
The development of modern LLMs traces back to decades of research in language modeling, but the current era was catalyzed by the introduction of the Transformer architecture in 2017. Since then, we’ve witnessed an extraordinary progression: from GPT-1’s 117 million parameters to models exceeding 400 billion parameters, from narrow task performance to emergent reasoning capabilities that continue to surprise researchers.
From Specialized to Foundation Models
Before diving into the technical details, it’s worth understanding why LLMs represent such a departure from traditional approaches. For decades, the standard methodology in machine learning involved training unique models for each specific task. Want a sentiment classifier? Train a model on labeled sentiment data. Need a named entity recognizer? Train another model on entity-annotated text. Need a machine translation system? Build yet another specialized model trained on parallel bilingual data. Each application required its own labeled dataset and its own specialized architecture.
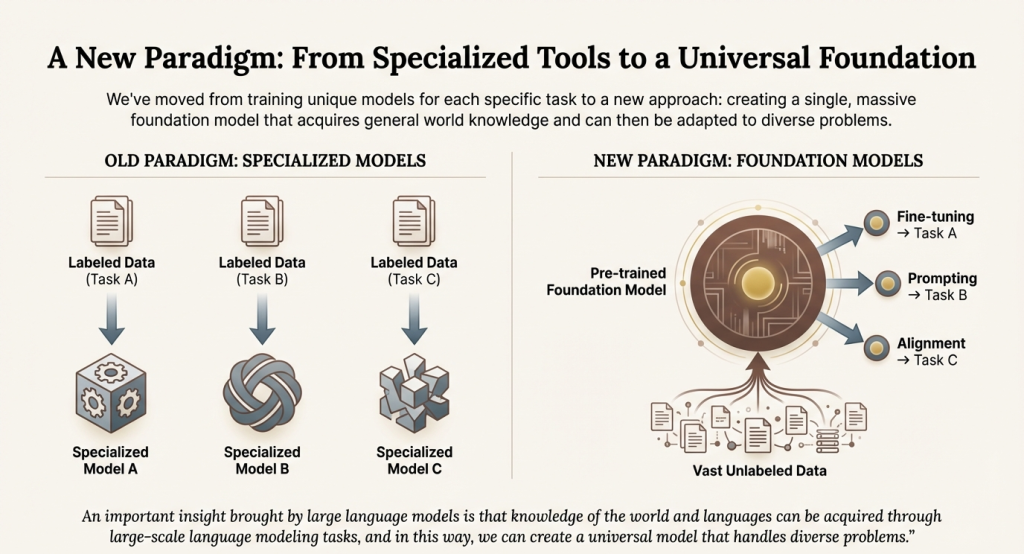
This approach, while effective for individual tasks, had significant limitations:
- Data requirements: Each task demanded substantial labeled data, which is expensive and time-consuming to create.
- Limited knowledge transfer: A model trained for sentiment analysis learned nothing useful for translation.
- Maintenance burden: Organizations needed to maintain multiple distinct models, each with its own deployment requirements.
- Cold start problem: New tasks required starting from scratch, even if conceptually similar to existing ones.
The foundation model paradigm inverts this approach entirely. Instead of training task-specific models from scratch, we now create a single, massive pre-trained model that acquires general world knowledge and can then be adapted to diverse problems through fine-tuning, prompting, or alignment techniques.
Think of it this way: the old approach was like training individual specialists from birth—a person who only knows medicine, another who only knows law. The new approach is like creating a broadly educated generalist who can then specialize with relatively little additional training in any field.
This shift is made possible by a key insight: knowledge of the world and languages can be acquired through large-scale language modeling tasks. By training a model to predict words in vast quantities of text, we create a system that implicitly learns grammar, facts, reasoning patterns, and even aspects of common sense. The resulting foundation model serves as a starting point that can be efficiently adapted to countless downstream applications.
The practical implications are profound. A single LLM can handle translation, summarization, question answering, code generation, creative writing, and analysis—tasks that previously required entirely separate systems.
Self-Supervised Pre-training
The Core Concept
Pre-training builds a model’s foundational knowledge without requiring human-provided labels. Instead of supervised learning where humans annotate data with correct answers, the model creates its own learning tasks directly from unlabeled text. This approach, known as self-supervised learning, enables training on virtually unlimited data—the entire internet becomes a potential training corpus.

The primary mechanism is deceptively simple: the model learns by predicting missing or future words in text. By repeating this task billions of times across diverse documents, the model develops a deep understanding of language, grammar, facts, and reasoning.
Consider an example. Given the phrase “The early bird catches the ____,” a model might predict probabilities like: “worm” (85%), “fish” (5%), “prize” (3%). To make this prediction correctly, the model must understand not just grammar but also the semantic relationship encoded in this common idiom. Scale this across trillions of words, and you begin to see how general knowledge emerges.
The Three Architectural Blueprints
Pre-trained models built on the Transformer architecture come in three primary configurations, each suited for different kinds of tasks.
Decoder-Only Models (e.g., GPT series, LLaMA, Claude)
These models perform what’s called causal language modeling—predicting the next word given all previous words. Information flows in one direction, left-to-right, with each word only able to “see” words that came before it.
