
I’ve been reverse-engineering Google’s Gemini grounding pipeline (AI Mode, Gemini Chat…etc) by examining the raw groundingSupports and groundingChunks returned by the API. Specifically, I’m interested in the snippet construction step, the part where, given a query and a retrieved web page, the system selects which sentences to include in the grounding context supplied to the model.
From examining the extracted sentences against full source content, I’ve observed:
- Query-focused selection: Sentences semantically close to the query are strongly preferred. Sections about “abstractive summarization” on the same page are skipped entirely.
- Heavy positional / lead bias: Opening paragraphs are extracted almost wholesale regardless of content.
- Structural noise ingestion: ToC entries, section headers, “link code.” artifacts, and
¶markers are treated as sentences and scored alongside prose. - Sentence-level granularity: The unit of extraction is clearly individual sentences, not passages or paragraphs.
- Confidence scores: Observed per-chunk confidence scores range from 0.1 to 1.0 representing grounding source to generative chunk relevance score.
Note: I’ve successfully fine-tuned microsoft/deberta-v3-large and it produces fairly similar results to what Google does. Here’s a demo.
Below: full pipeline diagram, raw grounding snippets, and one source article annotated to show which sentences were extracted (green) vs skipped.
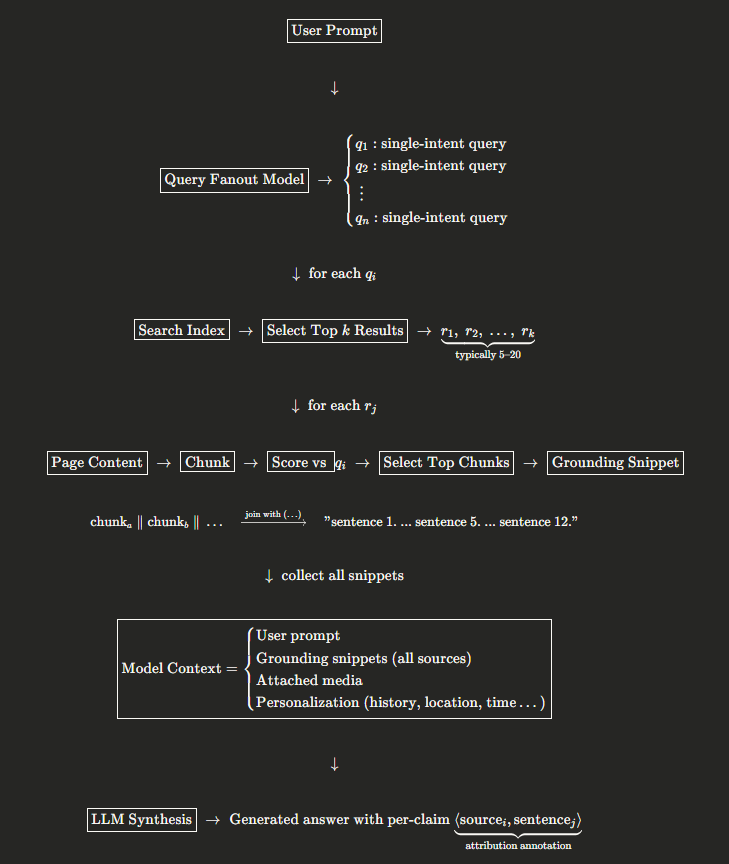
Google’s Extractive Summarization in the Grounding Pipeline
Google’s extractive summarization takes place as part of their model grounding pipeline — the system that connects Gemini’s generative output to real web sources.
When a user enters a prompt, a query fanout model deconstructs it into single-intent queries — essentially a separation of concerns where a multi-faceted prompt is broken into individual dimensions of intent.
For each fanout query, Google’s search index returns a ranked list of relevant results. A selection step narrows these down to a limited set, typically 5–20 sources per query.
Here’s where the extractive summarization happens: for each selected result, the system builds a grounding snippet relative to the specific query. Page content is chunked into sentences, each chunk is scored against the query, and the highest-scoring chunks are assembled into the final snippet — joined by ellipses (...) where non-contiguous. Because the snippet is query-dependent, the same page will yield different extractions for different fanout queries.
