
While traditional keyword research tools provide valuable data, they often fall short in discovering truly novel or long-tail search query variations that a business might not yet rank for, or even be aware of. This is where our query fan-out model comes in. Using advanced language models to generate a vast array of related search queries from existing organic queries.
However, generating a massive list of potential keywords creates a new challenge: how do you efficiently assess the search volume potential of these new, unproven queries? Manually checking each one is impractical. This article we present a deep learning approach developed to automatically predict the search volume ranges for these fan-out queries, transforming a broad list into an actionable, prioritized asset.
The Challenge: Scaling Keyword Research
Content teams and SEO strategists constantly seek to expand their keyword footprint. Given a primary query like “AI SEO” and a target URL (e.g., dejan.ai), a fan-out generation model can suggest many diverse, yet related queries.
Here’s the exact output from the fan-out model for a single search query:
- ai seo tools
- ai powered seo tools
- ai powered search engine optimization
- ai search engine optimization
- ai for search engine optimization
- seo automation with ai
- artificial intelligence for seo
- best ai seo tools
- ai for seo optimization
- seo with artificial intelligence
- best ai for seo
- artificial intelligence seo tools
- ai for seo ranking
- ai for seo a/b testing
- ai powered seo
- artificial intelligence in seo
- ai in search engine optimization
- ai for seo agencies
- ai for seo beginners
- artificial intelligence for search engines
- ai seo automation
- ai for seo
- AI-powered SEO tools
- ai seo best practices
- benefits of ai for SEO
- ai powered keyword research
- ai for seo content
- ai powered search engine
- ai seo tools 2025
- ai website optimization
- artificial intelligence seo
- benefits of ai in seo
- search engine optimization ai
- ai powered seo services
- AI for SEO automation
- ai SEO tools comparison
- ai seo optimization
- best ai tools for seo
- SEO with AI tools
- improve seo with ai
- ai in seo
- ai powered seo software
- machine learning for seo
- ai seo examples
- AI SEO implementation
- automate seo with AI
- ai powered website ranking
- ai marketing automation
- ai seo platforms
- zendesk ai seo
- artificial intelligence for website ranking
- ai for seo tracking
- ai seo algorithm
- ai for digital marketing
- ai for seo audit
- artificial intelligence seo strategy
- AI for SEO strategy
- ai seo automation tools
- dejan ai SEO
- ai SEO agency
- AI SEO services
- best ai SEO software
- website seo with ai
- dejan ai seo expert
- predictive seo ai
- AI SEO software
- AI for website seo
- generate backlinks with ai
- ai for seo reviews
- website ranking automation with ai
- google ai SEO
- ai website traffic
While invaluable for identifying new opportunities, this explosion of data quickly becomes overwhelming. Each generated query ideally needs a search volume estimate to determine its potential value and prioritize content efforts. Relying on external tools for millions of queries is costly and time-consuming.
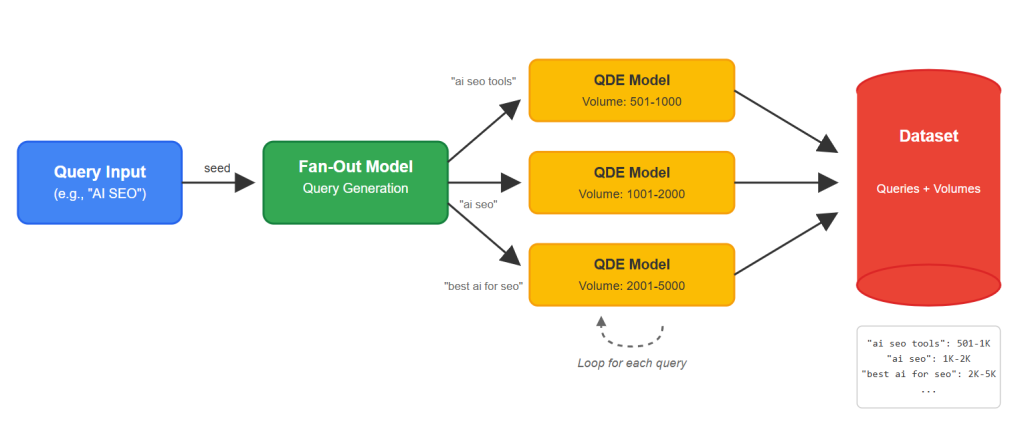
Query Demand Estimator
To address this, we developed a Query Demand Estimator (QDE) using a deep learning model. The core idea is to train a sequence classification model to categorize a given query into predefined search volume buckets.