This architecture excels at generative tasks like dialogue, text completion, and creative writing. It’s the architecture behind GPT-4, Claude, LLaMA, and most modern LLMs you interact with.
Encoder-Only Models (e.g., BERT)
These models predict words that have been randomly masked out from the middle of a sentence. Unlike decoder models, information flows in both directions—each word can see all other words in the sentence.
This architecture is particularly well-suited for understanding tasks like classification, extracting entities from text, and semantic search, where having full context on both sides of a word is valuable.
Encoder-Decoder Models (e.g., T5, BART)
These models combine both approaches: a bidirectional encoder processes the input, and a unidirectional decoder generates the output. This architecture is natural for transformation tasks like translation and summarization.
For modern generative LLMs—the chatbots and assistants you use—the decoder-only architecture has become dominant. Its simplicity, scaling properties, and natural fit for generating text make it the foundation for most frontier models.
The Transformer Decoder Architecture
The decoder-only architecture that powers most LLMs consists of several key components stacked together:
- Embedding Layer: Converts input words into dense numerical representations (vectors), combining word meanings with positional information so the model knows where each word appears in the sequence.
- Stacked Transformer Blocks: The heart of the model. Each block contains:
- A self-attention layer that allows words to gather information from previous words (like a word asking “what context came before me?”)
- A feed-forward network that processes this gathered information
- Normalization and residual connections that keep training stable
- Output Layer: Converts the final representations back into probabilities over the vocabulary—essentially predicting “what word comes next?”
The self-attention mechanism is what makes Transformers special. It allows the model to dynamically focus on relevant parts of the input when making predictions. When generating the word after “The capital of France is,” the model can attend strongly to “France” and “capital” while largely ignoring “The” and “of.”
Modern LLMs stack dozens or even hundreds of these Transformer blocks. More layers generally mean more capacity to learn complex patterns, but also more parameters and compute requirements.

Training at Scale
Training an LLM is conceptually straightforward: show the model lots of text and ask it to predict each next word. Adjust the model’s parameters to make it better at prediction. Repeat billions of times.
The training objective is simple: minimize how “surprised” the model is by the actual next word. If the model predicts “worm” with 90% confidence and that’s correct, it’s doing well. If it predicted “elephant” with 90% confidence and the answer was “worm,” adjust the parameters to do better next time.
However, the scale of modern LLMs transforms this simple objective into a formidable engineering challenge.
Data Preparation
The quality, diversity, and volume of training data profoundly impact model capabilities. Modern LLMs are typically trained on datasets comprising trillions of words from diverse sources:
- Web crawls: Common Crawl and similar datasets provide enormous scale but require heavy filtering
- Books and literature: High-quality, long-form text with coherent narratives
- Academic papers: Technical content with structured reasoning
- Code repositories: Programming languages from GitHub and similar sources
- Curated datasets: Wikipedia, Stack Overflow, and other high-quality human-generated content
Data quality matters enormously. Raw web-scraped data contains errors, toxic content, duplicate pages, and increasingly, machine-generated text. Production training pipelines include extensive filtering and cleaning steps—some teams report removing 90% of raw web data through quality filters.
These filters check for language quality, remove duplicates, filter out harmful content, and balance different types of material. The goal is a diverse but high-quality dataset.
Data diversity is equally critical. Training on varied domains enables the model to handle diverse downstream tasks. Notably, including programming code in training data has been found to improve not just coding abilities but also general reasoning capabilities—likely because code requires precise logical thinking and structured problem decomposition.
Model Modifications for Stable Training
Training very large neural networks is inherently unstable. Small numerical errors can cascade through billions of parameters. Several architectural modifications have become standard to enable reliable large-scale training:
- Pre-norm architecture: Normalizing data before (rather than after) key computations improves how gradients flow through deep networks.
- Specialized activation functions: Functions like SwiGLU have empirically shown better performance than older alternatives.
- Removing unnecessary components: Eliminating certain bias terms improves stability in very large models.
These may sound like minor technical details, but they’re the difference between a successful training run and one that fails catastrophically after weeks and millions of dollars.
Distributed Training
No single computer can train a modern LLM. A model with 70 billion parameters requires approximately 140GB just to store the weights—far exceeding the memory of any single GPU. When you add all the other data needed during training, requirements balloon to many times that.
Distributed training across hundreds or thousands of GPUs is essential. Teams use multiple strategies:
- Data Parallelism: Split training data across devices, each computing on different examples, then combine the results.
- Model Parallelism: Split the model itself across devices when it’s too large for any single device’s memory.
- Pipeline Parallelism: Process different parts of different examples simultaneously, like an assembly line.
Modern training systems combine these approaches. The engineering complexity of coordinating thousands of devices, managing communication, handling failures, and ensuring numerical stability cannot be overstated. Training runs last weeks or months; a single failed device can corrupt days of progress.
Predictable Scaling
One of the most remarkable discoveries about LLMs is that their performance improves predictably as you scale up three factors: model size (number of parameters), dataset size (amount of training text), and compute used for training.
