
This is the story of how AI transitioned from niche to mainstream and the pieces that fell into place to make that happen.
Picture this. It’s 2017, we’re in the era dominated by Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN), LSTM is cutting edge. These models are tiny, and the common wisdom is that overparameterized models don’t generalize well because they memorize everything. Then the transformers paper just came out and one year later, GPT-1.
768
In 2018, Alec Radford decided GPT-1 would have 12 layers and 768 dimensions. Why? At that size, the model would fit on his dev box and training would take about a month, which was at the edge of his patience.
That’s it. No other reason.
Google then went, “oh cool,” and trained BERT.
Guess how many dimensions?

“BERT BASE was chosen to have the same model size as OpenAI GPT for comparison purposes.”
Both these models were so small they’d fit on your laptop and run just fine. Because who in their right mind would go against common sense and purposely overparameterize a model to see what happens? Right?

DOUBLE DESCENT
The first time I heard of his paper was from this 2019 video which flags it as ‘really interesting’ but the concept completely blew my mind.
It goes something like this…
- A small model learns a bit.
- A larger model learns a bit more.
- A very large model learns everything* (this is bad).
*It’s called overfitting and it’s like memorizing everything for the exam but not being able to apply the knowledge outside of the exact exam material.
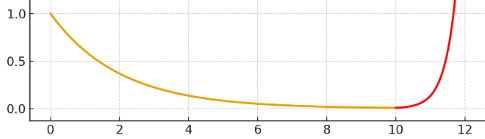
Then Mikhail goes, “to hell with it, let’s keep going see what happens, like whatever”, but he said it using smart words computer scientists use in their papers that sound like “bias variance trade-off curve” and so on.
And then this happens!!1 🤯
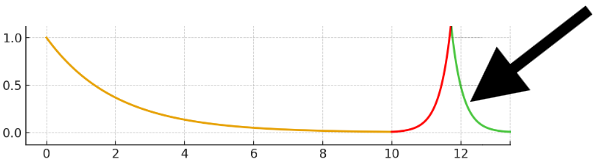
And it was this precise EUREKA! moment that kickstarted the new AI revolution. Both Google and OpenAI now knew that scaling models is in facts possible, and that’s all then needed, the reassurance that it can be done.
Alright, cool what happens next?
OpenAI is like… what if we go crazy big? So they go from 117M to 1.5B parameters. Lunatics! This demonstrates emergent abilities, sparks debate about release. Google’s taking notes.
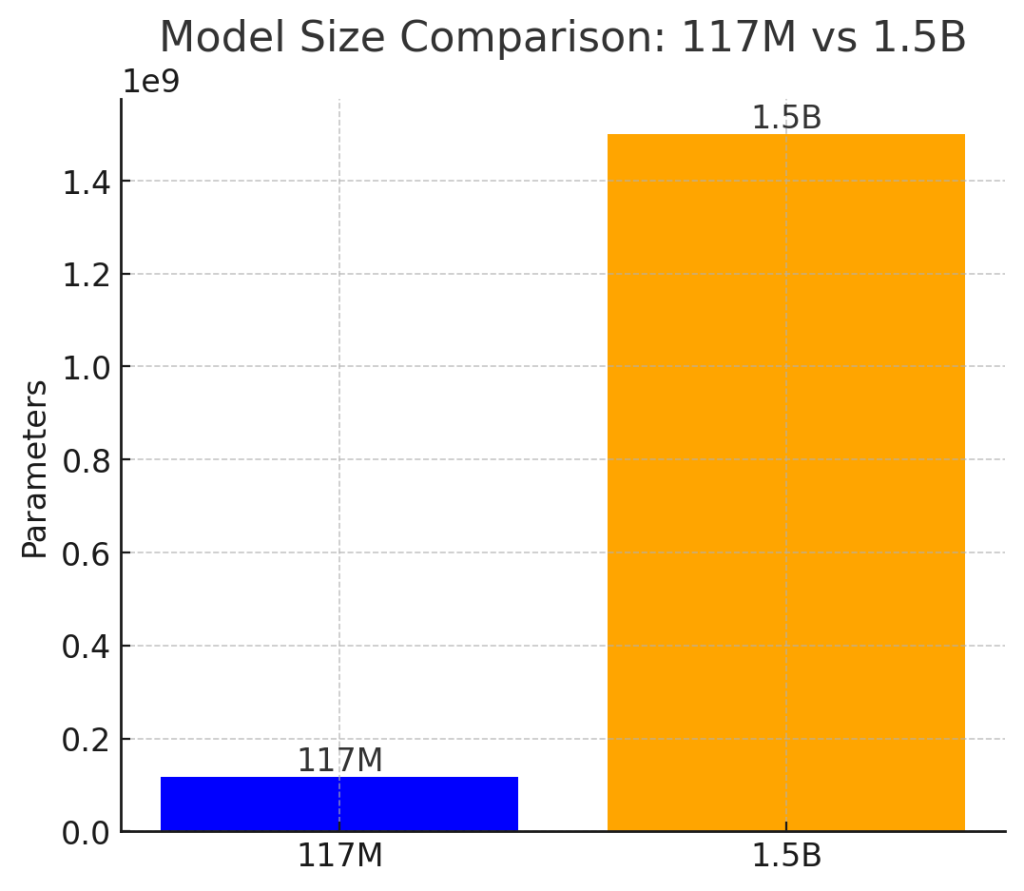
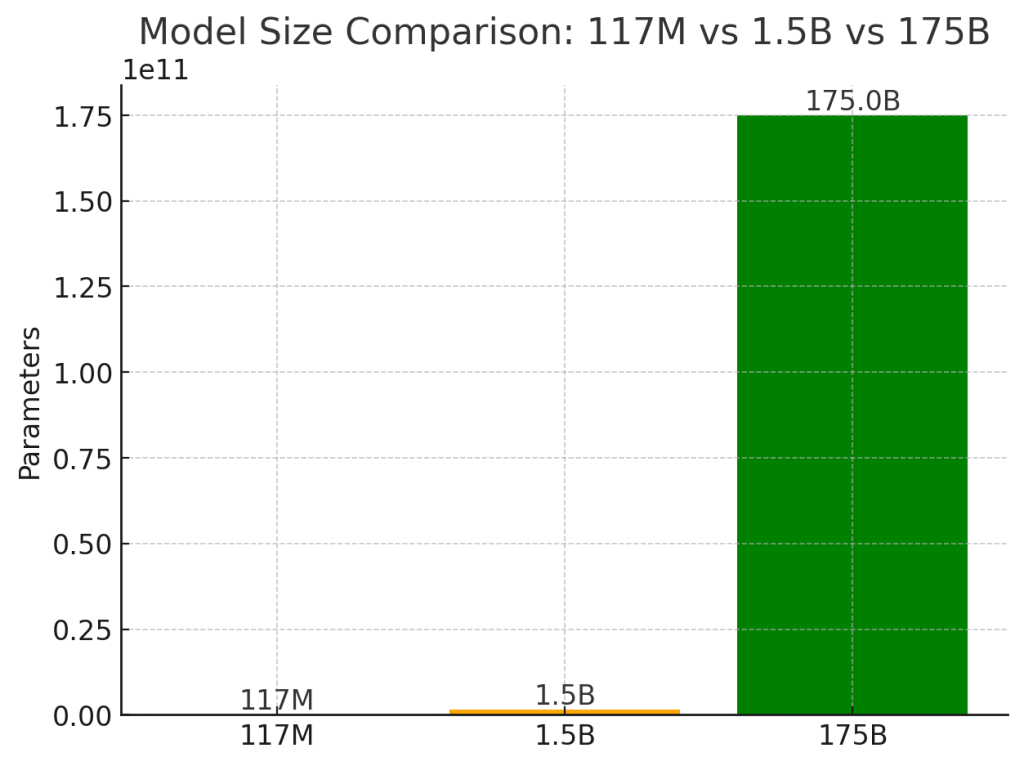
Why stop there, keep going!
June 2020 | GPT-3 (175B params) – Shows in-context learning, few-shot capabilities.
The Million Model Explosion
The double descent paper was the spark which ignited the million model explosion.
2021-2024 | Explosion: T5, PaLM, ChatGPT, GPT-4, Claude, Llama, Gemini, and countless others.
The ~3 year period from 2017-2020 completely transformed NLP, and the architecture has since conquered vision (ViT), protein folding (AlphaFold), and basically every domain that involves sequences or sets.
Leave a Reply