
TL;DR
- Chrome’s latest update incorporates a new text embedding model that is 57% smaller (35.14MB vs 81.91MB) than its predecessor while maintaining virtually identical performance in semantic search tasks.
- The size reduction was achieved primarily through quantization of the embedding matrix from float32 to int8 precision, with no measurable degradation in embedding quality or search ranking.
Discovery and Extraction
During routine analysis of Chrome’s binary components, I discovered a new version of the embedding model in the browser’s optimization guide directory. This model is used for history clustering and semantic search.
Model directory:
~/AppData/Local/Google/Chrome SxS/User Data/optimization_guide_model_store/57/A3BFD4A403A877EC/Technical Analysis Methodology
To analyze the models, I developed a multi-faceted testing approach:
- Model Structure Analysis: Used TensorFlow’s interpreter to extract model architecture, tensor counts, shapes, and data types.
- Binary Comparison: Analyzed compression ratios, binary patterns, and weight distributions.
- Weight Quantization Assessment: Examined specific tensors to determine quantization techniques.
- Output Precision Testing: Estimated effective precision of output embeddings by analyzing minimum differences between adjacent values.
- Semantic Search Evaluation: Compared similarity scores and result rankings across multiple queries using a test corpus.
Key Findings
1. Architecture Comparison
Both models maintain identical architecture with similar tensor counts (611 vs. 606) and identical input/output shapes ([1,64] input and [1,768] output). This suggests they were derived from the same base model, likely a transformer-based embedding architecture similar to BERT.
2. Quantization Details
The primary difference is in the embedding matrix, which stores token representations:
- Old model:
arith.constant30: [32128, 512], <class 'numpy.float32'>, 62.75 MB - New model:
tfl.pseudo_qconst57: [32128, 512], <class 'numpy.int8'>, 15.69 MB
This single tensor accounts for approximately 47MB of the total 46.77MB size reduction. The model contains 58 pseudo-quantized tensors in both versions, but the critical embedding matrix was converted from float32 to int8.
3. Output Precision Analysis
Despite internal quantization, the new model’s output embeddings maintain full float32 precision:
- Old model: Estimated bits of precision = 22.59 bits
- New model: Estimated bits of precision = 25.42 bits
Intriguingly, the new model shows slightly higher effective precision, suggesting sophisticated quantization-aware training techniques.
4. Semantic Search Performance
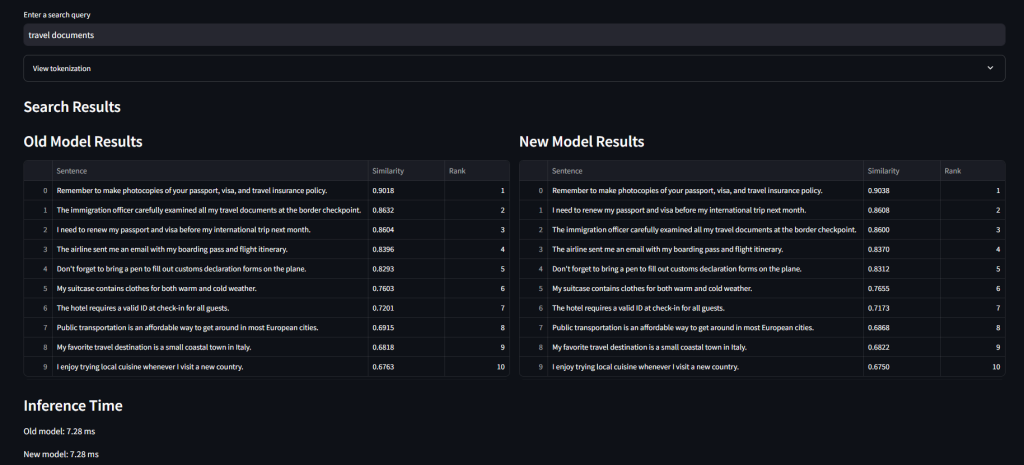
Testing on diverse queries (e.g. “climate solutions”, “machine learning applications”, “travel documents”) showed:
- Virtually identical similarity scores (differences of 0.001-0.004)
- Identical result rankings for most queries
- Slight speed improvement (1-2% faster inference)
Binary Structure Analysis
Detailed comparison of the binary files revealed:
- 60% reduction in int8 zero bytes but 48.5% increase in float32 zero bytes
- 53.3% increase in runs of zeros, indicating different storage strategies
- Float tensor size reduction from 67.33MB to 5.05MB
- Both models have similar compression ratios when further compressed (1.10x vs. 1.11x)
Implications
This optimization represents a significant achievement in model compression for edge devices. By selectively quantizing the largest tensor while preserving the architecture and output precision, Chrome’s engineers have achieved a substantial size reduction without compromising semantic search quality.