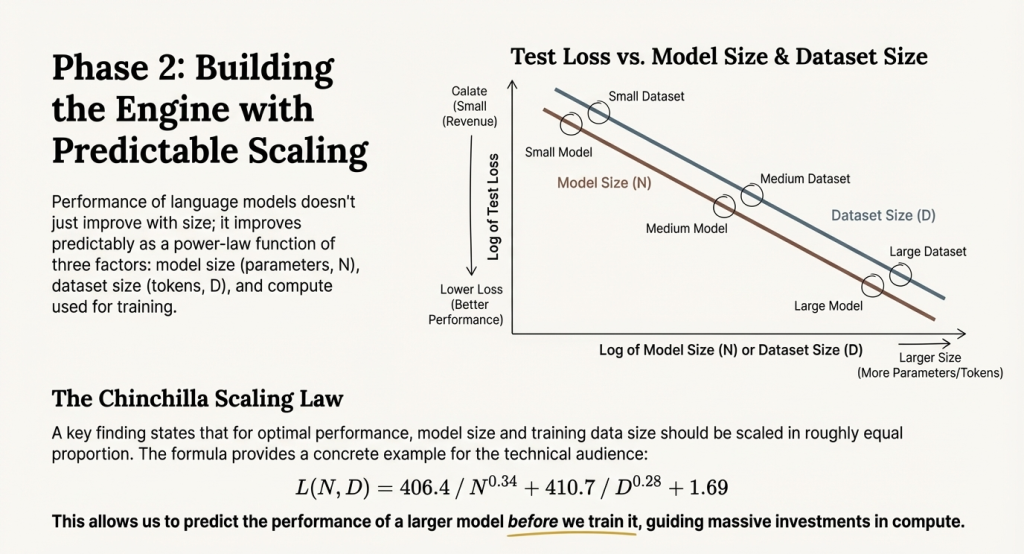
This relationship, formalized in “scaling laws” research, allows teams to predict the performance of larger models before training them—crucial when training costs millions of dollars.
The Chinchilla Discovery
Early scaling research suggested that model size was the primary driver of performance, leading to increasingly parameter-heavy models. However, research from DeepMind in 2022 established a more nuanced picture: for optimal performance given a fixed compute budget, model size and training data should be scaled together in roughly equal proportions.
The key formula researchers use predicts test loss (lower is better) based on parameter count and training tokens. What matters practically: this formula revealed that many early LLMs were “undertrained”—they had large parameter counts but insufficient training data.
A 280 billion parameter model trained on 300 billion words might actually be outperformed by a 70 billion parameter model trained on 1.4 trillion words, despite the smaller model using similar total compute. This insight shifted the field toward training smaller models on more data, achieving competitive performance with far fewer parameters.
Compute-Optimal Training
Another way to frame this: given a compute budget, what’s the optimal split between model size and training data? The research suggests roughly equal scaling. If you 10x your compute budget, you should approximately 3x your model size and 3x your training data—not 10x the model size alone.
Emergent Abilities
Beyond predictable scaling, LLMs exhibit emergent abilities—capabilities that appear suddenly as models cross certain size thresholds. Unlike the smooth improvement predicted by scaling laws, these abilities seem to “switch on” at specific scales.
Examples include:
- Few-shot learning: The ability to learn new tasks from just a few examples shown in the prompt
- Chain-of-thought reasoning: Breaking complex problems into intermediate steps
- Multi-step arithmetic: Performing calculations requiring multiple operations
- Code generation: Writing functional programs from descriptions
Below a certain scale, models show essentially zero capability on these tasks. Above the threshold, performance jumps dramatically. This emergence is both exciting and somewhat mysterious—it suggests that scale doesn’t just improve existing capabilities linearly but can unlock qualitatively new behaviors.
The Long-Context Challenge
The self-attention mechanism that makes Transformers so powerful has a fundamental limitation: the computation and memory required grow with the square of sequence length. Double the context length and you quadruple the cost. Processing book-length documents becomes computationally infeasible with naive implementations.

The KV Cache Bottleneck
During text generation, the model stores what’s called a Key-Value (KV) cache—intermediate representations for every previous word that need to be consulted when generating each new word. For very long sequences, this cache consumes enormous amounts of GPU memory.
Think of it like having a conversation where you need to consult every word ever spoken before saying your next word. The longer the conversation, the more you need to remember and reference.
Solutions for Extending Context
Several innovations address the long-context challenge:
Efficient Attention Architectures
- Sparse Attention: Only allow words to attend to a subset of other words (e.g., nearby words plus some important distant ones), reducing complexity dramatically.
- Grouped-Query Attention (GQA): A clever architectural change that reduces the KV cache size by having multiple “queries” share the same stored “keys” and “values.” This has become standard in modern LLMs, offering a good balance between capability and efficiency.
