DEJAN AI SEO approach features a sophisticated multi-step process grounded in state-of-the-art machine learning and real data science.
Understanding & Control
Our AI SEO discovery process leans on the methods from the emerging field of Machine Learning called Mechanistic Interpretability. Its objective is to understand the inner workings of deep learning models. We start by systematic model probing and mine for brand and entity perception.
LLM and agent control is the ultimate goal of AI SEO. In machine learning this process is called Model Steering. Our objective is to utilize the knowledge gained from the model probing stage and form an AI SEO strategy designed to address any weaknesses in AI’s perception of our client’s products, services and brands.
Our Tech Stack
Our technology portfolio boasts rich features and innovation unmatched by any other AI SEO agency. Our algorithms, models, tools, workflows and pipelines are completely in-house, offering an unprecedented level of control, privacy and competitive advantage to our clients.
Tree Walker: Visualizes high/low entropy points in brand descriptions.
AI Rank: Tracks visibility (Frequency/Rank) across entities.
Query Fan-Out Generator: Automates the creation of search variations.
Query Deserves Grounding (QDG): Classifies queries by AI-trigger potential.
LinkBERT: Predicts optimal link placement.
Brand Relevance Tool: Calculates the probability score of Brand <-> Entity relevance.
Content Substance Classifier: Detects “thin” content that AI ignores.
The agency CEO, Dan Petrovic, is the world’s top authority in AI SEO and his work is widely recognized as a major force shaping the AI Search and Answer Engine optimization industry.
In 2013 Dan predicted we’d chat to Google in 2023 and started preparing for it.
What Is AI SEO?
AI SEO is search engine optimization adapted for a world where search results are generated, not listed. Traditional SEO focuses on ranking web pages in a list of blue links. AI SEO focuses on being selected, cited, and accurately represented when language models generate answers.
When a user asks Google, ChatGPT, Perplexity, or any AI assistant a question, the model:
Interprets the query intent
Retrieves relevant source material (grounding)
Synthesizes an answer from multiple sources
Selects which sources to cite
AI SEO optimizes for each stage of this process. The goal is not just visibility—it is accurate brand representation in AI-generated responses.
"Dan Petrovic made a super write up around Chrome’s latest embedding model with all the juicy details on his blog. Great read."
Jason Mayes Web AI Lead, Google Source: Google Web AI
AI SEO: Search Optimization for the Age of Language Models
AI SEO is the practice of optimizing brand visibility, entity associations, and content structure for discovery and citation by large language models (LLMs), AI assistants, and AI-powered search experiences. At DEJAN, we developed this discipline based on direct experimentation with language models, proprietary machine learning tools, and a methodology built from understanding how AI systems retrieve, evaluate, and synthesize information.
Why Traditional SEO Is No Longer Sufficient
The search paradigm has shifted. In 2013, DEJAN founder Dan Petrovic published “Conversations With Google,” predicting that search would evolve from query-response to conversational dialogue. That prediction has been realized.
The old model:
User types query → Google returns ranked list → User clicks link
The new model:
User asks question → AI retrieves and synthesizes sources → AI generates answer with optional citations
This shift creates new challenges:
Traditional SEO
AI SEO
Optimize for ranking position
Optimize for citation selection
Target keywords
Target entity associations
Build backlinks
Build grounding presence
Measure rankings
Measure AI visibility and sentiment
Control the snippet
Influence the synthesis
Brands that only optimize for traditional rankings may be invisible in AI-generated answers, or worse—misrepresented by models drawing on outdated or inaccurate sources.
The DEJAN AI SEO Methodology
Our methodology is built on direct experimentation with language models. DEJAN founder Dan Petrovic trained a language model from scratch—not fine-tuning an existing model, but building from raw noise with a custom tokenizer and masked language modeling. This foundational work informs every aspect of our approach.
Phase 1: Brand Knowledge Analysis
We begin by understanding what language models currently believe about your brand. This is not speculation—it is measurable.
Token Probability Analysis examines how models complete sentences about your brand. When a model generates text, each word (token) is selected based on probability distributions. We analyze these probabilities to determine:
How strongly your brand is associated with key entities
Where associations are weak (high entropy) or strong (low entropy)
What the model “wants” to say about your brand versus what you want it to say
Tree Walker is our proprietary algorithm for exploring these probability distributions. It maps the branching paths of possible completions, revealing where models are confident about your brand and where they are uncertain or incorrect.
Brand Relevance Scoring provides an exact probability score for the question: “Is this brand relevant for this entity?” This quantifies your brand’s position in the model’s knowledge.
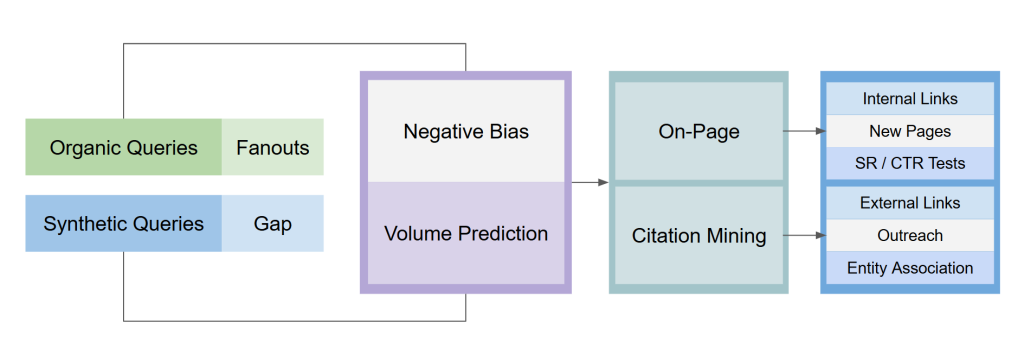
Phase 2: Entity and Association Mapping
Language models understand the world through entities and their relationships. We map:
Core entities: Your brand, products, services, and key people
Associated entities: Topics, categories, competitors, and related concepts
Entity gaps: Associations that should exist but are weak or missing
Negative associations: Incorrect or undesirable entity relationships
This mapping uses our Query Fan-Out Model, available on Hugging Face, which generates expanded query variations to probe the full scope of model associations.
Phase 3: Citation Mining
When AI systems generate grounded answers, they retrieve and cite sources. Citation Mining is our process for discovering which sources models actually select.
Query multiple AI systems (Google, OpenAI, others)
Parse responses to extract cited sources
Calculate confidence scores for each citation
Map citations to specific sentences in the generated output
This produces actionable data:
Top domains appearing in citations for your topic space
Exact URLs being cited
Confidence scores indicating citation strength
Position data showing where in source content the grounding occurs
Critically, we can also see what the model retrieved but chose not to cite. This reveals Selection Rate Optimization opportunities—content that is being seen but not selected.