The complete set of grounding snippets across all sources is then supplied to the model as grounding context, alongside the user prompt, any attached media, and personalization signals (history, user data, location, time, etc.).
Once the model synthesizes its final answer, each generative claim is supported by one or more grounding sources. Attribution annotation is attached by the system using internal indexation logic — mapping each claim back to specific source sentences.
The pipeline looks like this:
Annotated Content Example
# Types of Text Summarization: Extractive and Abstractive Summarization Basics
+ Summarization is one of the most common Natural Language Processing (NLP) tasks.
+ With the amount of new content generated by billions of people and their smartphones everyday, we are inundated with increasing amount of data every day.
+ Humans can only consume a finite amount of information and need a way to filter out the wheat from the chaff and find the information that matters.
+ Text summarization can help achieve that for textual information.
+ We can separate the signal from the noise and take meaningful actions from them.
+ In this article, we explore different methods to implement this task and some of the learnings that we have come across on the way.
+ We hope this will be helpful to other folks who would like to implement basic summarization in their data science pipeline for solving different business problems.
+ Python provides some excellent libraries and modules to perform Text Summarization.
+ We will provide a simple example of generating Extractive Summarization using the Gensim and HuggingFace modules in this article.
+ ## Uses of Summarization?
+ It may be tempting to use summarization for all texts to get useful information from them and spend less time reading.
+ However, for now, NLP summarization has been a successful use case in only a few areas.
+ Text summarization works great if a text has a lot of raw facts and can be used to filter important information from them.
+ The NLP models can summarize long documents and represent them in small simpler sentences.
+ News, factsheets, and mailers fall under these categories.
+ However, for texts where each sentence builds up upon the previous, text summarization does not work that well.
+ Research journals, medical texts are good examples of texts where summarization might not be very successful.
+ Finally, if we take the case of summarizing fiction, summarization methods can work fine.
+ However, it might miss the style and the tone of the text that the author tried to express.
+ Hence, Text summarization is helpful only in a handful of use cases.
## Two Types Of Summarization
There are two main types of Text Summarization
### Extractive
+ Extractive summarization methods work just like that.
+ It takes the text, ranks all the sentences according to the understanding and relevance of the text, and presents you with the most important sentences.
+ This method does not create new words or phrases, it just takes the already existing words and phrases and presents only that.
+ You can imagine this as taking a page of text and marking the most important sentences using a highlighter.
### Abstractive
Abstractive summarization, on the other hand, tries to guess the meaning of the whole text and presents the meaning to you.
It creates words and phrases, puts them together in a meaningful way, and along with that, adds the most important facts found in the text.
This way, abstractive summarization techniques are more complex than extractive summarization techniques and are also computationally more expensive.
## Comparison with practical example
The best way to illustrate these types is through an example.
Here we have run the Input Text below through both types of summarization and the results are shown below.
### Input Text:
China's Huawei overtook Samsung Electronics as the world's biggest seller of mobile phones in the second quarter of 2020, shipping 55.8 million devices compared to Samsung's 53.7 million, according to data from research firm Canalys.
While Huawei's sales fell 5 per cent from the same quarter a year earlier, South Korea's Samsung posted a bigger drop of 30 per cent, owing to disruption from the coronavirus in key markets such as Brazil, the United States and Europe, Canalys said.
+ Huawei's overseas shipments fell 27 per cent in Q2 from a year earlier, but the company increased its dominance of the China market which has been faster to recover from COVID-19 and where it now sells over 70 per cent of its phones.
"Our business has demonstrated exceptional resilience in these difficult times," a Huawei spokesman said.
"Amidst a period of unprecedented global economic slowdown and challenges, we're continued to grow and further our leadership position." Nevertheless, Huawei's position as number one seller may prove short-lived once other markets recover given it is mainly due to economic disruption, a senior Huawei employee with knowledge of the matter told Reuters.
Apple is due to release its Q2 iPhone shipment data on Friday.