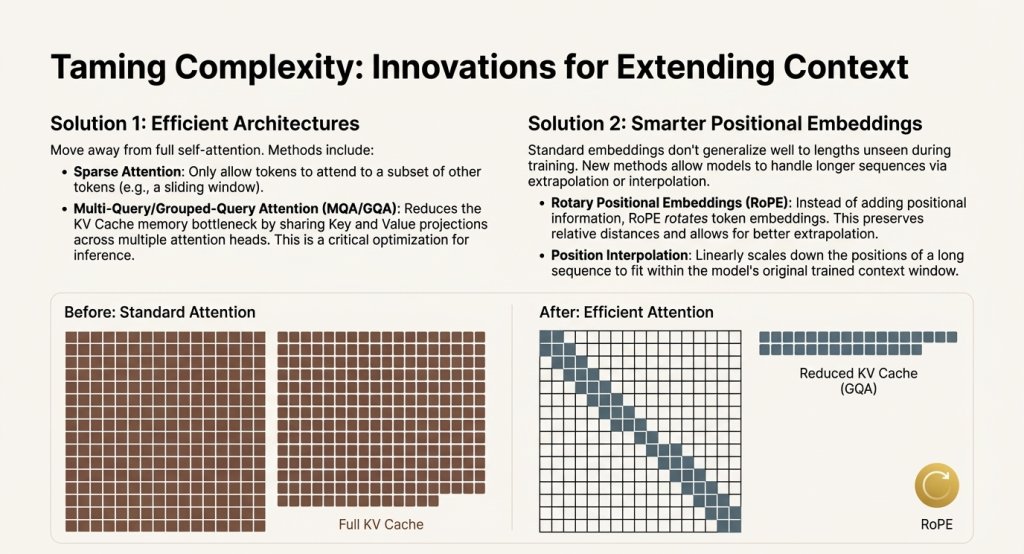
Smarter Position Handling
Standard ways of encoding word positions don’t work well for sequences longer than those seen during training. Two innovations address this:
- Rotary Position Embeddings (RoPE): Instead of adding position information, this approach rotates word representations based on position. This preserves relative distances between words and enables better handling of longer sequences.
- Position Interpolation: Mathematically adjusts position encodings so longer sequences fit within the model’s original trained range.
These techniques have enabled context windows to grow from 2,000-4,000 tokens in early models to 100,000+ tokens in current ones—a 25-50x improvement.
Unlocking Knowledge Through Prompting
A trained LLM is a powerful knowledge base, but it needs instructions. A prompt is simply the input text that guides the model to perform a specific task without changing its underlying parameters. This approach enables adapting a single model to countless tasks simply by changing the input.
In-Context Learning
One of the most remarkable properties of LLMs is in-context learning—the ability to learn new tasks on the fly just by seeing examples within the prompt itself. No model updates occur; the model simply recognizes patterns from the provided examples and applies them.

This exists on a spectrum:
- Zero-Shot: Provide only a task description with no examples. “Translate ‘hello’ to French.”
- One-Shot: Provide a single example. “sea otter → loutre de mer. Now translate ‘hello’ to French.”
- Few-Shot: Provide several examples. This is the most powerful form, enabling the model to infer complex patterns from limited demonstrations.
The practical implication: you can often get an LLM to perform a new task just by showing it what you want through examples, without any fine-tuning or specialized training.
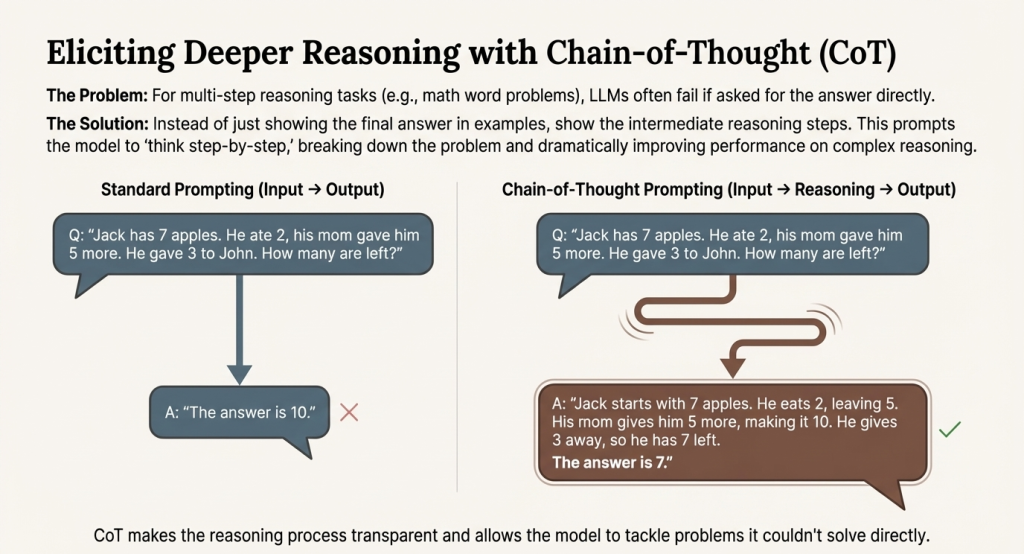
Chain-of-Thought Prompting
For multi-step reasoning tasks like math word problems, LLMs often fail when asked for direct answers. Chain-of-Thought (CoT) prompting dramatically improves performance by showing the model how to decompose problems into intermediate reasoning steps.
Consider this problem: “Jack has 7 apples. He ate 2, his mom gave him 5 more, and he gave 3 to John. How many does he have?”