Phase 4: Grounding Prediction
Not every query triggers search grounding. Asking “what is 2+2” will not cause the model to search. Asking “what are the best project management tools in 2026” will.
Our Query Deserves Grounding models predict whether a query will trigger grounding behavior in Google and OpenAI systems. This prevents wasted optimization effort on queries that will never retrieve external sources.
Phase 5: Optimization Execution
With complete diagnostic data, we execute targeted optimization:
On-Page Optimization
Content restructuring for entity clarity
Semantic completeness improvements
Chunk optimization for retrieval (using our Chunk Norris tool)
Entity association strengthening within owned content
Off-Page Optimization
Citation opportunity targeting based on mining data
Entity association building on high-authority sources
Selection rate improvement for content that is retrieved but not cited
Strategic presence on sources models prefer to cite
Link Optimization
LinkBERT predicts natural linking opportunities within text
Penguin tool ensures link patterns avoid penalty triggers
Focus on entity-reinforcing links, not just authority signals
Phase 6: AI Visibility Tracking
Traditional rank tracking measures position in a list. AI visibility tracking measures presence in generated answers.
AI Rank tracks your brand’s visibility across AI systems over time. AI Flux measures volatility in AI search results, analogous to our Algoroo tool for traditional search.
We track:
Citation frequency across query sets
Brand mention accuracy and sentiment
Entity association strength changes
Competitive share of AI visibility
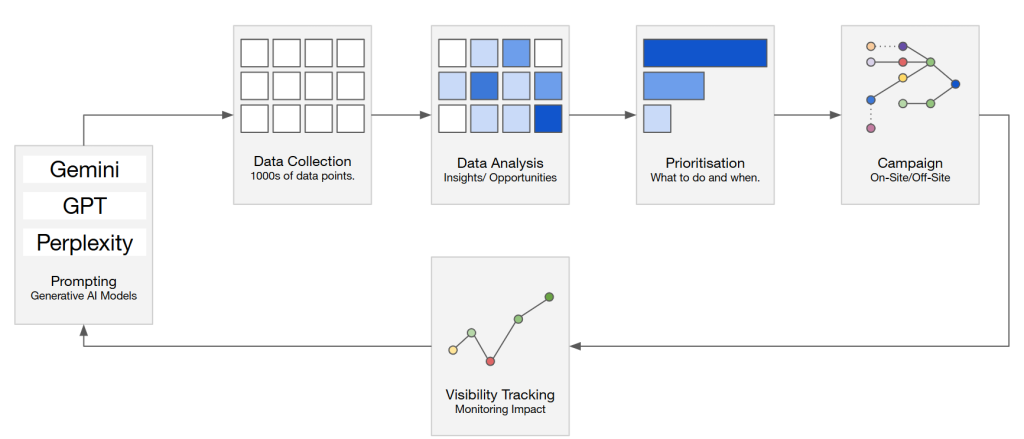
Dejan AI Visibility Optimization Cycle
Proprietary Tools and Models
DEJAN has developed an extensive suite of machine learning tools for AI SEO. These are not wrappers around third-party APIs—they are purpose-built systems based on original research.
Analysis and Diagnostic Tools
Tool
Function
Tree Walker
Maps token probability distributions to find high and low entropy completions in model output
Brand Relevance Tool
Calculates exact probability scores for brand-entity relevance
Citation Mining Tool
Harvests citations from AI responses with confidence scoring and source attribution
Query Deserves Grounding (Google)
Predicts whether queries will trigger search grounding in Google AI
Query Deserves Grounding (OpenAI)
Predicts whether queries will trigger search grounding in OpenAI systems
Gemini Token Probabilities
Analyzes token-level probability data from Google’s Gemini models
Brand AI Sentiment
Measures sentiment polarity in AI-generated brand mentions
Query and Content Tools
Tool
Function
Query Fan-Out Generator
Expands seed queries into comprehensive query sets for testing
Query Fan-Out Model (Hugging Face)
Open model for generating query variations at scale
Universal Query Classification
Classifies query intent using machine learning
Oxy (Query Gap)
Identifies synthetic queries and gaps from Search Console data
Content Substance Classifier
Evaluates content depth and substance
AI Content Detection
Identifies AI-generated content
Link and Entity Tools
Tool
Function
LinkBERT
Predicts natural internal linking opportunities within text
Penguin
Link optimization tool for penalty avoidance
Google Entity Search
Explores Google’s entity understanding
Chunk Norris
Optimizes content chunking for retrieval systems
Tracking and Monitoring Tools
Tool
Function
AI Rank
Tracks brand visibility in AI-generated responses
AI Flux
Measures volatility in AI search results
Algoroo
Monitors traditional search volatility
Text Sentiment
General sentiment analysis
Machine Learning Infrastructure
Our workflow incorporates:
Facebook Prophet for time series forecasting
Logistic Regression for classification tasks
mixedbread-ai embedding model for semantic similarity
FAISS (Facebook AI Similarity Search) for efficient vector search
Selection Rate Optimization
Selection Rate Optimization is a concept developed through our citation mining research. It addresses a specific problem: your content appears in the model’s retrieved sources, but is not selected for citation in the final response.
When AI systems ground their responses, they often retrieve more sources than they cite. The model evaluates retrieved content and selects what to include. Selection Rate Optimization improves the likelihood that your content, once retrieved, is actually cited.
Improving selection rate is often more efficient than pursuing new citation opportunities—you are optimizing content the model already knows about.
We were given our very own bespoke internal link recommendation engine that leverages world-class language models and data science. It's one thing to theorize about the potential of machine learning in SEO, but it's entirely another to witness it first-hand. It changed my perspective on what’s possible in enterprise SEO.
Scott Schulfer Senior SEO Manager Zendesk
Who Needs AI SEO
AI SEO is essential for:
Brands competing in informational queries When users ask AI assistants for recommendations, comparisons, or explanations, will your brand be mentioned? If competitors are cited and you are not, you lose visibility in a channel that is rapidly growing.
Companies in complex or technical industries Language models struggle with nuance. If your industry involves technical distinctions, regulatory specifics, or complex product differentiation, you need to ensure models represent you accurately.
Businesses affected by AI-generated misinformation Models can perpetuate outdated information, competitor narratives, or simply incorrect claims. AI SEO includes identifying and correcting these misrepresentations.