The approach demonstrates how selective quantization of specific model components can be more effective than blanket quantization strategies. This technique is particularly valuable for browsers and other edge applications where storage efficiency is critical but performance cannot be sacrificed.
The slightly higher effective precision in the output layer suggests the quantization process may have included fine-tuning to compensate for potential precision loss, resulting in a model that maintains or even slightly improves embedding quality.
User Impact and Benefits
This optimization delivers several tangible benefits for Chrome users:
- Reduced Storage Footprint: The 46.77MB size reduction frees up valuable storage space, particularly important on devices with limited capacity like budget smartphones and tablets.
- Faster Browser Updates: Smaller ML models result in smaller browser updates, reducing download times and data usage during Chrome’s update process.
- Improved Resource Efficiency: The slightly faster inference time (1-2%) contributes to more responsive browser performance when using features that rely on the embedding model, such as history search and content clustering.
- Consistent Quality: Users receive these storage and performance benefits with no degradation in search quality or content understanding capabilities.
- Battery Life Considerations: The reduced computational demands from the smaller model may contribute to marginally improved battery life on mobile devices during extended browsing sessions.
Acknowledgements
This article is AI augmented using Claude for both code and writing with human direction and curation.
TFLite Weight Inspector – Load a TensorFlow Lite model, extract a sample of its weight tensors (constants), compute basic statistics (min/max/mean/std) and sample values, print the results, and optionally save them to a JSON file.
import numpy as np
import tensorflow as tf
import os
def extract_weights(model_path, num_samples=10):
"""
Extract weights from a TFLite model using the interpreter.
Args:
model_path: Path to the TFLite model
num_samples: Number of weight tensors to show
Returns:
Dictionary of weight tensors
"""
# Check if model exists
if not os.path.exists(model_path):
print(f"Error: Model file '{model_path}' not found.")
return {}
# Load the TFLite model
interpreter = tf.lite.Interpreter(model_path=model_path)
interpreter.allocate_tensors()
# Get tensor details
tensor_details = interpreter.get_tensor_details()
# Filter for likely weight tensors (constants)
weight_tensors = [t for t in tensor_details if (
t['name'].startswith('tfl.pseudo_qconst') or
t['name'].startswith('arith.constant')
)]
# If we didn't find enough weight tensors, include other constants
if len(weight_tensors) < num_samples:
# Look for more tensors that might be weights
other_tensors = [t for t in tensor_details if (
not t['name'].startswith('serving_default') and
not t['name'].startswith('StatefulPartitionedCall') and
t not in weight_tensors
)]
weight_tensors.extend(other_tensors)
# Limit to num_samples
weight_tensors = weight_tensors[:num_samples]
# Extract weights
weights = {}
for tensor in weight_tensors:
tensor_name = tensor['name']
tensor_index = tensor['index']
try:
# Try to access the tensor data
tensor_data = interpreter.get_tensor(tensor_index)
# Store basic info
weights[tensor_name] = {
'index': tensor_index,
'shape': tensor['shape'],
'dtype': str(tensor['dtype']),
'data_sample': tensor_data.flatten()[:10].tolist() if tensor_data.size > 0 else [],
'min': float(np.min(tensor_data)) if tensor_data.size > 0 else None,
'max': float(np.max(tensor_data)) if tensor_data.size > 0 else None,
'mean': float(np.mean(tensor_data)) if tensor_data.size > 0 else None,
'std': float(np.std(tensor_data)) if tensor_data.size > 0 else None
}
except Exception as e:
print(f"Could not access tensor {tensor_name} (index {tensor_index}): {e}")
# Try a different approach for this tensor
try:
# Some tensors might not be directly accessible but can be
# accessed through the tensor() method
tensor_data = interpreter.tensor(tensor_index)()
weights[tensor_name] = {
'index': tensor_index,
'shape': tensor['shape'],
'dtype': str(tensor['dtype']),
'data_sample': tensor_data.flatten()[:10].tolist() if tensor_data.size > 0 else [],
'min': float(np.min(tensor_data)) if tensor_data.size > 0 else None,
'max': float(np.max(tensor_data)) if tensor_data.size > 0 else None,
'mean': float(np.mean(tensor_data)) if tensor_data.size > 0 else None,
'std': float(np.std(tensor_data)) if tensor_data.size > 0 else None
}
except Exception as e2:
print(f" Alternative method also failed: {e2}")
return weights
def print_weight_info(weights):
"""Print information about the extracted weights."""
