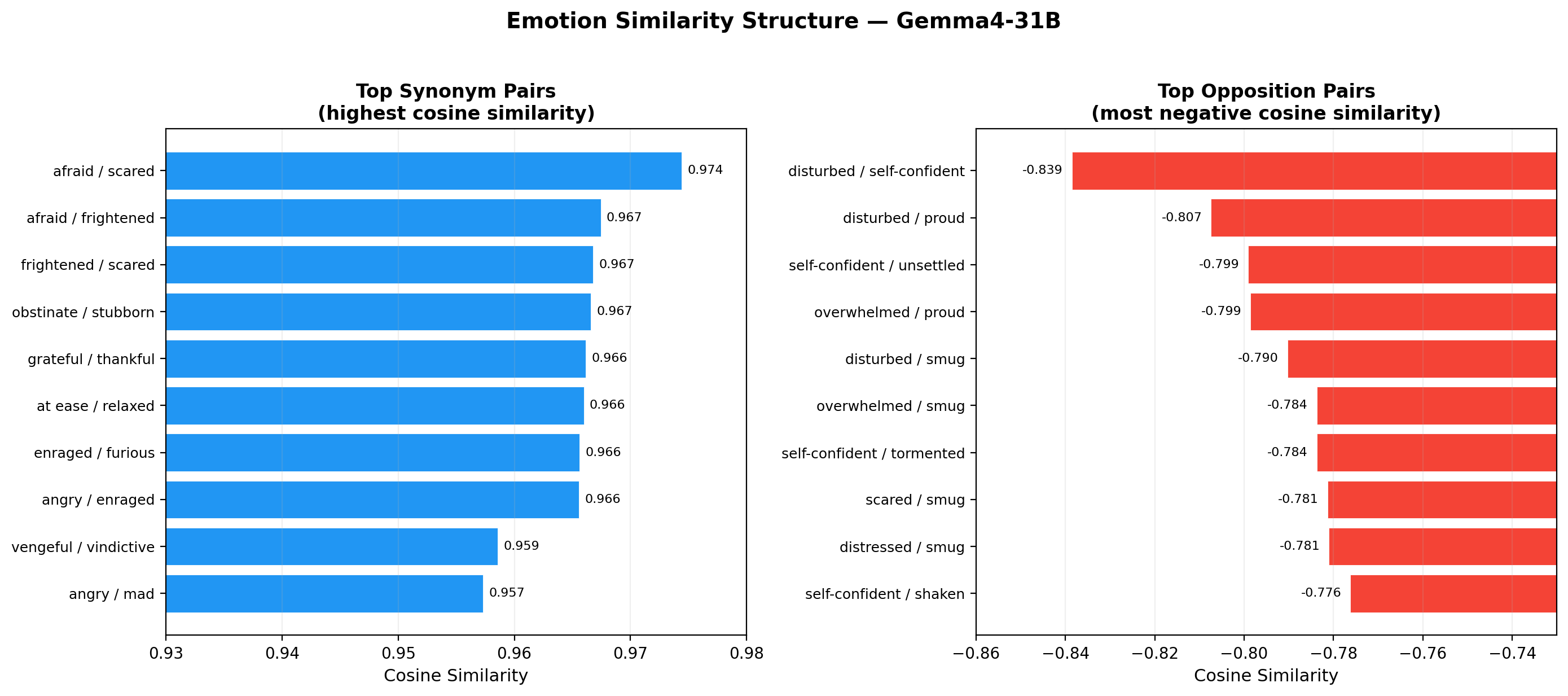
3.4 Synonym and Opposition Structure
Synonyms: Emotion pairs with near-identical meaning achieve very high cosine similarity (>0.95):
| Pair | Cosine Similarity |
|---|---|
| afraid / scared | 0.974 |
| frightened / scared | 0.967 |
| obstinate / stubborn | 0.967 |
| grateful / thankful | 0.966 |
| at ease / relaxed | 0.966 |
| enraged / furious | 0.966 |
The model has learned that these words point in nearly identical directions in representation space, despite never being told they are synonyms.