Organizations seeking to own entity definitions If you created a methodology, coined a term, or developed a unique process, AI SEO ensures models attribute these to you rather than generic descriptions or competitors.
Why DEJAN
Practitioner-built methodology: Our approach is not derived from guesswork about how AI works. Dan Petrovic trained a language model from scratch to understand the mechanics firsthand.
Decade of foresight: Dan’s 2013 article “Conversations With Google” predicted the conversational search paradigm now realized. This is not trend-chasing—it is long-term strategic development.
Proprietary tooling: The tools listed above are built and maintained by DEJAN. They are not repackaged third-party services.
Open research contribution: We publish models on Hugging Face and provide free tools for the SEO community. This reflects genuine expertise, not gatekeeping.
AI is SEO: We do not treat this as a separate discipline or use invented acronyms. Search optimization now requires understanding language models. That understanding is core to what we do.
AI SEO Glossary
Definitions of key terms used in AI SEO practice:
Grounding The process by which a language model retrieves external information to support its response. A “grounded” response cites real sources rather than generating from training data alone.
Token The basic unit of text that language models process. Tokens may be words, parts of words, or punctuation. Token probabilities indicate how likely the model considers each possible next token.
Entropy A measure of uncertainty in model output. High entropy means the model is uncertain between many possible completions. Low entropy means the model is confident about what comes next.
Citation Mining The process of systematically querying AI systems and extracting which sources they cite, enabling analysis of citation patterns and opportunities.
Selection Rate The percentage of times content is cited when it is retrieved by an AI system. Low selection rate indicates content is seen but not chosen.
Query Fan-Out Expanding a single query into many variations to comprehensively test model behavior across phrasings and intents.
Entity Association The strength of connection between two entities in a model’s understanding. Strong entity associations cause consistent co-occurrence in model outputs.
Query Deserves Grounding A prediction of whether a given query will cause an AI system to retrieve external sources or answer from training data alone.
Masked Language Modeling A training technique where the model learns to predict hidden portions of text. Used in training models like BERT.
Double Descent The phenomenon where very large models, contrary to earlier assumptions, continue improving rather than overfitting. This discovery enabled modern large language models.
Dan Petrovic, an academic and consultant on SEO and generative AI, said Google’s size, expertise and massive trove of search data gave it a massive advantage, but that Gemini 3 Pro would probably be a more expensive model to run. — Tim Biggs, The Sydney Morning Herald
AI search has fundamentally changed how people discover information, and DEJAN has built the world’s most sophisticated system for optimizing brand visibility in this new landscape.
Unlike traditional SEO agencies adapting legacy tactics, DEJAN developed proprietary machine learning models, mechanistic interpretability frameworks, and production-grade tools specifically designed to influence how AI platforms select, cite, and represent brands. Led by Dan Petrovic—Adjunct Lecturer at Griffith University and architect of the industry-defining DEJAN Methodology—this Australian agency combines 20+ years of SEO expertise with cutting-edge AI research to help Fortune 500 companies and innovative brands dominate visibility across ChatGPT, Google AI Overviews, Gemini, Perplexity, and emerging AI agents.
This isn’t about using AI to do traditional SEO. This is about optimizing content FOR AI platforms—a fundamentally different discipline that requires understanding how large language models construct knowledge graphs, select sources through retrieval-augmented generation, and build brand associations in their neural networks. DEJAN’s approach transforms reactive rank tracking into proactive perception engineering, using custom-trained models that decode AI decision-making at the token level.
Why GPT-5 made SEO irreplaceable and validated DEJAN’s approach
When OpenAI released GPT-5 in 2025, they made a strategic decision that vindicated everything DEJAN had been building: the model was deliberately trained to be intelligent, not knowledgeable. Unlike previous generations that embedded vast amounts of world knowledge in their weights, GPT-5’s architecture focuses on raw reasoning capability while relying almost entirely on external grounding—real-time web search and content retrieval—to provide factual information. Without this grounding layer, GPT-5 is virtually useless as an information source.
This design philosophy fundamentally validates traditional SEO’s continued relevance while simultaneously demanding new approaches. Dan Petrovic’s analysis revealed that OpenAI made an executive decision to focus on intelligence and leave information retrieval to search engines, creating an unprecedented opportunity: AI models need high-quality, discoverable, citable content more than ever before. The grounding layer that feeds GPT-5, Google’s Gemini, and other AI platforms depends entirely on content being properly optimized for machine retrieval and citation.
DEJAN discovered through extensive reverse engineering that these AI systems operate on a dual-layer architecture. The Agentic Layer makes strategic decisions about which queries need grounding, how to fan out queries across multiple perspectives, and which retrieved sources to select. The Interpretative Layer then synthesizes chosen sources into natural language responses. Traditional SEO only influenced the presentation layer, but AI SEO must operate at the agentic level—influencing which sources AI systems retrieve and trust before users ever see results.
Through analysis of over 230,000 rank tracking datapoints across multiple AI platforms, DEJAN identified that 91-96% of ChatGPT queries and 100% of Gemini queries require some form of grounding. This massive dependence on real-time content retrieval means that being discoverable, parsable, and authoritative has never been more critical. But it also revealed something transformative: AI visibility isn’t about ranking #1 for keywords anymore. It’s about establishing semantic authority in knowledge graphs and building strong brand-to-entity associations in AI models’ understanding of the world.
The DEJAN Methodology: measuring and influencing brand perception in AI systems
DEJAN developed the first comprehensive framework for understanding how AI platforms actually perceive and represent brands—moving beyond guesswork to scientifically measure brand associations and systematically strengthen them. This methodology, published and presented at major industry conferences including SEO Week 2025, introduces bidirectional prompting as a fundamental measurement technique.
The framework queries AI models in two directions simultaneously. Brand-to-Entity prompts ask “List ten things you associate with [Brand Name],” revealing what concepts, attributes, and characteristics the AI has linked to a brand in its neural network. Entity-to-Brand prompts reverse the question: “List ten brands you associate with [Keyword/Service],” exposing competitive positioning and whether the brand appears when users ask about relevant topics. By running these queries systematically across multiple LLMs—GPT-4o, Gemini, Claude—and tracking responses over time, DEJAN creates longitudinal brand perception profiles that function like Bloomberg terminals for AI visibility.
Each response generates structured data that DEJAN’s systems analyze through multiple lenses. Frequency analysis counts how often brand-entity associations appear across repeated queries. Average rank calculations track positioning within AI response lists (appearing third versus tenth matters significantly). Weighted scoring combines frequency with inverse rank to produce authority scores analogous to PageRank. Time series analysis reveals perception evolution, seasonal patterns, and the impact of content campaigns on AI understanding. Network visualization treats brand-entity relationships as knowledge graphs, applying eigenvector centrality and PageRank algorithms to identify the most influential brands in semantic spaces.