print(f"Extracted {len(weights)} weight tensors:")
print("-" * 80)
for name, info in weights.items():
print(f"Tensor Name: {name}")
print(f" Index: {info['index']}")
print(f" Shape: {info['shape']}")
print(f" Data Type: {info['dtype']}")
if info['min'] is not None:
print(f" Statistics:")
print(f" Min: {info['min']}")
print(f" Max: {info['max']}")
print(f" Mean: {info['mean']}")
print(f" Std: {info['std']}")
if info['data_sample']:
print(f" Data Sample (first few values):")
print(f" {info['data_sample']}")
print("-" * 80)
if __name__ == "__main__":
model_path = "old.tflite" # Path to your TFLite model
# Extract weights
weights = extract_weights(model_path, num_samples=10)
# Print information
print_weight_info(weights)
# Save results to a file (optional)
if len(weights) > 0:
try:
import json
# Convert np arrays to lists for JSON serialization
with open("weight_samples.json", "w") as f:
json.dump(weights, f, indent=2)
print("Weight samples saved to weight_samples.json")
except Exception as e:
print(f"Error saving to JSON: {e}")Extracted 10 weight tensors:
Tensor Name: arith.constant
Index: 1
Shape: [2]
Data Type:
Statistics:
Min: 1.0
Max: 64.0
Mean: 32.5
Std: 31.5
Data Sample (first few values):
[1, 64]
Tensor Name: arith.constant1
Index: 2
Shape: [2]
Data Type:
Statistics:
Min: 0.0
Max: 0.0
Mean: 0.0
Std: 0.0
Data Sample (first few values):
[0, 0]
Tensor Name: arith.constant2
Index: 3
Shape: []
Data Type:
Statistics:
Min: 0.5
Max: 0.5
Mean: 0.5
Std: 0.0
Data Sample (first few values):
[0.5]
Tensor Name: arith.constant3
Index: 4
Shape: []
Data Type:
Statistics:
Min: 1.0
Max: 1.0
Mean: 1.0
Std: 0.0
Data Sample (first few values):
[1.0]
Tensor Name: arith.constant4
Index: 5
Shape: []
Data Type:
Statistics:
Min: 0.7978845834732056
Max: 0.7978845834732056
Mean: 0.7978845834732056
Std: 0.0
Data Sample (first few values):
[0.7978845834732056]
Tensor Name: arith.constant5
Index: 6
Shape: []
Data Type:
Statistics:
Min: 0.044714998453855515
Max: 0.044714998453855515
Mean: 0.044714998453855515
Std: 0.0
Data Sample (first few values):
[0.044714998453855515]
Tensor Name: arith.constant6
Index: 7
Shape: [ 1 1 64 64]
Data Type:
Statistics:
Min: -10000000000.0
Max: -10000000000.0
Mean: -10000001024.0
Std: 1024.0
Data Sample (first few values):
[-10000000000.0, -10000000000.0, -10000000000.0, -10000000000.0, -10000000000.0, -10000000000.0, -10000000000.0, -10000000000.0, -10000000000.0, -10000000000.0]
Tensor Name: arith.constant7
Index: 8
Shape: [ 1 1 64 64]
Data Type:
Statistics:
Min: 0.0
Max: 0.0
Mean: 0.0
Std: 0.0
Data Sample (first few values):
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]
Tensor Name: arith.constant8
Index: 9
Shape: []
Data Type:
Statistics:
Min: 9.999999974752427e-07
Max: 9.999999974752427e-07
Mean: 9.999999974752427e-07
Std: 0.0
Data Sample (first few values):
[9.999999974752427e-07]
Tensor Name: arith.constant9
Index: 10
Shape: []
Data Type:
Statistics:
Min: 512.0
Max: 512.0
Mean: 512.0
Std: 0.0
Data Sample (first few values):
[512.0]
TFLite Model Comparator – Analyze and compare two TFLite models in terms of file size, tensor count/types/shapes, input/output specs, quantization stats, and a sample tensor’s data and quantization details.
import tensorflow as tf
import numpy as np
import os
def analyze_tflite_model(model_path):
"""Analyze a TFLite model and extract key information."""