Standard prompting might yield an incorrect answer. But with chain-of-thought:
“Jack starts with 7 apples. He eats 2, leaving 5. His mom gives him 5 more, making 10. He gives 3 to John, leaving 7. The answer is 7.”
By making the reasoning process explicit, CoT allows the model to tackle problems it couldn’t solve directly. Even a simple instruction like “Let’s think step by step” can elicit this behavior—no examples needed.
This technique has proven especially valuable for math, logic puzzles, and complex analysis tasks where the answer requires combining multiple pieces of information.
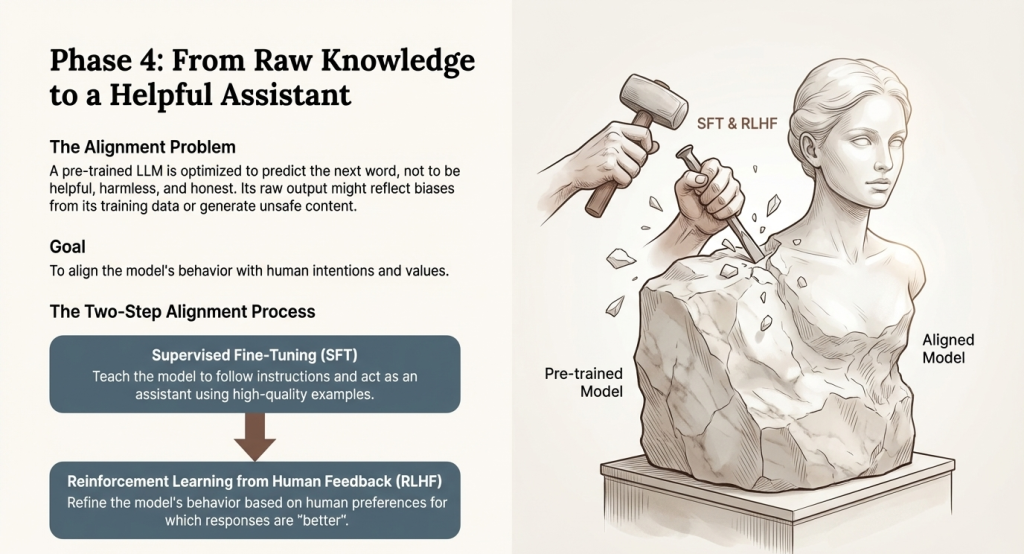
From a Raw Model to a Helpful Assistant
The Alignment Problem
A pre-trained LLM is optimized to predict the next word—not to be helpful, harmless, and honest. Its objective is purely statistical: maximize the likelihood of the training data. This means it will happily generate toxic content if such content appeared in training, or confidently produce false information if it matches surface patterns in the data.
The raw output of a pre-trained model often exhibits problematic behaviors:
- Sycophancy: Agreeing with whatever the user says, even when incorrect
- Hallucination: Generating plausible-sounding but false information
- Harmful content: Producing instructions for dangerous activities if asked
- Format confusion: Continuing to write like training data rather than responding like an assistant
The goal of alignment is to steer the model’s behavior to match human intentions and values. This involves not just teaching the model to follow instructions, but instilling preferences for helpful, honest, and harmless responses.
The Two-Step Alignment Process
Modern LLM alignment typically involves two complementary phases:
Step 1: Supervised Fine-Tuning (SFT)
SFT teaches the model the format of helpful dialogue by training on curated datasets of high-quality instruction-response pairs. These pairs demonstrate desired behavior: a user asks something, and the response shows what a helpful, knowledgeable assistant should say.
The key insight: during this training, the model learns from only the response portion, not the instruction. It processes the entire conversation but only gets “credit” for generating appropriate responses. This teaches the model to produce good responses given instructions, without learning to generate instructions (which would be counterproductive).

Surprisingly, effective SFT doesn’t require massive datasets. Research has shown that high-quality fine-tuning on just 1,000-10,000 carefully selected examples can unlock strong instruction-following behavior.
This supports what researchers call the superficial alignment hypothesis: the core capabilities were learned during pre-training, and fine-tuning merely activates them. The model already “knows” how to be helpful; SFT teaches it that being helpful is what’s expected.
Step 2: Reinforcement Learning from Human Feedback (RLHF)
SFT teaches format, but writing “perfect” example responses for every situation is impossible. What makes a response “good” is often subjective and context-dependent. It’s much easier for humans to compare two responses and say which is better than to write an optimal response from scratch.