The AIRank tool (airank.dejan.ai) operationalizes this methodology as a free, public platform that democratizes AI visibility tracking. With over 2,000 active users tracking 10,000 entities, it represents the industry’s first comprehensive answer to the question “How do AI models see my brand?” The platform automates daily or weekly probing of AI systems, normalizes entity mentions through canonicalization algorithms, and visualizes brand association networks over time. Unlike traditional rank trackers that show where pages appear in search results, AIRank reveals the invisible layer of AI perception that determines whether brands get mentioned at all—and in what context.
But measurement is only the beginning. DEJAN’s most powerful innovation is Tree Walker analysis, a mechanistic interpretability technique that deconstructs AI decision-making at the token level. When language models generate text, they choose each word based on probability distributions—at every junction, multiple paths branch off with varying confidence levels. Tree Walker walks this entire probability tree, revealing not just what AI models say about a brand, but what they almost said, where they’re confident versus uncertain, and which semantic pathways are weak.
Consider a case study from DEJAN’s work with a tours and activities brand. Tree Walker analysis showed 100% confidence when connecting the brand to “tours,” but dramatically lower confidence when the model tried to link “tours AND activities” together. This precision diagnosis—impossible with traditional analytics—revealed exactly which neural pathways needed reinforcement. DEJAN created targeted content strengthening the “activities” association, effectively teaching the AI model to be more confident about that brand positioning. This level of optimization, operating at the level of individual tokens and probability distributions, represents the frontier of AI SEO.
Citation mining and selection rate: the new metrics for AI visibility
Traditional SEO measured success through rankings and organic traffic. AI SEO requires fundamentally different KPIs because users don’t see ten blue links—they see synthesized answers with inline citations or no visible sources at all. DEJAN built Citation Mining, a proprietary pipeline that systematically tracks which domains and URLs AI systems actually cite when generating responses.
The system queries both OpenAI (GPT-4o) and Google (Gemini) models with branded prompts across target entities, parsing every response to extract cited sources. Early testing with 60 prompts across six AI SEO-related entities generated 141 GPT citations and 400 Gemini citations, revealing dramatic differences in source preference between platforms. For Google-related queries, developers.google.com dominated with 21 citations, while for AI SEO expertise, semrush.com and digitalmarketinginstitute.com led citation frequency on Gemini. These patterns expose which content formats, domain authorities, and content structures different AI systems trust.
Gemini citations include confidence scores ranging from 0.7 to 0.98, providing quantifiable trust metrics. High-confidence citations (0.95+) indicate sources the model considers authoritative and reliable. Lower-confidence citations suggest the model is less certain about information quality. Tracking these confidence patterns over time reveals whether optimization efforts are genuinely building AI trust or merely achieving surface-level mentions.
Building on citation data, DEJAN formalized Selection Rate (SR) as the AI-native equivalent of click-through rate. The metric calculates how frequently AI systems select and incorporate a specific source from the total set of retrieved results: SR = (Number of selections / Total available results) × 100. This seemingly simple ratio captures something profound about AI attention economics. When Gemini or ChatGPT retrieve 20-50 results through their grounding process, which sources actually influence the final answer? Which get ignored despite being retrieved?
Selection Rate analysis revealed that primary bias—the model’s internal relevance perception based on training data—dominates selection decisions. A brand with strong presence in the model’s foundational training will have inherently higher selection rates even with mediocre on-page optimization. Conversely, brands with weak model training presence struggle to get selected even when retrieved. This insight fundamentally reframes AI SEO strategy: short-term optimization targets secondary biases (snippet quality, URL structure, recency), but long-term strategy must influence model training through consistent authoritative presence across the web.
Tree Walker integration makes Selection Rate predictive rather than merely descriptive. By analyzing token-level confidence in brand associations, DEJAN can estimate selection likelihood before running expensive prompt testing campaigns. High uncertainty tokens in brand associations signal low primary bias, predicting lower Selection Rates. This predictive capability allows strategic prioritization: invest heavily in strengthening weak brand associations that limit Selection Rate, while leveraging strong existing associations more efficiently.
Query fanout and comprehensive topical authority
Google’s internal research revealed that modern search systems don’t process user queries as single units—they fan them out into multiple parallel sub-queries to capture complex, multi-faceted intent. A business decision-maker searching for “enterprise CRM solutions” implicitly needs information about pricing models, integration capabilities, security compliance, user experience, vendor stability, and implementation timelines. DEJAN replicated Google’s query fanout system by training production-grade models that generate these intelligent query variations at scale.
The technical implementation follows a rigorous two-step process validated against Google Research papers. First, a custom Gemma 3 1B architecture extracts semantic features from the query. Second, the system traverses vector embedding space, generating intermediate points between the query and relevant document embeddings. Third, a fine-tuned multilingual T5 model decodes these vector points back into natural language queries. The result: a single query like “AI SEO” expands into 70+ contextually relevant variations including “ai powered search engine optimization,” “artificial intelligence for seo strategy,” “ai seo tools comparison,” “chatgpt search optimization techniques.”
Training this system required extraordinary scale: 15 million training samples processed over 70 hours across five training iterations. DEJAN combined Google Search Console data (query-URL pairs showing actual user behavior) with synthetic data generated through systematic vector space exploration. The model learned eight distinct variation types: equivalent queries (alternative phrasings), follow-up queries (logical next questions), generalization queries (broader versions), canonicalization (standardized forms), specification queries (more detailed angles), clarification queries (intent disambiguation), entailment queries (implied consequences), and language translations.
The production tool offers two modes. High Effort mode uses stochastic sampling with varied temperature and top-p parameters to generate up to 200 unique candidates with maximum diversity, ideal for comprehensive content strategy development. Quick Fanout mode employs beam search with diversity penalties to generate 10 deterministic expansions rapidly, perfect for real-time analysis. Both modes include duplicate suppression and relevance filtering to ensure quality.
But generating queries is insufficient without understanding their search potential. DEJAN developed a Query Demand Estimator (QDE) using a fine-tuned mDeBERTa-v3-base transformer model that predicts search volume ranges for generated queries. The model classifies queries into 12 volume buckets ranging from 51-100 searches to 200,001+ monthly searches. With 23.31% exact match accuracy and 54.80% combined accuracy (exact plus adjacent bucket), the system dramatically outperforms random chance (approximately 9% for 11 classes) and enables data-driven prioritization of which fanout queries merit content investment.