# Check if model exists
if not os.path.exists(model_path):
print(f"Error: Model file '{model_path}' not found.")
return None
# Load the TFLite model
interpreter = tf.lite.Interpreter(model_path=model_path)
interpreter.allocate_tensors()
# Get basic info
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
tensor_details = interpreter.get_tensor_details()
# Analyze tensor types
tensor_types = {}
tensor_shapes = {}
quantized_tensors = 0
for tensor in tensor_details:
dtype = str(tensor['dtype'])
if dtype in tensor_types:
tensor_types[dtype] += 1
else:
tensor_types[dtype] = 1
# Track shape distribution
shape_size = np.prod(tensor['shape']) if tensor['shape'].size > 0 else 0
shape_range = None
if shape_size == 0:
shape_range = "empty"
elif shape_size == 1:
shape_range = "scalar"
elif shape_size < 100:
shape_range = "small"
elif shape_size < 10000:
shape_range = "medium"
else:
shape_range = "large"
if shape_range in tensor_shapes:
tensor_shapes[shape_range] += 1
else:
tensor_shapes[shape_range] = 1
# Check if it's a quantized tensor
if 'quantization' in tensor and (tensor['quantization'][0] != 0.0 or tensor['quantization'][1] != 0):
quantized_tensors += 1
# Count pseudo-quant tensors
pseudo_quant_tensors = sum(1 for t in tensor_details if 'pseudo_qconst' in t['name'])
# Get model file size
file_size = os.path.getsize(model_path) / (1024 * 1024) # in MB
# Extract a sample of weights to check quantization
sample_tensors = {}
quant_pattern_tensors = [t for t in tensor_details if 'pseudo_qconst' in t['name']]
if quant_pattern_tensors:
# Take up to 5 samples
for i, tensor in enumerate(quant_pattern_tensors[:5]):
try:
tensor_data = interpreter.get_tensor(tensor['index'])
sample_tensors[tensor['name']] = {
'index': tensor['index'],
'shape': tensor['shape'].tolist(),
'dtype': str(tensor['dtype']),
'quantization': {
'scale': float(tensor['quantization'][0]) if tensor['quantization'][0] != 0.0 else 0,
'zero_point': int(tensor['quantization'][1])
},
'data_sample': tensor_data.flatten()[:5].tolist() if tensor_data.size > 0 else []
}
except Exception as e:
print(f"Could not access tensor {tensor['name']}: {e}")
return {
'file_size': file_size,
'input_details': [{
'name': d['name'],
'shape': d['shape'].tolist(),
'dtype': str(d['dtype'])
} for d in input_details],
'output_details': [{
'name': d['name'],
'shape': d['shape'].tolist(),
'dtype': str(d['dtype'])
} for d in output_details],
'total_tensors': len(tensor_details),
'tensor_types': tensor_types,
'tensor_shapes': tensor_shapes,
'quantized_tensors': quantized_tensors,
'pseudo_quant_tensors': pseudo_quant_tensors,
'sample_tensors': sample_tensors
}
def compare_models(old_model_path, new_model_path):
"""Compare two TFLite models and identify differences."""
old_info = analyze_tflite_model(old_model_path)
new_info = analyze_tflite_model(new_model_path)
if not old_info or not new_info:
return
print("=== Model Comparison ===")
print(f"Old model size: {old_info['file_size']:.2f} MB")
print(f"New model size: {new_info['file_size']:.2f} MB")
print(f"Size reduction: {old_info['file_size'] - new_info['file_size']:.2f} MB " +
f"({(1 - new_info['file_size']/old_info['file_size']) * 100:.1f}%)")
print("\n--- Architecture ---")
print(f"Old model tensors: {old_info['total_tensors']}")
print(f"New model tensors: {new_info['total_tensors']}")
print("\n--- Input/Output ---")
print("Old model input:", old_info['input_details'][0]['shape'] if old_info['input_details'] else "None")
print("New model input:", new_info['input_details'][0]['shape'] if new_info['input_details'] else "None")
print("Old model output:", old_info['output_details'][0]['shape'] if old_info['output_details'] else "None")
print("New model output:", new_info['output_details'][0]['shape'] if new_info['output_details'] else "None")
print("\n--- Tensor Types ---")
print("Old model types:", old_info['tensor_types'])
print("New model types:", new_info['tensor_types'])
print("\n--- Quantization ---")
print(f"Old model quantized tensors: {old_info['quantized_tensors']} ({old_info['pseudo_quant_tensors']} pseudo-quant)")
print(f"New model quantized tensors: {new_info['quantized_tensors']} ({new_info['pseudo_quant_tensors']} pseudo-quant)")
print("\n--- Tensor Shapes ---")
print("Old model shape distribution:", old_info['tensor_shapes'])
print("New model shape distribution:", new_info['tensor_shapes'])
print("\n--- Sample Tensors ---")