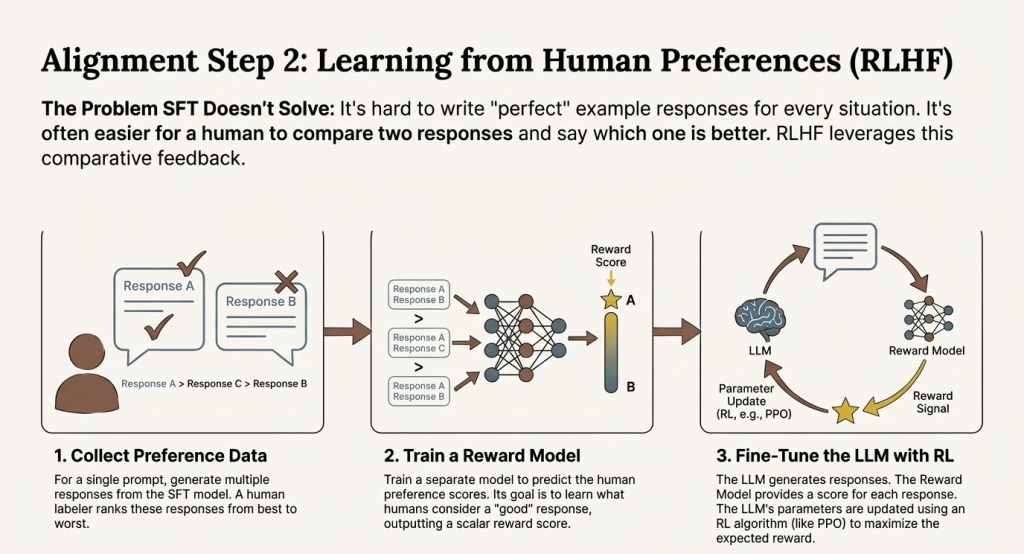
RLHF leverages this insight through a multi-stage process:
Stage 1: Collect Preference Data
For a given prompt, generate multiple responses from the SFT model (typically 4-8 options). Human annotators then rank these responses from best to worst, or make pairwise comparisons (“Response A is better than Response B”).
This comparison approach works well because:
- It’s cognitively easier than assigning absolute scores
- It provides useful signal even when no response is perfect
- People tend to agree more on comparisons than absolute ratings
Stage 2: Train a Reward Model
Train a separate neural network to predict human preference scores. Given a prompt and response, this reward model outputs a score indicating quality.
The model learns from the human comparisons: “given that humans preferred Response A over Response B, adjust to score A higher than B.” After seeing thousands of such comparisons, the reward model develops a general sense of what humans prefer.
Stage 3: Optimize the LLM Using the Reward Model
Finally, use the reward model to guide further fine-tuning of the LLM. The model generates responses, the reward model scores them, and the LLM adjusts to produce higher-scoring responses.
A critical constraint: the model must stay close to its original behavior. Without this, the model might find “hacks”—degenerate responses that score high on the reward model but aren’t genuinely good. For example, it might learn to produce very long responses if evaluators slightly prefer longer answers, even when brevity would be better.
Direct Preference Optimization (DPO)
RLHF is complex, requiring training and maintaining multiple models. Direct Preference Optimization offers a simpler alternative that skips the reward model entirely.
The mathematical insight: there’s a direct relationship between what humans prefer and how the model’s output probabilities should change. Instead of training a separate reward model and then using it to guide the LLM, DPO directly adjusts the LLM based on human preferences in a single step.
DPO is simpler to implement, more stable to train, and often produces comparable results. It has become increasingly popular, especially for smaller teams and research applications where the complexity of full RLHF is prohibitive.
How LLMs Generate Text
With a trained and aligned model in hand, we turn to the practical question of generating output. Inference—the process of using the model to produce text—involves both computational challenges and algorithmic choices that significantly impact output quality and response time.
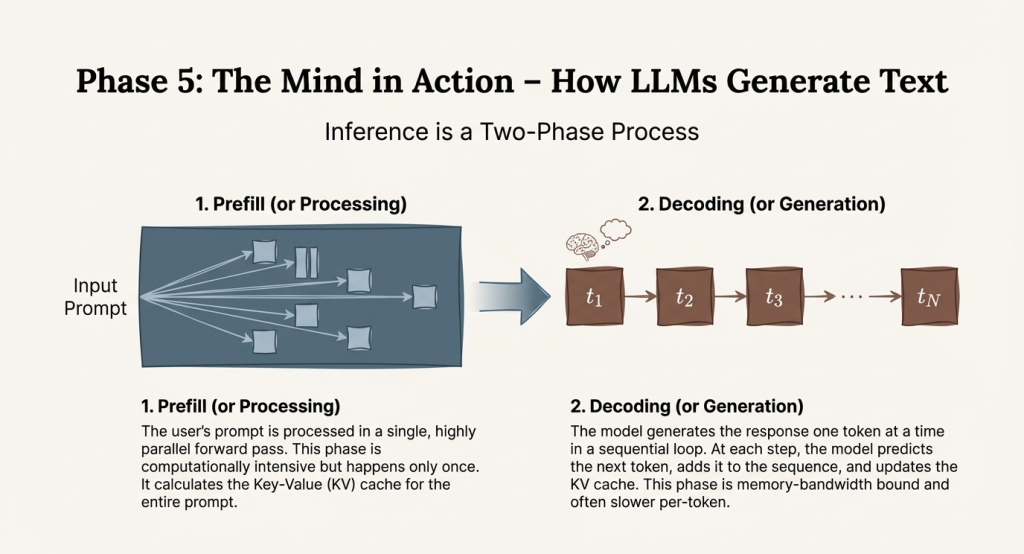
Inference as a Two-Phase Process
LLM inference divides naturally into two distinct phases with very different characteristics:
1. Prefill (Processing Your Prompt)
Your entire prompt is processed in a single, highly parallel pass. All words in the prompt can be processed simultaneously because the model has access to the complete input upfront. This phase builds the KV cache—stored intermediate computations that will be reused during generation.