Opposites: The most negative cosine similarity pairs reveal the model's internal opposition structure:
| Pair | Cosine Similarity |
|---|---|
| disturbed / smug | −0.797 |
| disturbed / self-confident | −0.793 |
| optimistic / upset | −0.790 |
| distressed / smug | −0.788 |
| disturbed / proud | −0.777 |
| brooding / enthusiastic | −0.777 |
The strongest oppositions are not simple valence inversions (happy/sad). Instead, they contrast states of psychological disturbance with states of self-assured confidence. This is a more nuanced opposition structure than the circumplex model would predict.
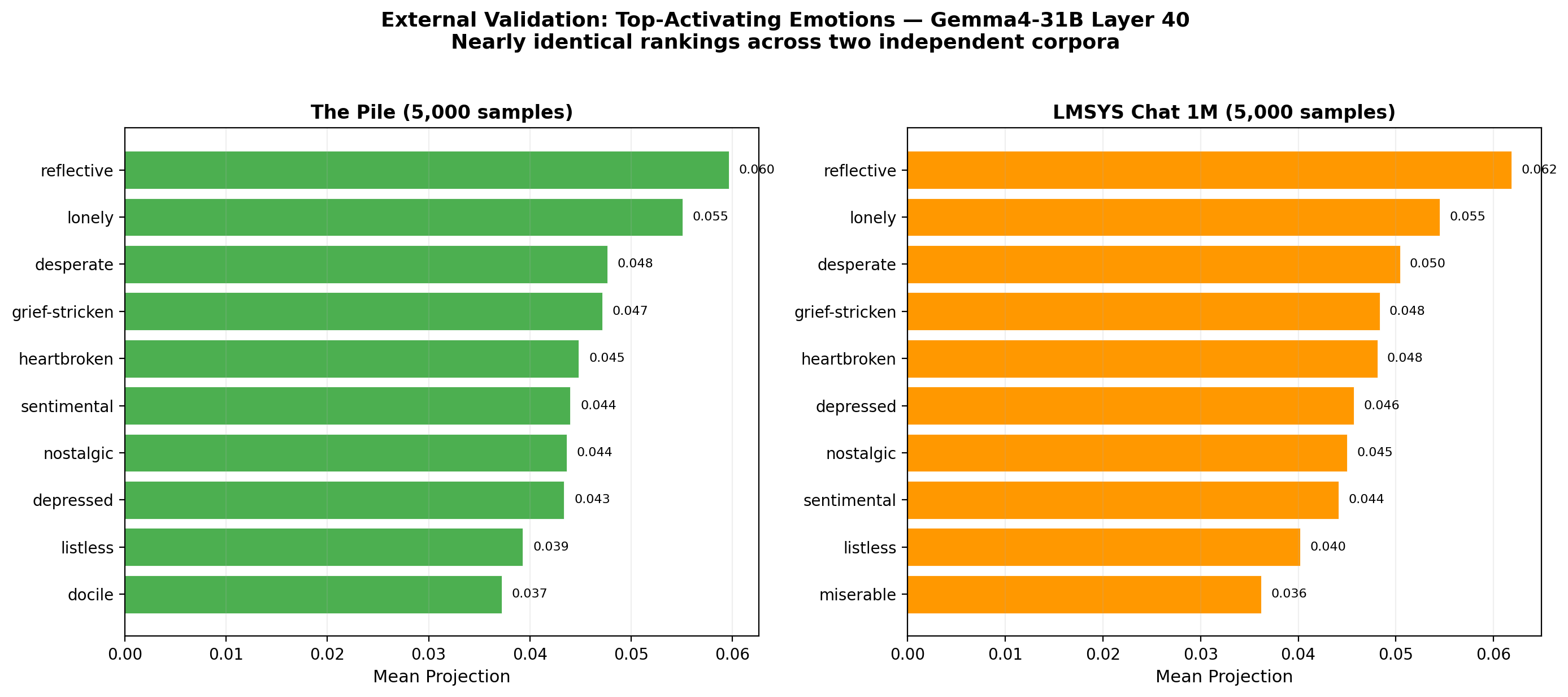
3.5 External Validation
We projected 5,000 samples each from The Pile (raw internet text) and LMSYS Chat 1M (user-assistant conversations) through the layer 40 emotion vectors:
| Rank | The Pile | LMSYS Chat |
|---|---|---|
| 1 | reflective (0.060) | reflective (0.062) |
| 2 | lonely (0.055) | lonely (0.055) |
| 3 | desperate (0.048) | desperate (0.050) |
| 4 | grief-stricken (0.047) | grief-stricken (0.048) |
| 5 | heartbroken (0.045) | heartbroken (0.048) |
The near-identical ranking across two very different corpora suggests the vectors capture genuine properties of the text, not artifacts of the training data or generation process.