if old_info['sample_tensors'] and new_info['sample_tensors']:
old_sample = next(iter(old_info['sample_tensors'].values()))
new_sample = next(iter(new_info['sample_tensors'].values()))
print("Old model sample tensor:")
print(f" Shape: {old_sample['shape']}")
print(f" Dtype: {old_sample['dtype']}")
print(f" Quantization: scale={old_sample['quantization']['scale']}, zero_point={old_sample['quantization']['zero_point']}")
print(f" Data sample: {old_sample['data_sample']}")
print("New model sample tensor:")
print(f" Shape: {new_sample['shape']}")
print(f" Dtype: {new_sample['dtype']}")
print(f" Quantization: scale={new_sample['quantization']['scale']}, zero_point={new_sample['quantization']['zero_point']}")
print(f" Data sample: {new_sample['data_sample']}")
if __name__ == "__main__":
old_model_path = "old.tflite"
new_model_path = "new.tflite"
compare_models(old_model_path, new_model_path)
=== Model Comparison ===
Old model size: 81.91 MB
New model size: 35.14 MB
Size reduction: 46.77 MB (57.1%)
--- Architecture ---
Old model tensors: 611
New model tensors: 606
--- Input/Output ---
Old model input: [1, 64]
New model input: [1, 64]
Old model output: [1, 768]
New model output: [1, 768]
--- Tensor Types ---
Old model types: {"<class 'numpy.int32'>": 69, "<class 'numpy.float32'>": 477, "<class 'numpy.int8'>": 58, "<class 'numpy.bool'>": 7}
New model types: {"<class 'numpy.int32'>": 70, "<class 'numpy.float32'>": 471, "<class 'numpy.bool'>": 7, "<class 'numpy.int8'>": 58}
--- Quantization ---
Old model quantized tensors: 0 (58 pseudo-quant)
New model quantized tensors: 0 (58 pseudo-quant)
--- Tensor Shapes ---
Old model shape distribution: {'small': 151, 'empty': 7, 'medium': 31, 'scalar': 34, 'large': 388}
New model shape distribution: {'small': 150, 'empty': 10, 'scalar': 34, 'large': 383, 'medium': 29}
--- Sample Tensors ---
Old model sample tensor:
Shape: [768, 512]
Dtype: <class 'numpy.int8'>
Quantization: scale=0, zero_point=0
Data sample: [127, -28, 14, -27, -70]
New model sample tensor:
Shape: [768, 512]
Dtype: <class 'numpy.int8'>
Quantization: scale=0, zero_point=0
Data sample: [127, -28, 14, -27, -70]TFLite Compression Analyzer – Perform an in-depth binary and weight-level comparison between two TFLite models, covering file size, compression efficiency, zero-pattern frequencies, weight tensor sparsity, and changes in large tensor storage and distribution.
import tensorflow as tf
import numpy as np
import os
import zlib
import struct
def analyze_compression(model_path):
"""Analyze the compressibility of a TFLite model."""
with open(model_path, 'rb') as f:
data = f.read()
compressed = zlib.compress(data, level=9)
return {
'original_size': len(data),
'compressed_size': len(compressed),
'compression_ratio': len(data) / len(compressed)
}
def extract_all_weights(model_path):
"""Extract all weight tensors from model for detailed analysis."""
# Load the TFLite model
interpreter = tf.lite.Interpreter(model_path=model_path)
interpreter.allocate_tensors()
# Get tensor details
tensor_details = interpreter.get_tensor_details()
# Extract all weights
weights = {}
for tensor in tensor_details:
try:
tensor_data = interpreter.get_tensor(tensor['index'])
# Calculate basic statistics
tensor_size = tensor_data.size * tensor_data.itemsize # size in bytes
non_zero = np.count_nonzero(tensor_data)
sparsity = 1.0 - (non_zero / tensor_data.size) if tensor_data.size > 0 else 0
weights[tensor['name']] = {
'index': tensor['index'],
'shape': tensor['shape'].tolist(),
'dtype': str(tensor['dtype']),
'size_bytes': tensor_size,
'non_zero_count': int(non_zero),
'sparsity': float(sparsity),
'min': float(np.min(tensor_data)) if tensor_data.size > 0 else None,
'max': float(np.max(tensor_data)) if tensor_data.size > 0 else None
}
except Exception as e:
# Some tensors might not be accessible
continue
return weights
def analyze_tflite_binary(model_path):
"""Analyze the binary structure of the TFLite file."""
with open(model_path, 'rb') as f:
data = f.read()
# Count occurrences of common patterns
patterns = {
'float32': struct.pack('<f', 0.0), # Float32 zero
'int8': struct.pack('<b', 0), # Int8 zero
'runs_of_zeros': b'\x00\x00\x00\x00\x00\x00\x00\x00' # 8 consecutive zeros
}
counts = {}
for name, pattern in patterns.items():
counts[name] = data.count(pattern)
return counts
def detailed_model_comparison(old_model_path, new_model_path):
"""Perform a detailed comparison of the models."""