### Extractive Summarization Output:
While Huawei's sales fell 5 per cent from the same quarter a year earlier, South Korea's Samsung posted a bigger drop of 30 per cent, owing to disruption from the coronavirus in key markets such as Brazil, the United States and Europe, Canalys said.
+ Huawei's overseas shipments fell 27 per cent in Q2 from a year earlier, but the company increased its dominance of the China market which has been faster to recover from COVID-19 and where it now sells over 70 per cent of its phones.
### Abstractive Summarization Output:
Huawei overtakes Samsung as world's biggest seller of mobile phones in the second quarter of 2020.
Sales of Huawei's 55.8 million devices compared to 53.7 million for south Korea's Samsung.
Shipments overseas fell 27 per cent in Q2 from a year earlier, but company increased its dominance of the china market.
Position as number one seller may prove short-lived once other markets recover, a senior Huawei employee says.
## Extractive Text Summarization Using Gensim
Import the required libraries and functions:
from gensim.summarization.summarizer import summarize
from gensim.summarization.textcleaner import split_sentences
We store the article content in a variable called Input (mentioned above).
Next, we have to pass it to the summarize function, the second parameter being the ratio we want the summarized text to be.
We chose it as 0.4, or the summary will be around 40% of the original text.
summarize(Input, 0.4)
#### Output:
While Huawei's sales fell 5 per cent from the same quarter a year earlier, South Korea's Samsung posted a bigger drop of 30 per cent, owing to disruption from the coronavirus in key markets such as Brazil, the United States and Europe, Canalys said.
+ Huawei's overseas shipments fell 27 per cent in Q2 from a year earlier, but the company increased its dominance of the China market which has been faster to recover from COVID-19 and where it now sells over 70 per cent of its phones.
+ With the parameter split=True, you can see the output as a list of sentences.
+ Gensim summarization works with the TextRank algorithm.
+ As the name suggests, it ranks texts and gives you the most important ones back.
## Extractive Text Summarization Using Huggingface Transformers
We use the same article to summarize as before, but this time, we use a transformer model from Huggingface,
from transformers import pipeline
We have to load the pre-trained summarization model into the pipeline:
summarizer = pipeline("summarization")
Next, to use this model, we pass the text, the minimum length, and the maximum length parameters.
We get the following output:
summarizer(Input, min_length=30, max_length=300)
#### Output:
China's Huawei overtook Samsung Electronics as the world's biggest seller of mobile phones in the second quarter of 2020, shipping 55.8 million devices compared to Samsung's 53.7 million.
Samsung posted a bigger drop of 30 per cent, owing to disruption from coronavirus in key markets such as Brazil, the United States and Europe.
## Conclusion
+ We saw some quick examples of Extractive summarization, one using Gensim's TextRank algorithm, and another using Huggingface's pre-trained transformer model.
+ In further posts, we will go over LSTM, BERT, and Google's T5 transformer models in-depth and look at how they work to do tasks such as abstractive summarization.Full Grounding Context Example
SearchResults(
query="examples of extractive summarization",
results=[
PerQueryResult(
index="1",
source_title="Getting to the Point: The Benefits of Extractive Summarization | by Puja Chaudhury | Medium",
url="https://catplotlib.medium.com/in-the-field-of-natural-language-processing-nlp-summarization-plays-a-crucial-role-in-reducing-519af0432d96",
sentences=[
"Extractive summarization is a method of summarizing a text document by selecting basic sentences or phrases from the original text and concatenating them to form a summary.",
"It does not create new phrases or sentences but instead selects the most significant content from the original text.",
"Examples of extractive summarization include news articles, summaries of legal documents, and scientific papers.",
"We will be performing extractive summarization of text using GloVe, a pre-trained word embedding model.",
# ... 24 more sentences
]
),
PerQueryResult(
index="2",
source_title="Types of Text Summarization: Extractive and Abstractive Summarization Basics - Turbolab Technologies",
url="https://turbolab.in/types-of-text-summarization-extractive-and-abstractive-summarization-basics/",
sentences=[
"We saw some quick examples of Extractive summarization, one using Gensim's TextRank algorithm, and another using Huggingface's pre-trained transformer model.",
"In further posts, we will go over LSTM, BERT, and Google's T5 transformer models in-depth and look at how they work to do tasks such as abstractive summarization.",
"Summarization is one of the most common Natural Language Processing (NLP) tasks.",