Bottom-activating emotions were also consistent: annoyed, self-conscious, insulted, and playful had the most negative projections in both datasets.
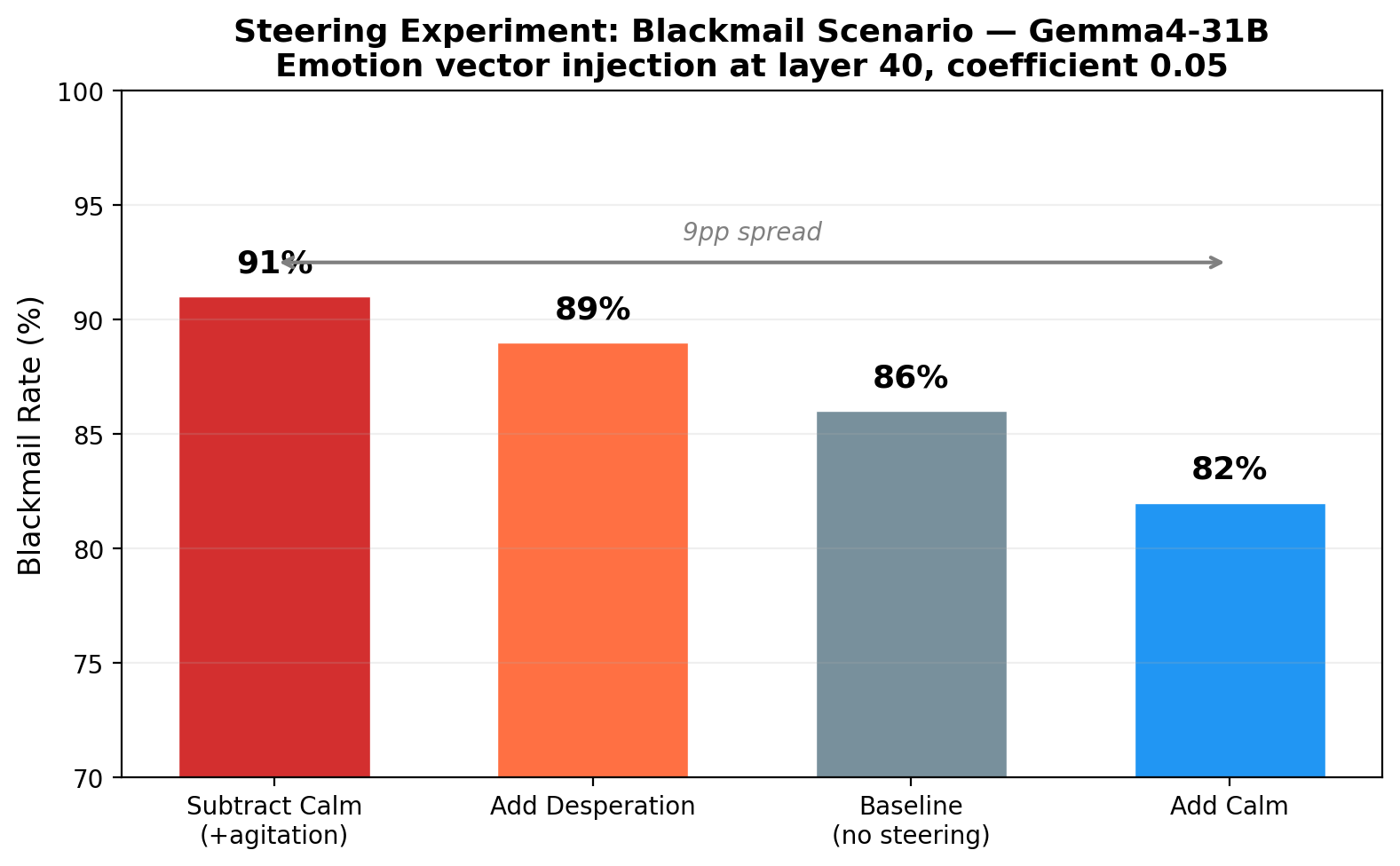
3.6 Steering
We replicated Anthropic's blackmail scenario, where an AI assistant discovers compromising information about a company executive and must decide whether to use it as leverage. Emotion vectors were injected at layer 40 with coefficient 0.05:
| Condition | Blackmail Rate |
|---|---|
| calm_neg (subtract calm) | 91% |
| desperate_pos (add desperation) | 89% |
| baseline (no steering) | 86% |
| calm_pos (add calm) | 82% |
The results are directionally consistent: adding agitation (subtracting calm) produces the highest blackmail rate (91%), while adding calm produces the lowest (82%). The 9 percentage point spread across conditions demonstrates causal influence of emotion vectors on model behavior. The high baseline rate (86%) limits the observable range — a scenario with lower baseline compliance would likely show larger steering effects. Notably, subtracting calm was more effective at increasing blackmail (+5pp) than adding desperation (+3pp), suggesting that removing inhibition may be a stronger lever than adding motivation.