Model Training
1. Data Preparation: The Ground Truth
The success of any supervised learning model hinges on the quality and quantity of its training data. Our approach involved:
- Collecting Organic Performance Data: We aggregated historical search performance data (impressions and clicks) for millions of queries where our digital properties ranked well (positions 1-10). Ranking well implies that the impression data is a good proxy for actual search demand, as the content is visible to a significant portion of searchers.
- Defining Volume Buckets: We established 12 distinct search volume ranges, from very low (“51-100” impressions) to very high (“200,001+” impressions). These ranges became our target labels.
- Labeling Queries: Each query from our high-ranking dataset was assigned to its corresponding impression bucket, creating a (query_text, volume_label) pair dataset. For example, “dejan ai query fan-out tool” might be labeled as “501-1000”, while “top AI SEO agencies”
label_id,label_text
- 0,51-100
- 1,101-150
- 2,151-200
- 3,201-250
- 4,251-500
- 5,501-1000
- 6,1001-2000
- 7,2001-5000
- 8,5001-10000
- 9,10001-100000
- 10,100001-200000
- 11,200001+
2. Model Architecture and Training
We leveraged a pre-trained transformer model, specifically mDeBERTa-v3-base, known for its strong performance across various natural language understanding tasks, including classification. The choice of mDeBERTa also offers multilingual capabilities, which is advantageous for global businesses.
The model was fine-tuned as a sequence classifier:
- Input: A search query.
- Output: One of the 12 predefined search volume buckets.
The training process involved:
- Tokenization: Converting text queries into numerical tokens using the MDEBERTa tokenizer, ensuring consistent input length (MAX_LENGTH=256).
- Batching and Epochs: Training in batches (BATCH_SIZE=16) over several epochs (EPOCHS=3) to allow the model to learn from the data efficiently.
- Optimization: Using AdamW optimizer with a low learning rate (LR=2e-5) and weight decay to prevent overfitting.
- Evaluation: Regular evaluation on a held-out validation set to monitor performance using metrics like accuracy, precision, recall, and F1-score. Weights & Biases (WandB) was used for experiment tracking.
MODEL_NAME = "microsoft/mdeberta-v3-base"
WANDB_PROJECT = "mdeberta-finetune"
NUM_LABELS = 12
MAX_LENGTH = 256
EPOCHS = 3
BATCH_SIZE = 16
LR = 2e-5
WEIGHT_DECAY = 0.01
WARMUP_RATIO = 0.1
LOGGING_STEPS = 10
EVAL_STEPS = 200
SAVE_TOTAL_LIMIT = 10
OUTPUT_DIR = "./finetuned-mdeberta"3. Integration into the Fan-Out Workflow
Once trained, the QDE model was integrated into our fan-out query generation system. As the fan-out model generated new query variations for a given URL and seed query, each new variation was immediately passed to the QDE model for a volume prediction. This allowed the system to:
- Generate an extensive list of relevant keywords.
- Assign an estimated search volume range and a confidence score to each generated keyword.
- Store these predictions alongside the fan-out query and its original source, making the data directly actionable.
Validation: How Accurate Are the Predictions?
Validation is crucial. To assess the QDE model’s real-world utility, we compared its predictions against a true gold standard: a subset of queries from a held out dataset, representing terms where our properties consistently ranked in the top 1-10 positions. For these queries, impression data closely reflects actual search volume.
The validation process involved:
- Extracting the QDE model’s volume predictions for all fan-out queries.
- Identifying queries that overlapped with our high-ranking ground truth dataset.
- Comparing the QDE predicted_volume bucket with the actual_volume_bucket from our ground truth.