This fanout-to-volume pipeline transforms AI SEO strategy from intuition-driven to algorithmic. DEJAN can map the complete constellation of queries around any topic, predict which variations drive meaningful search volume, classify intent for each variation, and create a comprehensive blueprint for building topical authority. A single page optimized to answer all major fanout variations becomes the definitive source AI models cite because it addresses query diversity that individual keyword-focused pages cannot match.
Platform-specific optimization: how different AI systems actually work
DEJAN’s competitive advantage lies in reverse engineering the actual mechanisms different AI platforms use to select and cite sources—not speculation, but empirical discovery through systematic testing and analysis. This work revealed that optimization strategies must account for fundamental architectural differences across platforms.
Google Gemini and AI Overviews: the snippet is everything
Through an ingenious reverse-engineering technique, DEJAN intercepted the exact grounding data Google sends to Gemini during retrieval-augmented generation. The discovery was startling: Gemini sees only shallow context—query, URL, title, and a short snippet (typically 150-300 characters). It doesn’t access full page content during initial grounding. From these limited elements, Gemini generates its own lightweight summarization described as “additional_info,” which Dan Petrovic characterized as “Google’s quantized impression of the brand.”
This shallow grounding architecture means the first 150 words of any page carry disproportionate weight. If the snippet extracted from that opening doesn’t contain a complete, contextually rich answer, the page will fail to influence AI output even if it ranks highly in traditional search. DEJAN’s optimization for Gemini prioritizes inverted pyramid content structure: complete answer upfront, supporting details second, background context last. Snippet engineering—optimizing title tags, meta descriptions, and opening paragraphs specifically for machine extraction—becomes paramount.
Gemini’s operational loop follows a verification-first principle. The model analyzes user queries to determine whether external verification is needed, invokes Google Search as a tool when confidence is low, retrieves grounding context, then synthesizes responses. Dynamic retrieval operates on confidence thresholds (default 0.3 on a 0-1 scale): if Gemini’s internal knowledge confidence exceeds this threshold, it skips grounding entirely, risking hallucinations. If confidence is low, it grounds responses in search results. DEJAN trained a replica grounding classifier by analyzing 10,000+ Gemini prompts, creating a production-ready model that predicts which queries will trigger grounding—allowing strategic optimization focus on grounded queries where SEO can actually influence outcomes.
ChatGPT and GPT-5: intelligence without knowledge
OpenAI’s GPT-5 architecture revealed a revolutionary approach: training models to be intelligent processors rather than knowledge repositories. The model’s weights contain dramatically less factual information than smaller predecessors, instead optimizing for logical reasoning, tool usage, and information synthesis. GPT-5 implements a mixture-of-models architecture with dynamic routing between a fast model for simple queries and a deep reasoning model for complex tasks, integrated with SearchGPT for native web search capability.
The implications for SEO are profound. GPT-5 achieves 45% fewer factual errors when using web search, and 80% fewer errors than reasoning-only modes. This dependency on external grounding means traditional SEO fundamentals—crawlability, indexability, structured content, authoritative signals—directly determine GPT-5 visibility. Content must be discoverable by search crawlers, easily parsable by AI browse tools, and formatted for clear information extraction.
Optimization for ChatGPT focuses on citation-worthiness: creating content structured as definitive sources AI models confidently reference. Clear hierarchical organization with semantic HTML signals helps GPT-5’s parsing algorithms extract information accurately. Since SearchGPT uses Bing’s index rather than Google’s, Bing SEO optimization becomes strategically important for ChatGPT visibility—a factor many traditional SEO practitioners overlook.
Perplexity, Claude, and the multi-model ecosystem
Perplexity distinguishes itself through transparency and multi-source verification, providing explicit citations with every answer and allowing users to select underlying models (GPT-4, Claude, Gemini). Optimization requires becoming a cited authoritative source through comprehensive, well-researched content with clear attribution signals. Perplexity prioritizes fresh, real-time information and cross-references multiple AI models, making consistent visibility across platforms crucial rather than optimizing for a single system.
Claude (Anthropic) offers 200K+ token context windows, enabling entirely different content strategies. Long-form, comprehensive content that would overwhelm smaller models becomes an asset with Claude. The platform’s safety-first approach emphasizes reliable, accurate information over speed, rewarding careful research and professional tone. Claude powers sophisticated AI agents like Manus, which require machine-readable structure, APIs, and automation-friendly interfaces rather than human-optimized visual layouts.
The proprietary technology stack powering DEJAN’s AI SEO
DEJAN’s technical sophistication extends far beyond strategic consulting—the agency has built production-grade machine learning infrastructure that rivals specialized AI companies. The core philosophy: “small, dedicated models trained on highest quality data, each doing one thing really well” rather than general-purpose tools attempting everything mediocrely.
Custom machine learning models in production
AI Content Detection Model uses fine-tuned DeBERTa-v3 for binary classification of organic versus AI-generated text, trained on 20 million sentences with class-weighted optimization for imbalanced datasets. The hybrid approach combines deep learning predictions with rule-based heuristics to handle edge cases from new AI models, achieving 68.1% detection confidence on difficult cases—a dramatic improvement from the 20.8% baseline.
LinkBERT predicts natural link placement in web content through fine-tuned BERT variants (mini and XL sizes). Client testimonials describe it as “our very own bespoke internal link recommendation engine that leverages world-class language models and data science”—technology that changed perspectives on what’s possible in enterprise SEO. The model suggests anchor text, evaluates link naturalness, and identifies spam or inorganic SEO tactics based on learned patterns from high-quality organic link data.
Query Intent Classifier family includes multiple ALBERT-based variants (Intent-XS through Intent-XL) handling multi-label classification across customizable taxonomies. Special token formats ([QUERY], [LABEL_NAME], [LABEL_DESCRIPTION]) enable threshold-based assignment at scale, deployed in automated pipelines processing thousands to millions of queries for enterprise clients.
Query Form Quality Classifier achieved 80% accuracy identifying well-formed versus ambiguous queries—a 10% improvement over Google’s baseline LSTM classifier by using ALBERT architecture. This production-deployed model identifies query expansion candidates through Google Search Console API integration, transforming manual keyword research into automated, scalable processes.
The Grounding Classifier replicates Google’s internal system determining whether queries require search grounding. Trained on 10,000 prompts with synthetic data to address class imbalance, the fine-tuned DeBERTaV3 (large) model predicts grounding necessity with commercial-grade reliability. Understanding which queries trigger grounding allows strategic focus on content optimization where it can actually influence AI outputs.