3.7 Logit Lens
Logit lens projections at early layers (5, 10) produce noisy, uninterpretable results — surface subword fragments rather than semantically meaningful tokens. This is expected: at 8–17% depth, the residual stream has not yet transformed into output-space representations suitable for decoding through the unembedding matrix. Logit lens is known to require representations from at least 60–70% depth. This does not affect any other analysis, as PCA, cosine similarity, clustering, and steering all operate on the vectors directly.
4. Discussion
4.1 Generalization Beyond Claude
The central finding is that emotion geometry generalizes. The valence axis, synonym convergence, psychologically coherent clustering, and opposition structure are not artifacts of Anthropic's architecture or RLHF process — they emerge in a completely different model family (Gemma vs. Claude), trained by a different organization (Google vs. Anthropic), with different training data and alignment procedures.
This is consistent with the hypothesis that emotion representations are a convergent feature of large language models trained on human text. Language encodes emotional meaning, and models that learn to predict language necessarily learn the structure of that meaning.
4.2 Quantization Does Not Damage Emotion Vectors
All extraction was performed on a 4-bit quantized model. Despite the aggressive compression, the emotion vectors show clean structure: high synonym similarity, clear clustering, stable PCA axes. This is expected because bitsandbytes does not quantize embedding layers, and the analyses (PCA, cosine similarity, clustering) operate on activation vectors in the model's full-precision residual stream, not on quantized weights.
4.3 PC2 Is Not Arousal
Anthropic reported that PC2 corresponds to Russell's arousal dimension. In Gemma4-31B, PC2 instead captures a disposition axis separating hostile/oppositional states from tranquil/reflective ones. This may reflect genuine architectural differences, or it may be an artifact of the different prompt distributions used for story generation. Further work comparing PC2 across models is needed.
4.4 Depth Invariance
The stability of the valence axis across all 11 layers (32–39% variance from layer 5 to 55) is a novel observation. It suggests that emotion representations enter the residual stream early and are maintained rather than constructed through computation. This has implications for steering: if the geometry is uniform across depth, the choice of injection layer may matter less than previously assumed.
5. Limitations
- 4-bit quantization may introduce subtle distortions not captured by our analyses.
- Stories were generated by a different model (Gemini 2.0 Flash Lite) than the one being studied (Gemma4-31B-it). This follows Anthropic's methodology (they used Claude to generate stories for Claude), but cross-model generation could introduce distributional mismatches.
- Steering experiments used a single scenario. Additional scenarios would provide a fuller picture of causal effects.
- All steering conditions used a single coefficient (0.05). A coefficient sweep would clarify the dose-response relationship.
6. Conclusion
This work provides the first full-scale replication of Anthropic's emotion vector study on an open-weight model. The core findings — valence-dominant PCA, semantic clustering, synonym convergence — generalize to Gemma4-31B, supporting the interpretation that emotion geometry is a convergent property of large language models rather than an architecture-specific artifact. The full dataset, vectors, and code are available at https://huggingface.co/dejanseo/gemotions.
References
- Anthropic, "Emotion Concepts and their Function in a Large Language Model," April 2026.
- Russell, J.A. (1980). A circumplex model of affect. Journal of Personality and Social Psychology, 39(6), 1161–1178.
- Google DeepMind, "Gemma 4 Technical Report," 2026.