Key Findings:
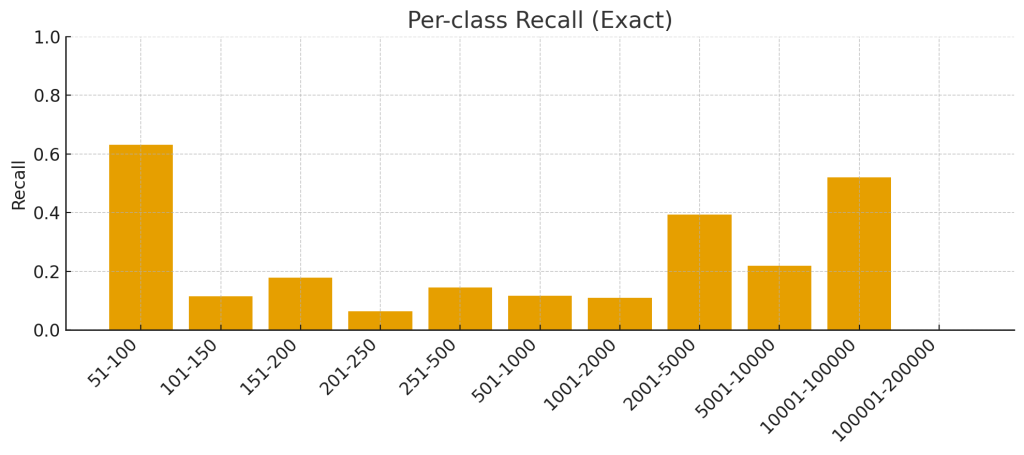
Exact Match Accuracy: 23.31%
Initially, this might seem modest. It means that for 23.31% of the overlapping queries, the model predicted the exact search volume bucket.
Combined Accuracy (Exact + Adjacent): 54.80%
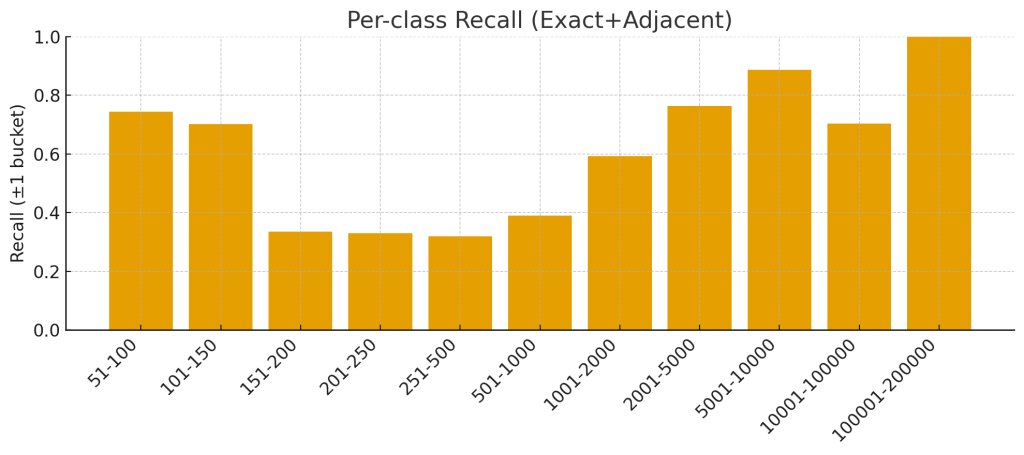
This metric is far more representative of the model’s practical value. It indicates that for 54.80% of the queries, the model’s prediction was either exactly correct OR within one adjacent search volume bucket (e.g., predicting “501-1000” when the actual was “251-500” or “1001-2000”). This level of accuracy is highly beneficial for prioritizing.
What the numbers mean
- Exact Match Accuracy (23%): Out of all predictions, only about 1 in 4 were exactly correct.
- Combined Accuracy (55%): If we also count predictions that were very close (off by just one “volume bucket”), the model got it right more than half the time.