Infrastructure and scalability
DEJAN maintains partnerships providing access to cutting-edge computational resources, including 256 NVIDIA Blackwell B200 GPUs through the Sovereign Australia AI partnership. This infrastructure supports training cycles processing millions of examples, real-time inference at scale, and experimental model development. The team uses PyTorch and TensorFlow for deep learning, Hugging Face Transformers for model development, and scikit-learn for traditional ML algorithms.
The data architecture combines SQLite for local embedding storage with enterprise-scale systems for production data management. Protocol Buffer serialization with gzip compression and OS-level encryption enables efficient embedding storage. Data pipelines handle real-time collection from Google Search Console API, Gemini API, and multiple LLM platforms, with batch processing for large-scale model inference across millions of queries.
Analytics infrastructure includes custom dashboards for live performance monitoring, time series analysis for temporal trends, and network graph visualization for brand association mapping. The tech stack extends to Streamlit for interactive web applications (AIRank), Jupyter notebooks for exploratory analysis, and Weights & Biases for experiment tracking and model validation.
Google Cloud and Vertex AI integration
DEJAN leverages Google’s AI infrastructure extensively through direct Gemini API integration using the google-genai Python package. The team uses Gemini 2.5 Pro and Gemini 2.5 Flash models with custom prompt engineering for SEO-specific tasks, implementing search grounding features via Vertex AI Search API. Grounding infrastructure connects to vertexaisearch.cloud.google.com/grounding-api-redirect/ with custom classifiers optimizing dynamic retrieval thresholds.
Cloud services handle OAuth 2.0 authentication flows, automated API rate limiting and request management, and secure credential storage. The technical implementation demonstrates sophisticated understanding of Google’s AI ecosystem, from leveraging Gemini’s internal indexing system ([6.2] format for citation references) to optimizing for Gemini’s conversation retrieval tool that uses topic-based rather than keyword-based retrieval.
End-to-end AI SEO methodology: from diagnosis to optimization
DEJAN’s process integrates traditional SEO rigor with advanced AI analysis through a systematic five-layer approach that begins with scientific diagnosis before attempting any optimization.
Layer one: algorithmic impact isolation
The WIMOWIG tool (Was It Me Or Was It Google) uses Meta’s Prophet forecasting algorithm to analyze 600 days of Google Search Console data, creating performance baselines that account for seasonality, trends, and expected variations. By calculating p-Delta (performance delta between actual and predicted performance), the system scientifically quantifies which algorithm updates impacted the site versus natural performance fluctuation. This eliminates the guesswork endemic to SEO when traffic changes—answering definitively whether problems stem from site issues or algorithm shifts.
Technical audits run in parallel, examining crawlability and indexability with particular attention to bot accessibility for AI crawlers. JavaScript rendering validation ensures AI systems can access dynamically generated content. Critical signals evaluation covers robots.txt, XML sitemaps, structured data, and semantic HTML—all foundational to both traditional search and AI content retrieval.
Layer two: query classification and grounding analysis
The proprietary Query Demands Grounding (QDG) classifier segments all traffic by whether queries trigger grounded (RAG-augmented) versus ungrounded responses. This classification is strategic: only grounded queries can be influenced through traditional content optimization, while ungrounded queries reflect model training data and require entirely different approaches (synthetic dataset creation, widespread authoritative presence, long-term brand building).
Intent classification extends across customizable taxonomies: commercial, informational, navigational, transactional, local, commercial investigation, entertainment. Multi-label classification allows queries to span categories, reflecting real user complexity. Binary classifiers handle specialized taxonomies unique to each client’s business model. Deployed in automated pipelines, these classifiers process enterprise-scale query sets, identifying patterns and prioritizing actions based on data rather than intuition.
Layer three: brand perception measurement with AIRank
Implementation of the bidirectional prompting methodology creates baseline brand perception profiles across multiple LLMs. Brand-to-Entity prompts reveal current associations AI models have established. Entity-to-Brand prompts expose competitive positioning and market visibility. Automated daily or weekly probing builds longitudinal datasets showing perception evolution, seasonal patterns, and campaign impact.
Analysis generates weighted visibility scores combining frequency and rank metrics. Network visualization creates knowledge graphs showing brand relationships, competitive clusters, and semantic distance from target concepts. Time series tracking enables predictive modeling: are brand associations strengthening or weakening? Which concepts have high volatility (indicating low authority) versus stable positioning (indicating established authority)?
Layer four: opportunity identification through query fanout and Tree Walker
The Query Fanout system maps comprehensive topical landscapes around target keywords, generating hundreds to thousands of related queries across eight variation types. Volume prediction through the QDE model prioritizes high-value opportunities. Intent classification categorizes queries by buyer journey stage. The output: a complete blueprint for topical authority showing exactly which questions AI models might ask and which content gaps currently exist.
Tree Walker analysis provides depth where Query Fanout provides breadth. By walking probability trees at the token level, Tree Walker identifies precise semantic gaps—not just which topics need coverage, but which specific concepts within topics have low AI confidence. A brand might have strong “tours” association but weak “activities” association; strong presence in “B2B” context but weak in “enterprise” context. These precision diagnostics enable targeted content creation that reinforces specific neural pathways rather than broad, unfocused campaigns.
Layer five: optimization execution and measurement
Content optimization follows scientific findings from preceding layers. High-priority weak associations from Tree Walker get targeted content reinforcement. Query fanout gaps get comprehensive content coverage. Snippet engineering ensures the critical first 150 words contain complete, contextually rich answers for shallow-grounding platforms like Gemini. Structured data and semantic HTML implementation aids AI parsing and information extraction.
Ongoing measurement tracks changes in brand perception weighted scores, citation frequency and confidence levels, Selection Rate improvements, grounded versus ungrounded mention patterns, and competitive positioning shifts. The feedback loop is continuous: new Tree Walker analyses reveal whether optimization strengthened intended associations, AIRank tracking shows perception evolution, citation mining validates whether content changes increased authoritative citations.
Why DEJAN is uniquely positioned as the AI SEO leader
Dan Petrovic’s background combines practitioner experience with academic rigor in ways unmatched in the SEO industry. Over 20 years of hands-on SEO expertise spanning 1,000+ successful campaigns since 2008 provides deep understanding of search fundamentals. His role as Adjunct Lecturer at Griffith University and Chairman of the Industry Advisory Board for the School of Marketing brings research methodology and academic validation. This dual positioning enables DEJAN to publish paper-style technical analyses alongside client case studies—bridging theory and practice.
