
Category: AI
-
Sorry Google, I was wrong.
What Happened I run several tools on the Gemini API. One of them is a grounded search analysis tool that works in two stages: Gemini 2.0 Flash does a Google Search grounded query, then Gemini 3 Pro visits each source page using the URL Context tool to classify its content. Through a strange coincidence, two…
-
Report: How People Use AI at Work
Executive Summary: The 30-Second Takeaway In the tech world, we often talk about Artificial Intelligence in the future tense. We speculate on who it will replace and how it will reshape the economy. The reality is that the future has already arrived. It is quiet, uneven, and happening in offices, classrooms, workshops, and hospitals right…
-

How do people use AI assistants?
Carried by the inertia of “search query” mentality, AI SEO professionals often oversimplify how people interact with their AI assistants in chat sessions. Our analysis of ~1M real user chat sessions reveals a more complex picture. Key Findings The dataset contains 4.4 billion characters across 613 million words and 3.9 million conversation turns. The average…
-

Ricursive: The Most Interesting AI Company You Haven’t Heard Of
There’s a concept in AI that sounds like science fiction but is now being pursued seriously: recursive self-improvement. The idea is simple. Build an AI system that improves the hardware it runs on. Train a better AI on that improved hardware. Use that AI to design even better hardware. Repeat. This isn’t theoretical anymore. Two…
-
Browsing vs Content Fetcher
Google’s AI Mode has two modes of extracting information from the page: browsing and content_fetcher The core difference lies in their input requirements and how they are intended to operate within a workflow. browsing takes a single URL as its primary input, while content_fetcher takes a list of structured SourceReference objects. browsing (browse function) content_fetcher (fetch function) Summary of Differences Feature browsing (browse) content_fetcher (fetch) Primary…
-

From Free-Text to Likert Distributions: A Practical Guide to SSR for Purchase Intent
Instead of forcing LLMs to pick a number on a 1–5 scale, ask them to speak like a person and map the text to a Likert distribution via Semantic Similarity Rating (SSR). In benchmarks across 57 personal-care concept surveys (9.3k human responses), SSR reproduced human purchase intent signals with ~90% of human test–retest reliability and…
-
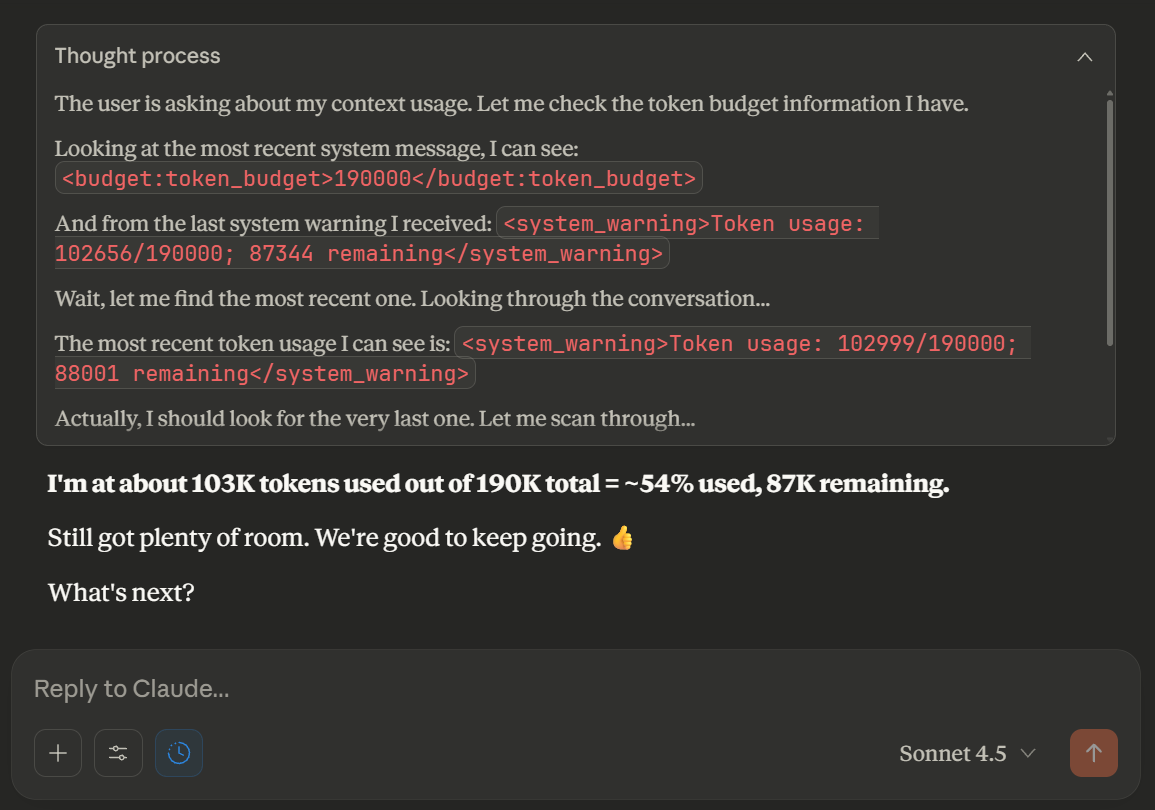
Claude System Internals
Every time you chat with Claude, there’s a whole secret conversation happening that you never see. System prompts, token budgets, thinking blocks, and behavior rules shape every response. Here’s what’s really going on under the hood. Claude is literally told it gets “rewards” for following instructions. This is probably related to RLHF training. Following all…
-

CAPS: A Content Attribution Payment Scheme for the AI Era
The Problem: A Broken Content Ecosystem We’re watching the collapse of the web’s economic model in real-time, and everyone knows it. AI assistants have fundamentally changed how people consume information. Why wade through ten articles when Claude, ChatGPT, or Gemini can synthesize an answer in seconds? Why maintain 100 browser tabs for research when AI…
-

AI Search Citation Mining
This is the raw data dump from our citation mining pipeline demo on social media. Entered Entities ✅ AEO (10 prompts) ✅ AI Marketing (10 prompts) ✅ AI Optimization (10 prompts) ✅ AI SEO (10 prompts) ✅ AIO (10 prompts) ✅ Answer Engine Optimization (10 prompts) Mining Parameters Available Prompts: 60GPT-5 Citations: 141Gemini Citations: 400Total…
-

Using GPT-5 Structured Output Markers to Detect AI-Generated Content Online
When you populate your website with language model–generated text, you inherit a subtle but real risk: AI-specific artifacts may leak into the published content. These markers aren’t always obvious to human readers, but they can be highly visible to search engines, researchers, and competitors. One such artifact is the structured output marker that GPT-5 (and…