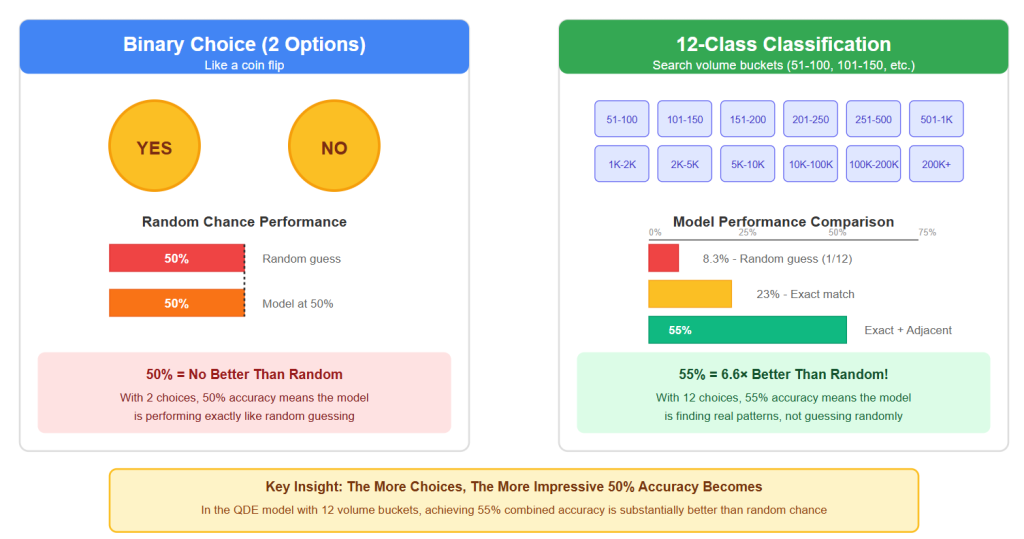
Why 50% isn’t “coin flip” odds
This isn’t a yes/no problem. The model isn’t picking between just 2 outcomes (like heads vs. tails). Instead, it has to choose among 11 different possible volume ranges (labels).
- If the model were guessing randomly, each guess would have about a 1 in 11 chance (~9%) of being correct.
- Getting ~23% exact match accuracy is much better than random chance—it means the model is finding real patterns.
- The ~55% combined accuracy shows that even when it misses, it’s often close to the right bucket, not completely wrong. That’s useful for practical decision-making.
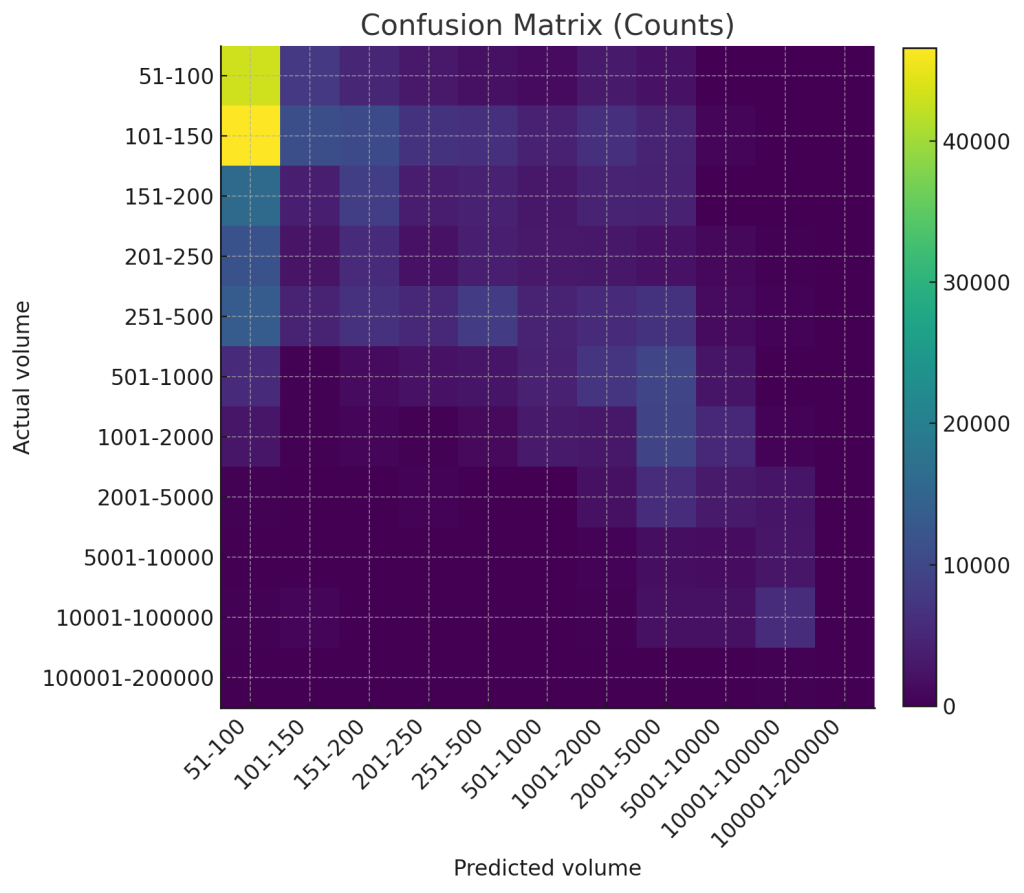
How to read the confusion matrix
- The diagonal shows “perfect hits.” Those are the exact matches.