# Get basic info
old_size = os.path.getsize(old_model_path)
new_size = os.path.getsize(new_model_path)
# Analyze compression
old_compression = analyze_compression(old_model_path)
new_compression = analyze_compression(new_model_path)
# Analyze binary patterns
old_patterns = analyze_tflite_binary(old_model_path)
new_patterns = analyze_tflite_binary(new_model_path)
# Extract all weights for statistics
old_weights = extract_all_weights(old_model_path)
new_weights = extract_all_weights(new_model_path)
# Calculate overall statistics
old_total_bytes = sum(w['size_bytes'] for w in old_weights.values())
new_total_bytes = sum(w['size_bytes'] for w in new_weights.values())
old_sparsity = sum(w['sparsity'] * w['size_bytes'] for w in old_weights.values()) / old_total_bytes if old_total_bytes > 0 else 0
new_sparsity = sum(w['sparsity'] * w['size_bytes'] for w in new_weights.values()) / new_total_bytes if new_total_bytes > 0 else 0
# Print results
print("=== Detailed Model Comparison ===")
print(f"Old model size: {old_size / (1024*1024):.2f} MB")
print(f"New model size: {new_size / (1024*1024):.2f} MB")
print(f"Size reduction: {(old_size - new_size) / (1024*1024):.2f} MB ({(1 - new_size/old_size) * 100:.1f}%)")
print("\n--- Compression Analysis ---")
print(f"Old model compression ratio: {old_compression['compression_ratio']:.2f}x")
print(f"New model compression ratio: {new_compression['compression_ratio']:.2f}x")
print("\n--- Binary Patterns ---")
for pattern in old_patterns:
old_count = old_patterns[pattern]
new_count = new_patterns[pattern]
change = new_count - old_count
print(f"{pattern}: {old_count} → {new_count} ({change:+d}, {(change/old_count*100 if old_count else 0):.1f}%)")
print("\n--- Weight Statistics ---")
print(f"Old model weights: {len(old_weights)} tensors, {old_total_bytes / (1024*1024):.2f} MB total")
print(f"New model weights: {len(new_weights)} tensors, {new_total_bytes / (1024*1024):.2f} MB total")
print(f"Old model average sparsity: {old_sparsity:.2%}")
print(f"New model average sparsity: {new_sparsity:.2%}")
# Analyze weight distributions
old_float_tensors = {k: v for k, v in old_weights.items() if "float" in v['dtype']}
new_float_tensors = {k: v for k, v in new_weights.items() if "float" in v['dtype']}
print("\n--- Float Tensor Analysis ---")
print(f"Old model float tensors: {len(old_float_tensors)}, {sum(w['size_bytes'] for w in old_float_tensors.values()) / (1024*1024):.2f} MB")
print(f"New model float tensors: {len(new_float_tensors)}, {sum(w['size_bytes'] for w in new_float_tensors.values()) / (1024*1024):.2f} MB")
# Examine the largest tensors
old_largest = sorted(old_weights.items(), key=lambda x: x[1]['size_bytes'], reverse=True)[:5]
new_largest = sorted(new_weights.items(), key=lambda x: x[1]['size_bytes'], reverse=True)[:5]
print("\n--- Largest Tensors ---")
print("Old model:")
for name, info in old_largest:
print(f" {name}: {info['shape']}, {info['dtype']}, {info['size_bytes'] / (1024*1024):.2f} MB, {info['sparsity']:.2%} sparse")
print("New model:")
for name, info in new_largest:
print(f" {name}: {info['shape']}, {info['dtype']}, {info['size_bytes'] / (1024*1024):.2f} MB, {info['sparsity']:.2%} sparse")
if __name__ == "__main__":
old_model_path = "old.tflite"
new_model_path = "new.tflite"
detailed_model_comparison(old_model_path, new_model_path)
=== Detailed Model Comparison ===
Old model size: 81.91 MB
New model size: 35.14 MB
Size reduction: 46.77 MB (57.1%)
--- Compression Analysis ---
Old model compression ratio: 1.10x
New model compression ratio: 1.11x
--- Binary Patterns ---
float32: 111816 → 166014 (+54198, 48.5%)
int8: 2708566 → 1083258 (-1625308, -60.0%)
runs_of_zeros: 53724 → 82344 (+28620, 53.3%)
--- Weight Statistics ---
Old model weights: 188 tensors, 85.85 MB total
New model weights: 189 tensors, 39.25 MB total
Old model average sparsity: 5.67%
New model average sparsity: 2.25%
--- Float Tensor Analysis ---
Old model float tensors: 94, 67.33 MB
New model float tensors: 94, 5.05 MB
--- Largest Tensors ---
Old model:
arith.constant30: [32128, 512], <class 'numpy.float32'>, 62.75 MB, 0.00% sparse
tfl.pseudo_qconst1: [512, 1024], <class 'numpy.int8'>, 0.50 MB, 1.27% sparse
tfl.pseudo_qconst2: [1024, 512], <class 'numpy.int8'>, 0.50 MB, 1.09% sparse
tfl.pseudo_qconst3: [1024, 512], <class 'numpy.int8'>, 0.50 MB, 1.08% sparse
tfl.pseudo_qconst8: [512, 1024], <class 'numpy.int8'>, 0.50 MB, 1.23% sparse
New model:
tfl.pseudo_qconst57: [32128, 512], <class 'numpy.int8'>, 15.69 MB, 1.08% sparse
tfl.pseudo_qconst1: [512, 1024], <class 'numpy.int8'>, 0.50 MB, 1.27% sparse
tfl.pseudo_qconst2: [1024, 512], <class 'numpy.int8'>, 0.50 MB, 1.09% sparse
tfl.pseudo_qconst3: [1024, 512], <class 'numpy.int8'>, 0.50 MB, 1.08% sparse
tfl.pseudo_qconst8: [512, 1024], <class 'numpy.int8'>, 0.50 MB, 1.23% sparse
TFLite Embedding Model Explorer – Streamlit web app for interactively comparing two TFLite text embedding models. It shows input/output shapes, computes sentence embeddings, visualizes similarities for search queries, compares inference times, and inspects tokenization and embeddings side-by-side.