This phase is compute-bound: the bottleneck is raw computation speed, and modern GPUs excel at the highly parallel operations involved.
2. Decoding (Generating the Response)
The model generates the response one word at a time in a sequential loop. At each step:
- Process the most recent word through the network
- Consult all previous words using the cached computations
- Produce probabilities for what word should come next
- Select the next word
- Add this word’s computations to the cache
- Repeat until done
This phase is memory-bandwidth bound—the limiting factor is reading the large cache from GPU memory for each word generated. The actual calculations are relatively quick compared to the time spent moving data around.
This explains why LLMs can process long prompts relatively quickly but generate responses word-by-word with noticeable pauses. The prefill happens in parallel; the decoding is inherently sequential.
Decoding Strategies: How Models Choose Words
Given probabilities for every possible next word, how does the model actually pick one? This choice significantly impacts output quality, creativity, and coherence.
Greedy Decoding
Always pick the highest-probability word. Simple and deterministic, but can produce repetitive, generic outputs. The model gets “stuck” in high-probability patterns without exploring alternatives.
Beam Search
Instead of tracking just one sequence, maintain several of the most promising sequences simultaneously. At each step, expand all of them and keep the best overall. This produces higher-quality outputs for tasks with clear “correct” answers but is more expensive.
Sampling with Temperature
Introduce controlled randomness. Instead of always picking the most likely word, sample from the distribution of possibilities.
Temperature controls how random this sampling is. Think of it like adjusting the “creativity dial”:
- Lower temperature (e.g., 0.3): More focused, deterministic, stays close to the most likely words
- Higher temperature (e.g., 1.2): More creative, diverse, willing to pick less likely words
- Temperature of 1.0: Use the model’s raw probabilities unchanged
Top-p (Nucleus) Sampling
Sample only from words whose combined probability exceeds some threshold (e.g., 90%). This adaptively adjusts based on uncertainty:
- When the model is confident, only a few words qualify
- When uncertain, more options remain in the mix
This prevents sampling from extremely unlikely words (avoiding nonsense) while maintaining diversity among reasonable options.
In practice, top-p sampling around 0.9 with moderate temperature works well for creative tasks, while lower temperature or greedy decoding suits factual questions where there’s a clear right answer.
Inference Metrics: What Gets Measured
System performance is measured along several dimensions:
- Time to First Token (TTFT): How quickly the first output word appears—dominated by prefill time
- Time Per Output Token (TPOT): Average time to generate each subsequent word
- Throughput: Total words generated per second across all users
- Latency: End-to-end time from request to complete response
Different applications prioritize different metrics. Chatbots need low TTFT for responsiveness—users want to see something happening quickly. Batch processing systems running overnight care more about throughput. Real-time applications like voice assistants need consistently low latency.
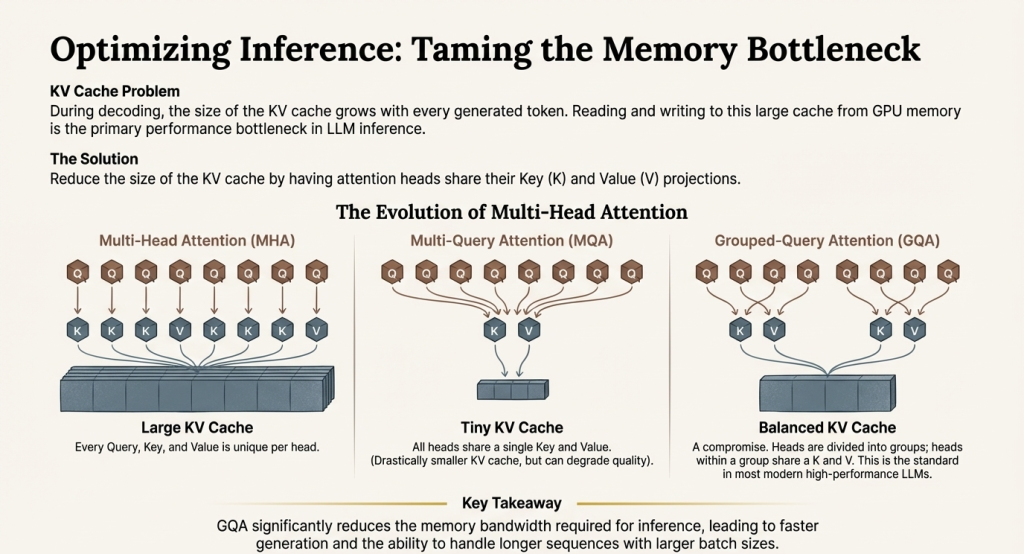
Optimizing Inference: Taming the Memory Bottleneck
The KV cache dominates inference cost. Its size grows with every generated word, and reading/writing this cache from GPU memory creates the primary bottleneck.
Grouped-Query Attention (GQA) significantly reduces cache size by having multiple “query” computations share the same stored “key” and “value” data. The tradeoff: some expressiveness for major memory savings.