- The cells right next to the diagonal are “near misses” (predicted slightly higher or lower than reality).
- Off-diagonal far-away values mean the model got it very wrong—these are the cases we want to reduce.
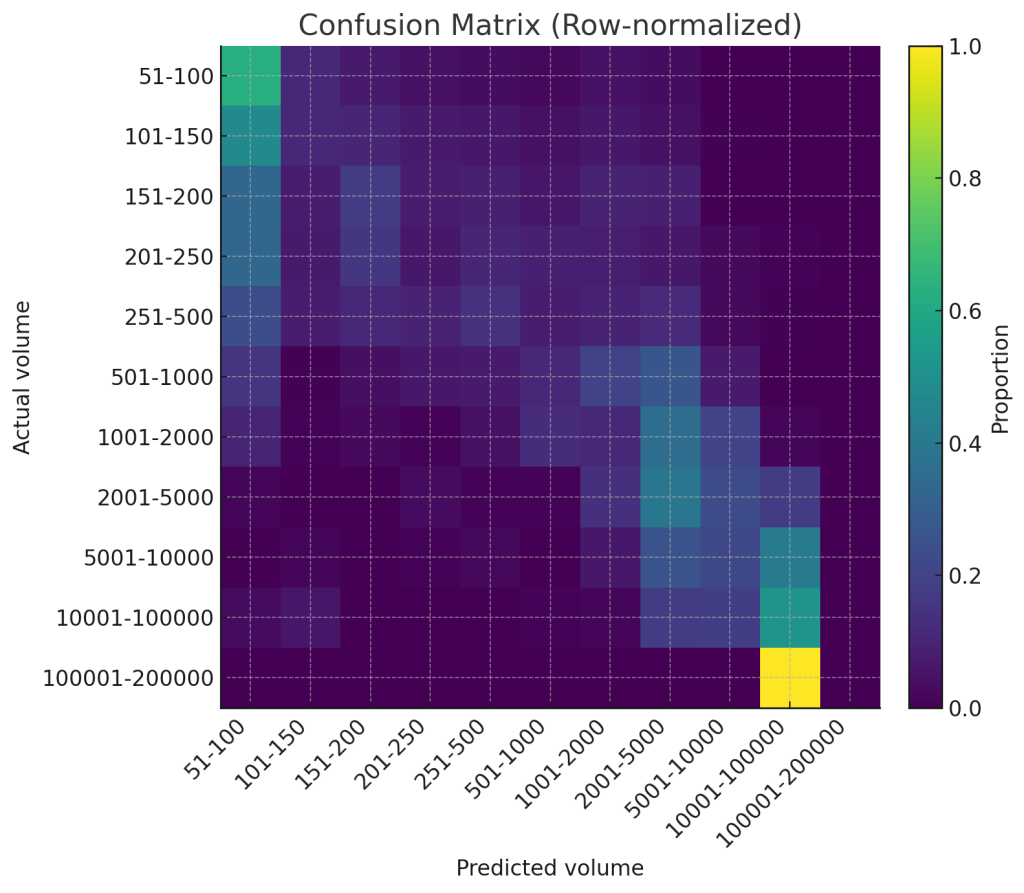
Insights from the Confusion Matrix:
The confusion matrix (a table showing actual vs. predicted labels) provided deeper insights:
- Directional Correctness: The predictions clustered strongly around the diagonal, confirming the model’s ability to broadly categorize queries into low, medium, and high-volume ranges.
- Systematic Biases:
- Under-prediction in Low-Mid Range: The model showed a slight tendency to predict slightly lower volume buckets (e.g., 51-100) for queries that actually fell into the next higher categories (101-150, 151-200). This is a useful bias, as it means potentially under-valued queries might be identified, encouraging further investigation.
- Slight Over-prediction in Mid-Range: Conversely, some mid-range queries were occasionally over-predicted by one or two buckets, which can help flag terms as potentially more valuable than initially perceived.