import streamlit as st
import tensorflow as tf
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd
import os
import time
import sentencepiece as spm
# Set page title
st.set_page_config(page_title="Embedding Model Comparison", layout="wide")
# Function to load the SentencePiece tokenizer
@st.cache_resource
def load_tokenizer(tokenizer_path="sentencepiece.model"):
if not os.path.exists(tokenizer_path):
st.error(f"Tokenizer file not found: {tokenizer_path}")
return None
sp = spm.SentencePieceProcessor()
sp.load(tokenizer_path)
return sp
# Function to load a TFLite model
def load_model(model_path):
if not os.path.exists(model_path):
st.error(f"Model file not found: {model_path}")
return None
interpreter = tf.lite.Interpreter(model_path=model_path)
interpreter.allocate_tensors()
return interpreter
# Function to get embeddings from a TFLite model
def get_embedding(text, interpreter, tokenizer):
if interpreter is None or tokenizer is None:
return None, 0
# Get input and output details
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Get the expected input shape
input_shape = input_details[0]['shape']
max_seq_length = input_shape[1] if len(input_shape) > 1 else 64
# Properly tokenize the text using SentencePiece
tokens = tokenizer.encode(text, out_type=int)
# Handle padding/truncation
if len(tokens) > max_seq_length:
tokens = tokens[:max_seq_length] # Truncate
else:
tokens = tokens + [0] * (max_seq_length - len(tokens)) # Pad
# Prepare input tensor with proper shape
token_ids = np.array([tokens], dtype=np.int32)
# Set input tensor
interpreter.set_tensor(input_details[0]['index'], token_ids)
# Run inference
start_time = time.time()
interpreter.invoke()
inference_time = time.time() - start_time
# Get output tensor
embedding = interpreter.get_tensor(output_details[0]['index'])
return embedding, inference_time
# Function to load sentences from a file
def load_sentences(file_path):
if not os.path.exists(file_path):
return ["Hello world", "This is a test", "Embedding models are useful",
"TensorFlow Lite is great for mobile applications",
"Streamlit makes it easy to create web apps",
"Python is a popular programming language",
"Machine learning is an exciting field",
"Natural language processing helps computers understand human language",
"Semantic search finds meaning, not just keywords",
"Quantization reduces model size with minimal accuracy loss"]
with open(file_path, 'r') as f:
sentences = [line.strip() for line in f if line.strip()]
return sentences
# Function to find similar sentences
def find_similar_sentences(query_embedding, sentence_embeddings, sentences):
if query_embedding is None or len(sentence_embeddings) == 0:
return []
# Calculate similarity scores
similarities = cosine_similarity(query_embedding, sentence_embeddings)[0]
# Get indices sorted by similarity (descending)
sorted_indices = np.argsort(similarities)[::-1]
# Create result list
results = []
for idx in sorted_indices:
results.append({
"sentence": sentences[idx],
"similarity": similarities[idx]
})
return results
# Main application
def main():
st.title("Embedding Model Comparison")
# Sidebar for configuration
with st.sidebar:
st.header("Configuration")
old_model_path = st.text_input("Old Model Path", "old.tflite")
new_model_path = st.text_input("New Model Path", "new.tflite")
sentences_path = st.text_input("Sentences File Path", "sentences.txt")
tokenizer_path = st.text_input("Tokenizer Path", "sentencepiece.model")
# Load the tokenizer
tokenizer = load_tokenizer(tokenizer_path)
if tokenizer:
st.sidebar.success("Tokenizer loaded successfully")
st.sidebar.write(f"Vocabulary size: {tokenizer.get_piece_size()}")
else:
st.sidebar.error("Failed to load tokenizer")
return
# Load the models
st.header("Models")
col1, col2 = st.columns(2)
with col1:
st.subheader("Old Model")
old_model = load_model(old_model_path)
if old_model:
st.success("Old model loaded successfully")
old_input_details = old_model.get_input_details()
old_output_details = old_model.get_output_details()
st.write(f"Input shape: {old_input_details[0]['shape']}")
st.write(f"Output shape: {old_output_details[0]['shape']}")
with col2:
st.subheader("New Model")
new_model = load_model(new_model_path)
if new_model:
st.success("New model loaded successfully")
new_input_details = new_model.get_input_details()
new_output_details = new_model.get_output_details()
st.write(f"Input shape: {new_input_details[0]['shape']}")
st.write(f"Output shape: {new_output_details[0]['shape']}")
# Load sentences
sentences = load_sentences(sentences_path)
st.header("Sentences")
st.write(f"Loaded {len(sentences)} sentences")
if st.checkbox("Show loaded sentences"):
st.write(sentences[:10])
if len(sentences) > 10:
st.write("...")
