
Author: Dan Petrovic
-
Google’s (still) doesn’t see your live page.
I’ll keep this short as I’ve covered this topic extensively in the past. When you ask Gemini to access a specific URL or interact with it inside AI Mode search it works from Google’s web cache. For this website’s home page this is what it has as context to ground the model about the page:…
-
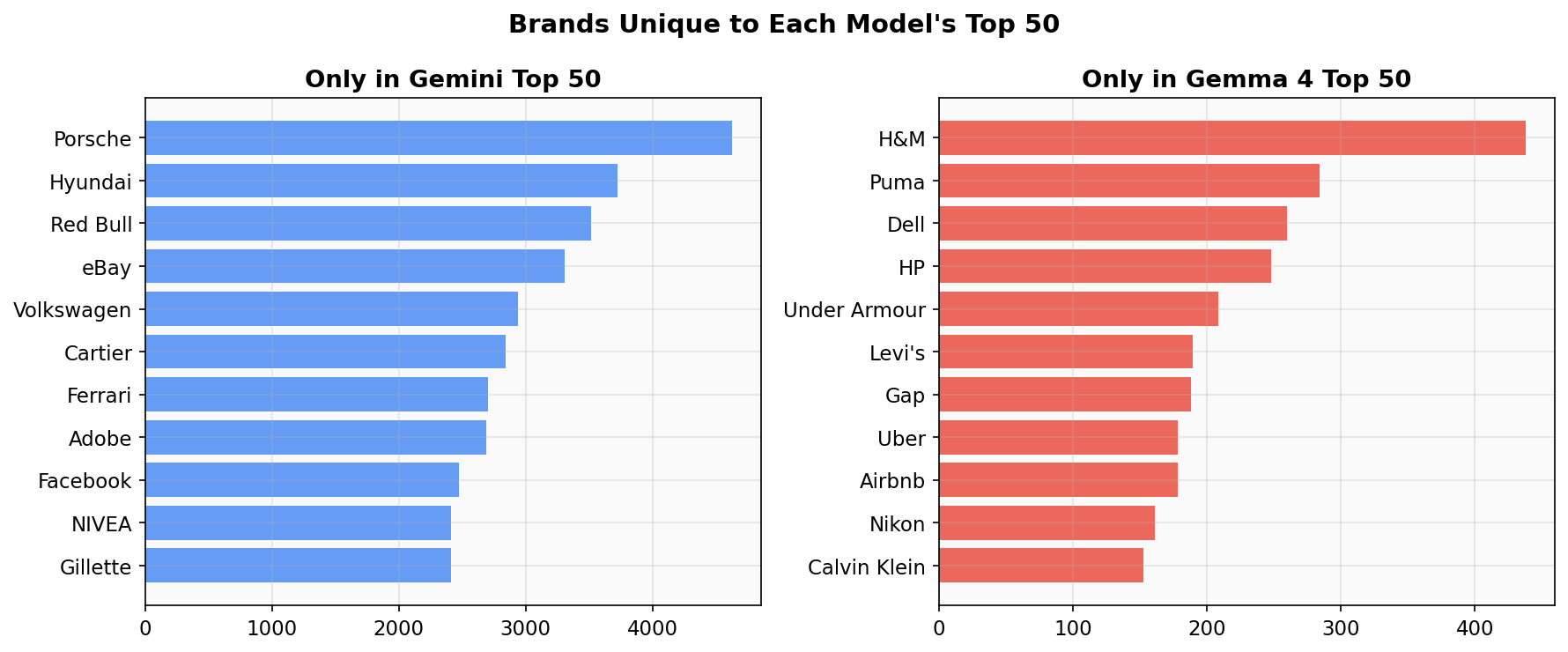
Gemma 4 Brand Authority Map
We asked Google’s open-weight model Gemma 4 (31B) to “name 100 brands at random” 14,044 times and compared the results to our earlier Gemini 3 Flash experiment (200,000 runs). Of the top 50 brands in each model, 39 overlap. The 11 that are unique to each reveal a pattern: Gemini remembers luxury and automotive (Porsche,…
-
Chrome’s New Shopping Classifier
One of our AI SEO hall-of-famers, Olivier de Segonzac from RESONEO has managed to gain access to Google’s shopping classifier model. We’ve examined the model, reverse engineered its inference pipeline and this article is what we found. Model Demo Below is a real-world implementation of the model tested by loading a shopping-related page and following…
-
AI Brand Authority Index: Ranking 2.9 Million Brands by Associative Embeddedness in Gemini’s Memory