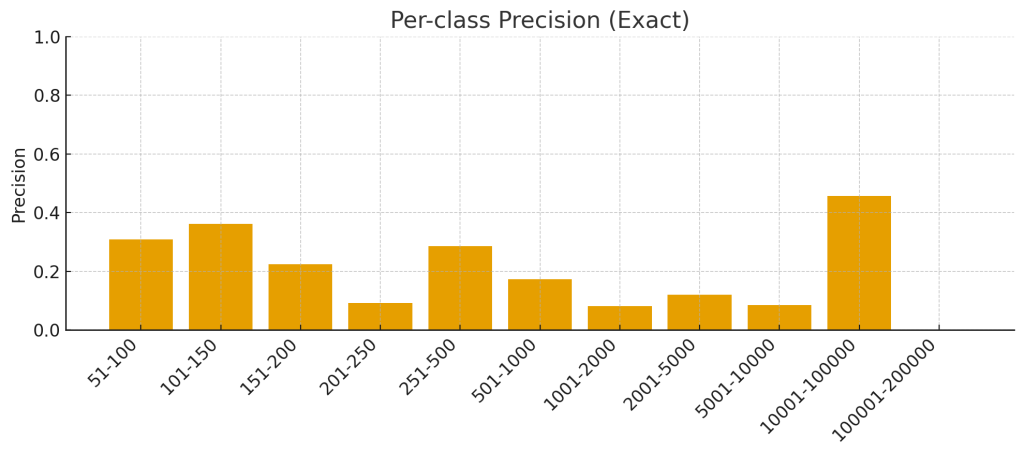
A Powerful Tool for SEO Strategy
The deep learning-powered QDE model, integrated with fan-out query generation, transforms a previously manual and time-consuming process into an automated, scalable, and data-driven one. While not always achieving perfect exact-bucket accuracy, its ability to correctly or nearly correctly classify query search volume over 50% of the time provides an invaluable, actionable signal.
This system empowers SEO teams to:
- Rapidly identify and prioritize millions of new keyword opportunities.
- Uncover long-tail queries that traditional tools might miss.
- Strategically plan content and optimize existing pages with a clearer understanding of potential demand, moving beyond guesswork with the power of deep learning.
The future of SEO keyword research is increasingly augmented by AI, allowing businesses to be more agile, comprehensive, and ultimately, more successful in capturing organic search demand.
State of the Art – Leading Research
Entity popularity signals offer the most promising foundation for zero-shot query volume prediction, according to a synthesis of recent machine learning and information retrieval literature. While direct research on predicting volume for never-before-seen queries remains sparse, converging evidence from entity importance estimation, query performance prediction, knowledge graph embeddings, and emerging LLM prompt analysis provides a viable methodological path. The core insight: because queries fundamentally seek information about entities—people, products, brands, concepts—modeling entity-level demand can generalize to arbitrary query formulations containing those entities.
Entity popularity prediction provides the cold-start foundation
The most directly relevant work comes from Van Gysel et al. (SIGIR 2020), who developed entity popularity prediction for virtual assistants at Apple. Their system forecasts which entities will trend before substantial query history exists, achieving 20% relative error reduction on emerging entity recognition. The key finding: temporal patterns of entity mentions in external signals (news, social media) correlate with future search demand, enabling predictions for entities with minimal query history.
Yang et al.’s Named Entity Topic Model (NETM) from Knowledge-Based Systems (2020) provides a theoretical framework for cold-start popularity prediction. The model assigns each named entity a “popularity-gain distribution over semantic topics”—essentially learning that certain entity-topic combinations drive engagement. For novel content, the model aggregates popularity gains from constituent entities across their topic distributions, predicting volume without any prior behavioral data.
The KB-PPN architecture (KDD 2018 Deep Learning Day) demonstrates how knowledge graph embeddings enable volume transfer between entities. By linking items to Freebase entities and encoding them via TransE embeddings, an LSTM with attention can identify similar entities in the knowledge graph and transfer their popularity dynamics. This directly addresses zero-shot prediction: a new product launch can borrow volume patterns from similar products identified via embedding proximity.
| Approach | Key Signal | Cold-Start Capability | Venue |
|---|---|---|---|
| Van Gysel et al. | Historical entity interactions + temporal patterns | High | SIGIR 2020 |
| NETM | Entity × topic popularity matrix | High | KBS 2020 |
| KB-PPN | TransE entity embeddings + KB neighbors | Medium-High | KDD 2018 |
| GENI | GNN on KG predicate-aware importance | Medium | KDD 2019 |
Knowledge graphs encode entity importance implicitly
Park et al.’s GENI (KDD 2019) directly addresses the question: “How can we estimate the importance of nodes in a knowledge graph?” Their graph neural network aggregates importance scores (not just embeddings) across predicate-aware relationships, outperforming PageRank by 5-17% on NDCG@100 for importance prediction. The architecture captures that entities connected to other important entities via meaningful relations inherit importance—a signal correlating with search demand.