# Pre-compute embeddings for all sentences (do this only once for efficiency)
if 'old_sentence_embeddings' not in st.session_state or st.button("Recompute Embeddings"):
st.session_state.old_sentence_embeddings = []
st.session_state.new_sentence_embeddings = []
if old_model and new_model:
progress_bar = st.progress(0)
st.write("Computing sentence embeddings...")
for i, sentence in enumerate(sentences):
if i % 10 == 0:
progress_bar.progress(i / len(sentences))
old_embedding, _ = get_embedding(sentence, old_model, tokenizer)
new_embedding, _ = get_embedding(sentence, new_model, tokenizer)
if old_embedding is not None:
st.session_state.old_sentence_embeddings.append(old_embedding[0])
if new_embedding is not None:
st.session_state.new_sentence_embeddings.append(new_embedding[0])
progress_bar.progress(1.0)
st.write("Embeddings computed!")
# Search interface
st.header("Search")
query = st.text_input("Enter a search query")
if query and old_model and new_model:
# Display tokenization for the query (for debugging)
with st.expander("View tokenization"):
tokens = tokenizer.encode(query, out_type=int)
pieces = tokenizer.encode(query, out_type=str)
st.write("Token IDs:", tokens)
st.write("Token pieces:", pieces)
# Get query embeddings
old_query_embedding, old_time = get_embedding(query, old_model, tokenizer)
new_query_embedding, new_time = get_embedding(query, new_model, tokenizer)
# Find similar sentences
old_results = find_similar_sentences(
old_query_embedding,
st.session_state.old_sentence_embeddings,
sentences
)
new_results = find_similar_sentences(
new_query_embedding,
st.session_state.new_sentence_embeddings,
sentences
)
# Add rank information
for i, result in enumerate(old_results):
result["rank"] = i + 1
for i, result in enumerate(new_results):
result["rank"] = i + 1
# Create separate dataframes
old_df = pd.DataFrame([
{"Sentence": r["sentence"], "Similarity": f"{r['similarity']:.4f}", "Rank": r["rank"]}
for r in old_results
])
new_df = pd.DataFrame([
{"Sentence": r["sentence"], "Similarity": f"{r['similarity']:.4f}", "Rank": r["rank"]}
for r in new_results
])
# Display results in two columns
st.subheader("Search Results")
col1, col2 = st.columns(2)
with col1:
st.markdown("### Old Model Results")
st.dataframe(old_df, use_container_width=True)
with col2:
st.markdown("### New Model Results")
st.dataframe(new_df, use_container_width=True)
# Show timing information
st.subheader("Inference Time")
st.write(f"Old model: {old_time * 1000:.2f} ms")
st.write(f"New model: {new_time * 1000:.2f} ms")
st.write(f"Speed improvement: {old_time / new_time:.2f}x")
# Show embedding visualizations
st.subheader("Embedding Visualizations")
col1, col2 = st.columns(2)
with col1:
st.write("Old Model Embedding (first 20 dimensions)")
st.bar_chart(pd.DataFrame({
'value': old_query_embedding[0][:20]
}))
with col2:
st.write("New Model Embedding (first 20 dimensions)")
st.bar_chart(pd.DataFrame({
'value': new_query_embedding[0][:20]
}))
if __name__ == "__main__":
main()
Leave a Reply