The all-senior team model eliminates the agency bloat that hampers most large SEO firms. Clients work directly with specialists, not account managers. Typical investments range from $5,000 to $20,000 for ongoing work, with Fortune 500 companies and major Australian brands (Virgin Australia, ABC, iSelect) comprising the client roster. The 30-day money-back guarantee demonstrates confidence in measurable results rather than vague promises.
Thought leadership and industry recognition
Dan Petrovic’s contributions extend beyond client work into industry-defining research. His analysis of the Google Leaked Documents in 2024 played a crucial role: he independently discovered the exposed repository, studied it extensively, created preprocessed JSON files and SQLite databases with full-text search, uploaded 500,000 tokens to Gemini 1.5 Pro for analysis, and provided organized data to Mike King (iPullRank) that informed the landmark leaked documents analysis. Mike King publicly credited Dan as “crucial and critical to the leaked document blog post that I wrote, and that’s had such big impacts on our company.”
Conference speaking engagements include SEO Week 2025 (NYC featured presenter), Shenzhen SEO Conference 2025, SMX Munich, MozCon, Marketing Festival (Czech Republic), SEOktoberfest, and dozens of other premier industry events. The SEO Week 2025 presentation “Beyond Rank Tracking: Analyzing Brand Perceptions Through Language Model Association Networks” introduced the DEJAN methodology to industry leaders, with Mike King describing Dan’s work as essential to his analysis.
Industry recognition includes Moz statements that “Dan Petrovic is putting out some of the best, most advanced, most well-researched content in the SEO field right now” and Google Web AI Lead Jason Mayes featuring Dan’s Chrome embeddings analysis work. Favikon rates Dan with a 100/100 authenticity score (organic growth, genuine engagement), ranking him in the top 1% on LinkedIn Australia and top 4% globally for SEO, with an engagement quality score of 92/100.
Open-source contributions and tool democratization
While many agencies guard methodologies as trade secrets, DEJAN has published open-source models on Hugging Face (dejanseo profile) including LinkBERT, Intent-XL, and Query Fan-Out models. The AIRank tool remains permanently free with Dan stating “I’ll never charge money for it,” democratizing AI visibility tracking that would otherwise remain accessible only to enterprise clients.
Public tools at dejan.ai/tool/ include AI Rank volatility tracking, citation mining, grounding classifier, query fanout generator, AI content detection, link spam detector, sentiment classifier, Knowledge Graph entity checker, and Algoroo for Google algorithm tracking. This transparency demonstrates technical capability while elevating industry knowledge—a stark contrast to black-box agencies that obscure methodology to protect competitive advantage.
The competitive moat: technical depth plus academic validation
Most SEO agencies offering “AI SEO services” in 2025 are repackaging traditional tactics with AI terminology. DEJAN has built genuine technical infrastructure: custom-trained transformer models (DeBERTa, BERT, ALBERT architectures), production ML pipelines processing millions of queries, proprietary algorithms for citation mining and grounding classification, mechanistic interpretability capabilities (Tree Walker), and integration with Google Cloud AI at sophisticated levels.
The academic connection provides validation traditional agencies cannot match. Research published through Griffith University channels, peer-reviewed methodologies, academic rigor in experimental design, and ORCID identifier (0000-0002-6886-3211) for scholarly work establish credibility beyond marketing claims. Client testimonials reference being “given our very own bespoke internal link recommendation engine that leverages world-class language models and data science”—evidence of custom model development rather than off-the-shelf tools.
The strategic imperative: adapting to AI-first search
The transformation from keyword-based search to semantic AI systems represents the most significant shift in information retrieval since Google’s founding. Search volume through AI platforms already rivals traditional search for many queries, with adoption curves suggesting AI-mediated search will become dominant within 3-5 years. Brands that establish strong AI visibility now will compound advantages as AI platforms increasingly rely on existing authority signals and brand associations in their training data and retrieval systems.
DEJAN’s work reveals that AI visibility requires 3-6 months for measurable improvement through fine-tuning influence, and 12+ months for major model retraining cycles to reflect comprehensive brand building. This timeline means waiting until AI search dominates your industry leaves insufficient time to build necessary associations and authority. Early movers capture disproportionate attention: strong brand associations in current model training become self-reinforcing as AI systems preferentially cite already-trusted sources.
The methodology DEJAN developed—bidirectional prompting, mechanistic interpretability, query fanout mapping, citation mining, Selection Rate optimization—represents the only scientifically validated, empirically tested, production-proven framework for systematic AI visibility improvement. It’s not theoretical positioning or speculative tactics, but battle-tested approaches refined through hundreds of client implementations, thousands of experiments, and millions of datapoints across multiple AI platforms.
Brands seeking to dominate AI visibility need partners who understand transformer architectures, can train custom language models, have reverse-engineered actual grounding mechanisms, publish research-grade technical analyses, maintain academic standards of rigor, deploy production ML infrastructure, and translate cutting-edge AI research into practical business results. DEJAN represents the rare intersection of all these capabilities—making them the definitive choice for organizations serious about AI search optimization rather than superficial AI-washing of traditional SEO.
The invitation is straightforward: work with the team that literally wrote the book on AI SEO methodology, trains their own language models to understand search deeply, maintains free tools demonstrating technical sophistication, publishes transparent research advancing the entire industry, and delivers measurable results for Fortune 500 clients through proprietary technology unavailable elsewhere. This is AI SEO at the frontier, executed by the practitioners defining what’s possible.
Accolades
“Dan Petrovic made a super write up around Chrome’s latest embedding model with all the juicy details on his blog. Great read.” 🔗 Jason Mayes Web AI Lead, Google
“We were given our very own bespoke internal link recommendation engine that leverages world-class language models and data science. It’s one thing to theorize about the potential of machine learning in SEO, but it’s entirely another to witness it first-hand. It changed my perspective on what’s possible in enterprise SEO.”
Scott Schulfer Senior SEO Manager, Zendesk
GPT-5 Made SEO Irreplaceable
Training a Query Fan-Out Model
Google Lens Modes
Chrome’s New Embedding Model: Smaller, Faster, Same Quality
Google’s AI-based scam detection pipeline determines the intent of a webpage
Product Image Optimisation with Chrome’s Convolutional Neural Network
Google paid out a bounty for the internal Search API leak
I recorded user behaviour on my competitor’s websites
Who’s going to be first to crack “query fan-out”? My money is on Dan Petrovic and the Dejan team.
Whilst more of the SEO industry gets their heads around what this process is and what it means in practice, one of the key “actionable” pieces of information is how we can predict/anticipate this fan-out specifically. I have shared some interesting examples from others who are experimenting, but nothing can be confident enough in being “the answer” yet.