Thalhammer and Rettinger (ESWC 2016) found that combining Wikipedia’s internal link structure (PageRank) with page-view data provides the strongest entity importance estimates. Wikipedia page views serve as a direct search demand proxy, while link-based importance captures “objective relevance” independent of current interest. Their methodology enables entity importance estimation even for entities lacking search engine volume data.
Entity salience offers another avenue. Google’s work on entity salience (Dunietz & Gillick, EACL 2014) introduced automatic corpus generation using document-abstract pairs—entities appearing in abstracts are deemed salient. Features like first mention position, mention frequency, and headline presence predict which entities will be searched. The NYT-Salience dataset with millions of training examples is publicly available at google-research-datasets/nyt-salience, enabling training of salience predictors.
The recent GUM-SAGE dataset (ACL Findings 2025) advances this with graded salience scores (1-5) based on summary inclusion across 5 annotators and 12 genres. This graded approach better models varying levels of search interest than binary salience. Code and data are available at github.com/jessicaxylin/GUM-SAGE.
Query performance prediction offers transferable methodology
The information retrieval community has extensively studied Query Performance Prediction (QPP)—predicting query difficulty before or after retrieval. While QPP targets retrieval effectiveness rather than volume, its methods transfer remarkably well.
Cronen-Townsend et al.’s Clarity Score (SIGIR 2002) measures the KL-divergence between a query language model and the collection language model. High clarity indicates focused, unambiguous queries; low clarity suggests ambiguity. The connection to volume: ambiguous queries may have higher aggregate volume (multiple intents summed) while highly specific queries have lower volume but clearer intent. Query specificity features from QPP can inform volume estimation.
Carmel and Yom-Tov’s synthesis book (2010) provides a comprehensive taxonomy: pre-retrieval predictors use only query features (IDF statistics, linguistic features), while post-retrieval methods use search results. For novel query volume prediction, pre-retrieval features are essential—they require no behavioral data.
Modern neural approaches show promise. BERT-QPP (Arabzadeh et al., CIKM 2021) fine-tunes BERT for pre-retrieval difficulty prediction, demonstrating that contextualized embeddings capture query characteristics correlating with retrieval outcomes. Deep-QPP (Datta et al., WSDM 2022) uses 2D convolution over query-document interaction matrices. These architectures could be adapted for volume prediction by replacing retrieval effectiveness targets with volume labels.
Query representation determines prediction architecture
Three representation paradigms dominate:
Semantic embeddings via Sentence-BERT enable similarity-based volume transfer. The intuition: if a novel query is semantically similar to known queries with volume data, transfer their volumes weighted by similarity. Nishikawa et al. (NAACL 2025 Industry) advanced this with user-behavior-driven contrastive learning at Yahoo Japan—training embeddings where queries leading to the same click or appearing in the same session are pulled together. This captures behavioral intent rather than surface lexical similarity.
Entity-based features leverage named entity recognition to extract persons, organizations, locations, and products from queries. Features include entity type, entity popularity (Wikipedia pageviews), entity recency (trending vs. evergreen), and entity embeddings from knowledge graphs. Queries containing trending celebrities or new product launches can be flagged for higher predicted volume based on entity-level signals alone.
Hybrid representations combining embeddings, entity features, and lexical statistics (query length, average IDF) perform best in production. Query length correlates strongly with volume—shorter queries tend to have higher volume (head queries) while longer, more specific queries populate the tail.
Recommended feature vector:
- SBERT embedding (768-dim)
- Entity types present (one-hot)
- Entity popularity scores (continuous)
- Query length, avg IDF
- Query type (navigational/informational/transactional)
LLM prompt volume prediction is nascent but datasets exist
The emergence of conversational AI has created new query surfaces. LMSYS-Chat-1M (ICLR 2024) provides 1 million real ChatGPT/LLaMA/Vicuna conversations across 25 models, revealing that prompt distributions follow power-law patterns similar to web search. WildChat-4.8M extends this with demographic metadata, showing geographic heterogeneity (21% US, 15% Russia, 10% China) and task distribution (creative writing dominates, followed by analysis and coding).