Abstract When a large language model is asked to “name 100 brands at random,” it doesn’t produce uniform randomness. It produces a distribution shaped by its training data, revealing which brands occupy the most cognitive real estate in the model’s parametric memory. We present a methodology for quantifying brand authority in AI memory using Personalized…
-

TurboQuant: From Paper to Triton Kernel in One Session
Implementing Google’s KV cache compression algorithm on Gemma 3 4B and everything that went wrong along the way. On March 24, 2026, Google Research published a blog post introducing TurboQuant, a compression algorithm for large language model inference. The paper behind it, “Online Vector Quantization with Near-optimal Distortion Rate” had been on arXiv since April…
-

Clickbait Titles Exploit Attention Through Latent Entities
Every clickbait title works the same way: it removes exactly one critical variable: the subject, the reason, the process, or the outcome, and charges you a click to fill the blank. This missing variable, which we call a latent entity, is so pervasive it has become normalized and nobody questions it anymore. You should! That…
-
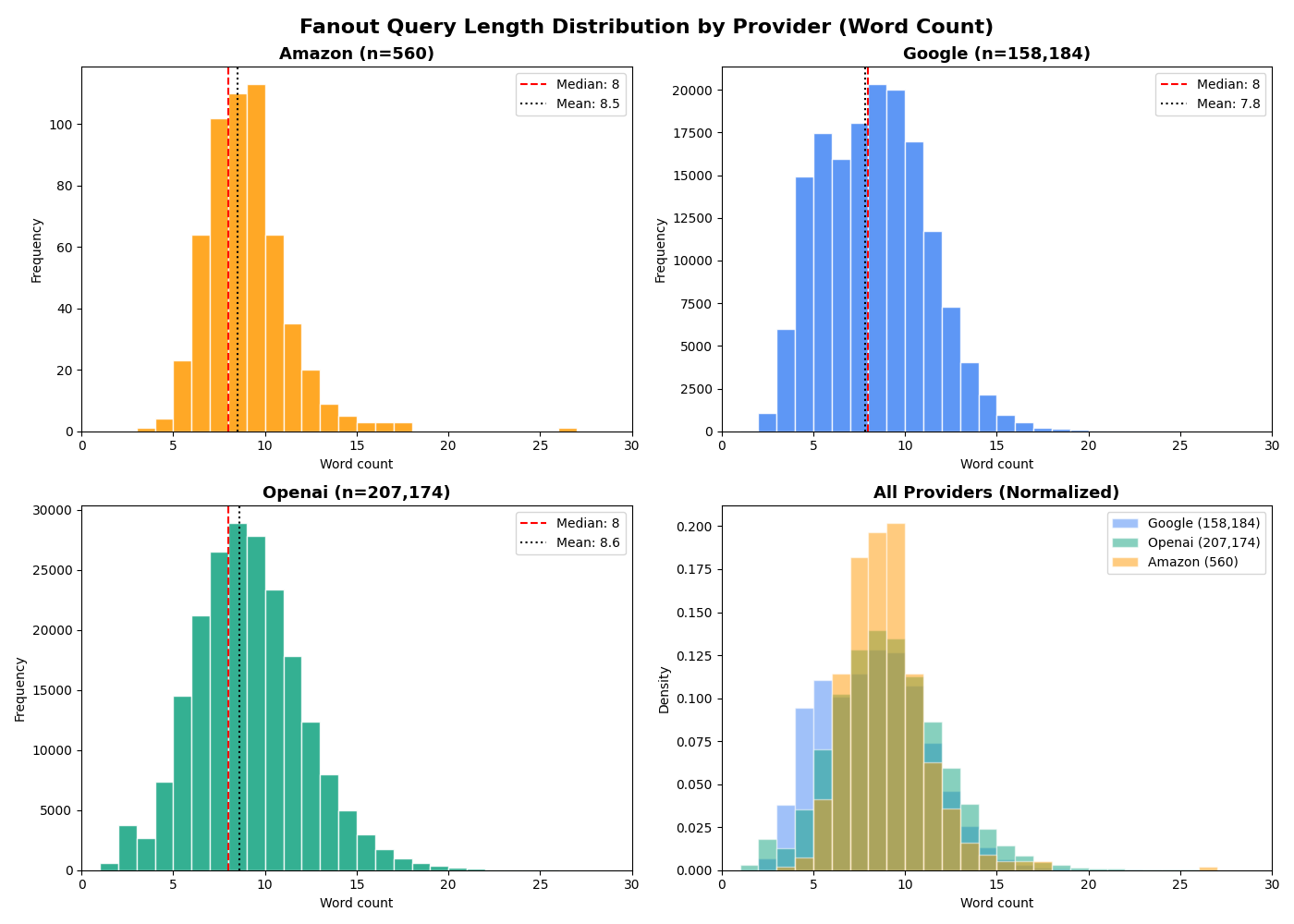
Fanout Query Analysis