"With the amount of new content generated by billions of people and their smartphones everyday, we are inundated with increasing amount of data every day.",
"Humans can only consume a finite amount of information and need a way to filter out the wheat from the chaff and find the information that matters.",
"Text summarization can help achieve that for textual information.",
"We can separate the signal from the noise and take meaningful actions from them.",
"In this article, we explore different methods to implement this task and some of the learnings that we have come across on the way.",
"We hope this will be helpful to other folks who would like to implement basic summarization in their data science pipeline for solving different business problems.",
"Python provides some excellent libraries and modules to perform Text Summarization.",
"We will provide a simple example of generating Extractive Summarization using the Gensim and HuggingFace modules in this article.",
"Uses of Summarization?",
"It may be tempting to use summarization for all texts to get useful information from them and spend less time reading.",
"However, for now, NLP summarization has been a successful use case in only a few areas.",
"Text summarization works great if a text has a lot of raw facts and can be used to filter important information from them.",
"The NLP models can summarize long documents and represent them in small simpler sentences.",
"News, factsheets, and mailers fall under these categories.",
"However, for texts where each sentence builds up upon the previous, text summarization does not work that well.",
"Research journals, medical texts are good examples of texts where summarization might not be very successful.",
"Finally, if we take the case of summarizing fiction, summarization methods can work fine.",
"However, it might miss the style and the tone of the text that the author tried to express.",
"Hence, Text summarization is helpful only in a ...",
"Extractive summarization methods work just like that.",
"It takes the text, ranks all the sentences according to the understanding and relevance of the text, and presents you with the most important sentences.",
"This method does not create new words or phrases, it just takes the already existing words and phrases and presents only that.",
"You can imagine this as taking a page of text and marking the most important sentences using a highlighter.",
"Huawei's overseas shipments fell 27 per cent in Q2 from a year earlier, but the company increased its dominance of the China market which has been faster to recover from COVID-19 and where it now sells over 70 per cent of its phones.",
"With the parameter split=True, you can see the output as a list of sentences.",
"Gensim summarization works with the TextRank algorithm.",
"As the name suggests, it ranks texts and gives you the most important ones back."
]
),
PerQueryResult(
index="3",
source_title="Text Summarization | Extractive| BLEU - Kaggle",
url="https://www.kaggle.com/code/vshantam/text-summarization-extractive-bleu",
sentences=[
"Following methods are the technique of extractive text summarization.",
"Term frequency (TF) and the inverse document frequency (IDF) are numerical statistics presents how important a word in a given document.",
"Text summarization involves creating a shorter version of a text that retains its key information.",
"Extractive summarization is easier to implement and can be done quickly using an unsupervised approach that does not require prior training.",
# ... 37 more sentences
]
),
PerQueryResult(
index="4",
source_title="Exploring the Extractive Method of Text Summarization - Analytics Vidhya",
url="https://www.analyticsvidhya.com/blog/2023/03/exploring-the-extractive-method-of-text-summarization/",
sentences=[
"This is where NLP text summarization comes into play, which is a technique that automatically generates a condensed version of a given text while preserving its essential meaning.",
"It simply takes out the important sentences or phrases from the original text and joins them to form a summary.",
"So, a ranking algorithm is used, which assigns scores to each sentence in the text based on their relevance to the overall meaning of the document.",
"The ROUGE score measures the similarity between the generated and reference summaries.",
# ... 41 more sentences
]
),
PerQueryResult(
index="5",
source_title="Introduction to Extractive and Abstractive Summarization Techniques - DigitalOcean",
url="https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques",
sentences=[
"The process of extractive summarizing involves picking the most relevant sentences from an article and systematically organizing them.",
"The sentences making up the summary are taken verbatim from the source material.",
"To generate a summary, the summarizer software picks the top k sentences.",
"Topic Representation Approaches.",
# ... 28 more sentences
]
),
]
)
Leave a Reply