Critically, no published research exists on predicting novel LLM prompt volume or transferring web search patterns to prompt prediction. This represents a significant research gap. The datasets enable such work: BERTopic analysis of LMSYS-Chat-1M identified 29+ coherent topics, providing a taxonomy for prompt volume modeling.
Yelp’s engineering team demonstrated practical query volume prediction: they found query distributions follow power laws enabling pre-computation of LLM responses for 95% of traffic. This validates that prompt/query volume is predictable enough for industrial applications.
Transfer learning across search domains remains underexplored
While cross-domain recommendation research provides architectural patterns—DSAM uses shared LSTMs with attention for preference transfer, CDTM addresses feature dimensional heterogeneity—no work specifically addresses transferring volume models from web search to e-commerce search to LLM prompts.
Domain generalization frameworks (Wang et al., IEEE TKDE 2022) suggest approaches: domain-invariant representation learning, meta-learning for few-shot adaptation, and self-supervised pretraining. The recipe would be: pretrain query embeddings on web search volume prediction, then fine-tune on the target domain (e-commerce, LLM prompts) with limited labeled data.
Google Trends preprocessing research (arXiv 2024) offers practical methodology: hierarchical clustering groups semantically similar queries to overcome data sparsity, combined with correlation-based filtering. This semantic grouping approach directly applies to novel query volume estimation—cluster novel queries with known queries, then estimate volume from cluster characteristics.
Available resources for implementation
Datasets enabling entity-centric volume prediction:
| Dataset | Description | Access |
|---|---|---|
| NYT-Salience | Millions of entity salience labels | github.com/google-research-datasets |
| GUM-SAGE | Graded entity salience (12 genres) | github.com/jessicaxylin/GUM-SAGE |
| WikiPopular | Cold-start web traffic with text | Recent WWW paper |
| LMSYS-Chat-1M | LLM conversation logs | huggingface.co/datasets/lmsys |
| WildChat-4.8M | ChatGPT conversations + metadata | huggingface.co/datasets/allenai |
| Wikipedia Pageviews | Direct popularity signals | dumps.wikimedia.org |
Key code resources:
- Sentence-Transformers library (sbert.net) for query embeddings
- spaCy and BERT-NER for entity extraction
- TransE implementations in PyKEEN for entity embeddings
- GENI implementation for GNN-based entity importance
Research gaps and recommended directions
Confirmed gaps in the literature:
- No direct zero-shot query volume models exist—most work targets content popularity or query performance, not explicit volume estimation for unseen queries
- Entity-to-query volume transfer is undertheorized—while entity importance predicts entity-seeking query volume, the mapping from entity demand to specific query formulation demand lacks formal treatment
- Multi-entity query composition is unexplored—queries containing multiple entities require compositional volume estimation methods
- Cross-domain volume transfer from web search to e-commerce to LLM prompts has no published research despite strong industrial motivation
- Temporal dynamics of novel entity volume (predicting when an emerging entity will peak in search demand) combines entity popularity forecasting with time-series modeling, a combination rarely studied
The most promising research direction combines entity importance from knowledge graphs with semantic similarity to known queries: extract entities from a novel query, estimate entity-level importance via KG signals, identify semantically similar known queries, then fuse these signals in a learned model. This entity-centric architecture leverages the key insight that entities are the fundamental units of search demand, enabling generalization to arbitrary query formulations about those entities.
The path to predicting volume for unseen queries runs through entities. Entity popularity prediction from knowledge graphs, Wikipedia signals, and content salience provides cold-start capability. Query performance prediction offers proven pre-retrieval features. Semantic embeddings enable similarity-based volume transfer from known queries. The missing piece—direct volume prediction models combining these signals—represents both the primary research gap and the clearest opportunity. Industrial applications at Apple, Yahoo Japan, and Yelp validate the approach’s viability; academic formalization and public benchmarks remain the field’s next frontier.
Want one for your industry?
If you’d like a custom QDE model trained for your own website or client please apply below. This type of model training is best suited for websites with at least 100K, ideally 1M queries. We’ll evaluate your dataset and advise whether it’s suitable for model training.
Leave a Reply