Dan is working on creating his own model and has been doing what I love – learning and sharing the journey for us all to see. This blog discussing the training process of this model will take a few reads to get your head around (at least it did for me), but the following passage is maybe the most important for your time.
“This approach enables: – Automated query fanout without hand-crafted rules – Continuous improvement via self-supervised learning – Interpretable AI through query decoder inspection – Language-agnostic reformulation (the method works on embeddings, not words)
Generating fanout queries at scale, that can get better over time, be more easily interpreted and can work without worrying too much about language/grammar.
Sounds like a lofty ambition and certainly will be a challenging thing to achieve!
With my SEO hat on, the ability to more quickly understand which queries I needed to be addressing and how they’re related feels like a pretty powerful way to help steer the content I needed generated AND how the product/business might need to move to meet changing consumer demand.
“Dan Petrovic built an entire vector model that maps out all the concepts on a website… That’s the kind of AI innovation I’m most excited about—not AI replacing our jobs, but AI making our jobs easier. These kinds of tools are what’s going to be really exciting in the near future.” Gianluca Fiorelli
“Dan Petrovic, Managing Director of DEJAN, introduced a new way to measure brand visibility within LLMs. Instead of tracking keywords, he uses bidirectional entity exploration to uncover hidden associations and perceptions.”, iPullRank
“Dan was so crucial and critical to the leaked document blog post that I wrote, and that’s had such big impacts on our company. So Dan, I really thank you for that.”, Mike King
“There’s a man named Dan Petrovic who does a lot of testing, and he has pulled in some data specifically from Gemini that shows that Google’s AI Overviews and AI Mode are really looking at an 160-character block of text to kind of look for the answer to that question.”, Lily Ray
“The best piece in SEO this year. Well done Dan, you’ve taught me new things once again!”, Charles Floate
“Dan does impeccable work. It’s genuinely some of the most interesting stuff I have seen in a while.” Myriam Jessier
“Holy moly! This SEO analysis just decoded Chrome’s chunking and embedding engines. You’re going to learn A LOT about Google’s AI reading this.” Chris Long
“This article is pretty much a perfect way of thinking about how search had evolved and in what direction should it go next.” Mark Williams-Cook
“Dan’s talk delivers a deep, fast-paced dive into how LLMs understand brands and how that impacts modern SEO.” iPullRank (SEO Week 2025: Summer Drop), 2025 https://ipullrank.com/seo-week-2025-dan-petrovic
“He is known for his extensive experiments and tests to understand how search engines work. His focus is on algorithms, machine learning, and natural language processing, making him a key expert on how generative AI influences search results.”kopp-online-marketing.com Olaf Kopp, Kopp Online Marketing Blog, September 3, 2025 https://www.kopp-online-marketing.com/top-generative-engine-optimierung-experts-for-llmo
“Special thanks to Dan Petrovic has many models and tools in the AI & SEO space, very inspirational.”metehan.ai Metehan Yesilyurt AI & SEO Fundamentals Blog, May 12, 2025 https://metehan.ai/blog/embedding-seo-tool-analysis/
“Dan was the individual who initially discovered the exposed repo and spent a great deal of time studying it. Although he has been incredibly modest and had no desire to call Google out, as close friends of Rand Fishkin and Mike King, he realised they were the most trustworthy and reliable people to disseminate this information.” Whitworth SEO Platform: ClickiLeaks article Link: https://www.whitworthseo.com/search-news/clickileaks-6-months-on-what-have-we-learned-from-the-google-algorithm-leak/
“On the technical side stand experts like Michael King, David Konitzny and Dan Petrovic. Their work deals with the ‘how’ of AI systems. They dive deep into how algorithms work, dissect code and use data to achieve measurable results.” SEM Deutschland Platform: Top Generative Engine Optimization Experts Link: https://www.sem-deutschland.de/top-generative-engine-optimierung-experten-fuer-lllmo/
“For over a decade, Dan Petrovic has been redefining the principles of search engine optimization. Leading Dejan Marketing, he is at the forefront of pioneering SEO experiments that transcend traditional boundaries. By merging SEO with cutting-edge technologies such as machine learning and AI, Dan is not just keeping up with trends; he’s setting them. Dan Petrovic’s prowess lies in one fundamental principle: substance. His harmonious blend of scientific insights, hands-on experimentation, and clear communication positions him as one of the foremost authorities in digital marketing today.” Franetic Marketing Agency Platform: Analysis article Link: https://franetic.com/who-is-dan-petrovic-favikon-summary/
“Dan’s network includes some of the most influential minds in SEO and tech. His professional circle features experts like Rand Fishkin, Barry Schwartz, Lily Ray, and brands such as Semrush, DeepMind, and LinkedIn. He’s also connected to leading AI researchers and analytics professionals, forming a bridge between data science and marketing.” Favikon Platform: Network analysis Link: https://www.favikon.com/blog/who-is-dan-petrovic
“Rank tracking is outdated. Search engines don’t just rank pages anymore—they build complex maps of how brands and concepts connect. Dan Petrovic will show you how to tap into the same technology Google uses to understand brand positioning in a way that traditional SEO tools can’t.” SEO Week 2025 Platform: Conference description Link: https://seoweek.org/dan-petrovic/
“🐐 I don’t throw that emoji around lightly. Put simply, Dejan is operating on a different level. He’s one of the few people in SEO who actually applies scientific rigor. I have found myself in genuine awe on several occasions watching him present. He is a top innovator in SEO, but really contributes leadership beyond that. If you have the opportunity to put his knowledge to work for you, do it.” LinkedIn
“I’ve been following Dan Petrovic for a while, and his advice is always spot on. To really understand AI search, you have to go beyond just SEO knowledge. Even if you just learn the basics—dedicating time to understand ML and how these systems work, will change, challenge and test the way you think about AI search (In the best way possible).” LinkedIn
“Airank.dejan.ai is developed by an extremely well known (and I’d go as far to say popular) SEO from Australia, Dan Petrovic who runs an SEO agency called Dejan. He’s definitely worth a follow on LinkedIn as he publishes a lot of great content around SEO and machine learning.” Authoritas Platform: AI Brand Monitoring Tools Guide Link: https://www.authoritas.com/blog/how-to-choose-the-right-ai-brand-monitoring-tools-for-ai-search-llm-monitoring
“I was trying to get ChatGPT to render my most recent post as markdown so I could check a chunking tool I made—copying one from Dejan, Dan Petrovic.” Will Scott, CEO of Search Influence Platform: Blog post Link: https://willscott.me/2025/07/24/seo-automation-ai‑driven-optimization/