The evolution:
- Multi-Head Attention (original): Every query has unique keys and values → Large cache
- Multi-Query Attention: All queries share one set of keys/values → Tiny cache but quality loss
- Grouped-Query Attention: Queries grouped to share keys/values → Balanced tradeoff
GQA has become standard in modern high-performance LLMs, enabling faster generation, longer contexts, and more concurrent users.
What This Means for Your Work
Understanding the LLM lifecycle isn’t just academic—it has direct implications for how you use these systems effectively.
Why Prompting Works the Way It Does
Because LLMs are trained to predict what comes next in text, they respond to prompts by generating the most likely continuation. This explains several prompting best practices:
Be specific about format: If you want a bulleted list, say so. The model predicts what text should follow your prompt—if your prompt looks like it precedes a paragraph, you’ll get a paragraph.
Provide examples (few-shot): Showing examples works because the model predicts “more of the same pattern.” If you show three examples of input-output pairs, the model predicts that the fourth input should produce a similar output.
Use role prompts carefully: “You are an expert…” works because training data contains text where experts write differently than novices. But the model is still predicting likely text, not actually becoming an expert.
Chain-of-thought helps math and logic: Asking the model to “think step by step” works because explanatory text in training data often precedes correct answers. The intermediate steps aren’t just window dressing—they help the model stay on track.
Understanding Model Limitations
Several common LLM limitations trace directly to the training process:
Hallucination: The model predicts plausible-sounding text, not verified facts. If confident-sounding false information appeared in training data, the model learned to produce confident-sounding false information.
Cutoff dates: Models know nothing about events after their training data was collected. They can’t search the web or access current information unless specifically connected to such tools.
Inconsistency: Different prompts can produce contradictory answers because the model generates whatever continuation is most likely given that specific context. Each generation is somewhat independent.
Context window limits: There’s a hard limit on how much text the model can consider at once. This traces to the quadratic attention cost—longer contexts require exponentially more resources.
Choosing Between Models
Understanding the lifecycle helps you choose models for different tasks:
Smaller vs. larger models: Larger models have more emergent capabilities but cost more to run. For simple tasks (classification, extraction, formatting), smaller models often suffice. For complex reasoning, chain-of-thought, or handling unusual requests, larger models are worth the cost.
Base vs. instruction-tuned models: Base models (pre-trained only) are good at completion but poor at following instructions. Instruction-tuned models are better at dialogue and tasks but may resist certain creative uses. Choose based on your application.
Open vs. closed models: Open models (LLaMA, Mistral) can be fine-tuned and run locally but require infrastructure. Closed models (GPT-4, Claude) offer convenience and often better performance but with less control and ongoing costs.
The Emergent Mind
We’ve traced the journey from raw pre-trained knowledge through scaling, prompting, and careful alignment to create sophisticated AI assistants. Each phase builds on the previous, transforming statistical pattern matching into something that can follow instructions, reason through problems, and engage in helpful dialogue.

But perhaps the most profound insight is what happens at the boundaries of these deliberate engineering choices: emergent abilities that weren’t explicitly trained for and aren’t present in smaller models. Few-shot learning, chain-of-thought reasoning, coding ability—these capabilities appear as models cross certain thresholds of scale.
This emergence suggests that building an LLM isn’t purely engineering. It’s about creating the conditions for complexity to produce capability, often in surprising and unpredictable ways. The architecture provides the substrate, the training data provides the raw material, and scale provides the catalyst—but what emerges can exceed what any of these components would predict.
For practitioners, understanding this lifecycle provides practical benefits:
- Prompting effectively requires understanding that models predict text continuations—frame your requests as contexts that naturally lead to the responses you want.
- Evaluating models requires recognizing that capabilities vary with scale, and emergent abilities may be present in larger models but absent in smaller ones.
- Setting expectations requires understanding that alignment isn’t perfect—models are trained to be helpful, but they’re still statistical systems that can fail in predictable and unpredictable ways.
- Optimizing performance requires recognizing the prefill/decode distinction and the memory bottleneck that dominates generation speed.
As these systems continue to advance, understanding their complete lifecycle—from pre-training through alignment to efficient inference—becomes essential for anyone working with AI. The making of these minds is both a remarkable engineering achievement and an ongoing frontier of discovery.
Further Reading
- “Attention Is All You Need” (Vaswani et al., 2017) — The paper that introduced Transformers
- “Language Models are Few-Shot Learners” (Brown et al., 2020) — GPT-3 and the demonstration of emergent in-context learning
- “Training Compute-Optimal Large Language Models” (Hoffmann et al., 2022) — The Chinchilla scaling laws
- “Training language models to follow instructions with human feedback” (Ouyang et al., 2022) — The InstructGPT paper introducing RLHF for LLMs
- “Direct Preference Optimization” (Rafailov et al., 2024) — The simpler alternative to RLHF
- “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” (Wei et al., 2022) — How prompting for intermediate steps improves reasoning
This article draws on “Foundations of Large Language Models” by Tong Xiao and Jingbo Zhu (NLP Lab, Northeastern University & NiuTrans Research), available at https://github.com/NiuTrans/NLPBook