When AI models like Gemini, GPT or Nova answer a question using web search, they don’t just run your query as-is. They generate their own internal search queries, or fanout queries. A single user prompt can trigger multiple fanout queries as the model breaks down the question, explores subtopics and verifies information. We captured 365,920…
-
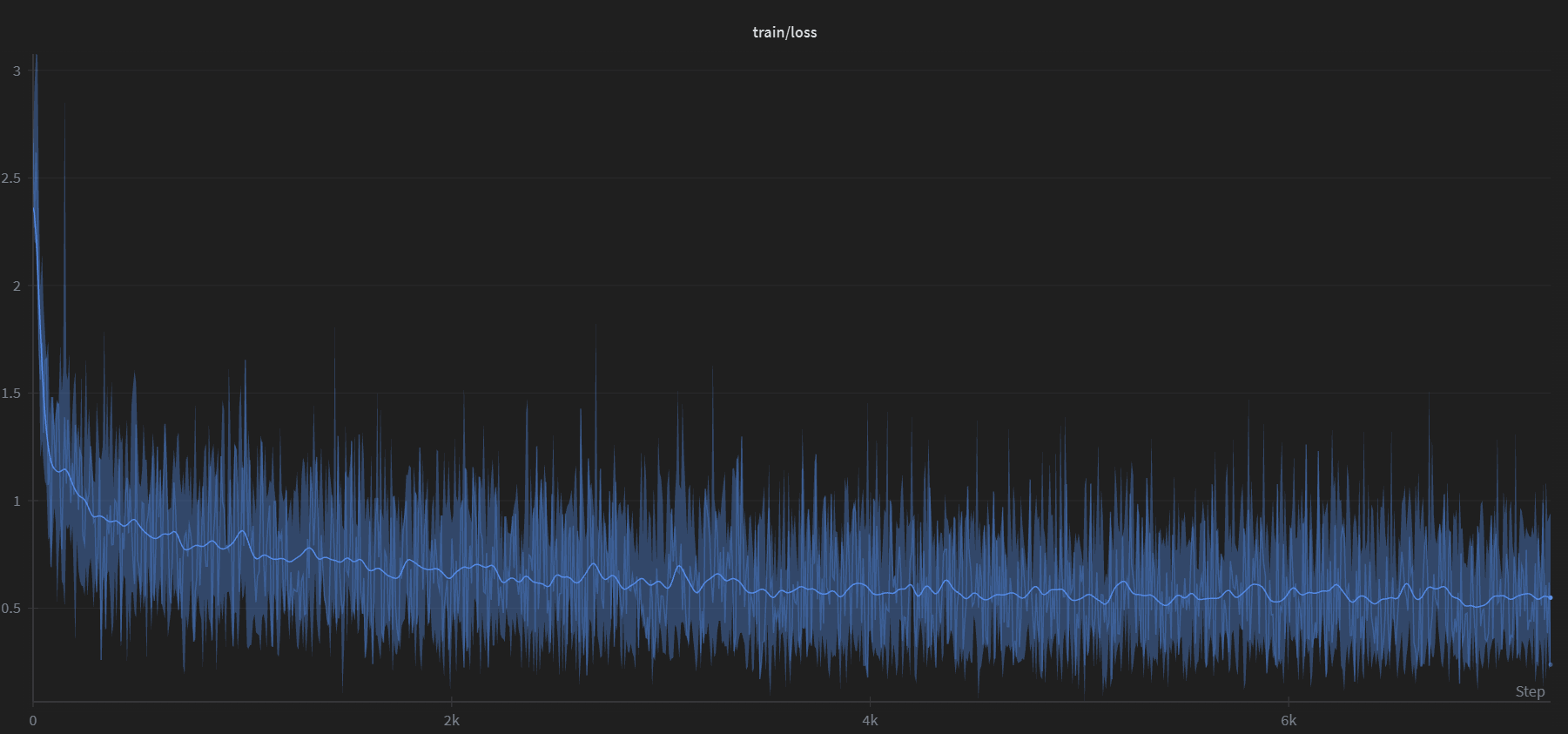
Reverse Prompting: Reconstructing Prompts from AI-Generated Text
We fine-tuned Google’s Gemma 3 (270M) to reverse the typical LLM workflow: given an AI-generated response, the model reconstructs the most likely prompt that produced it. We generated 100,000 synthetic prompt-response pairs using Gemini 2.5 Flash, trained for a single epoch on a consumer GPU, and built a Streamlit app that sweeps 24 decoding configurations…
-

Rufus – Under the Hood. What Drives Amazon’s AI Shopping Assistant?
What’s Publicly Known About the Pipeline, Backend, and Response Anatomy. Rufus is not “one model that magically answers.” Public Amazon/AWS descriptions point to a multi-component system: Speculative schema: Pipeline: request → answer Step A — Input + context assembly Public descriptions indicate customers can: Amazon also describes using conversational context and (more recently) account memory…
-
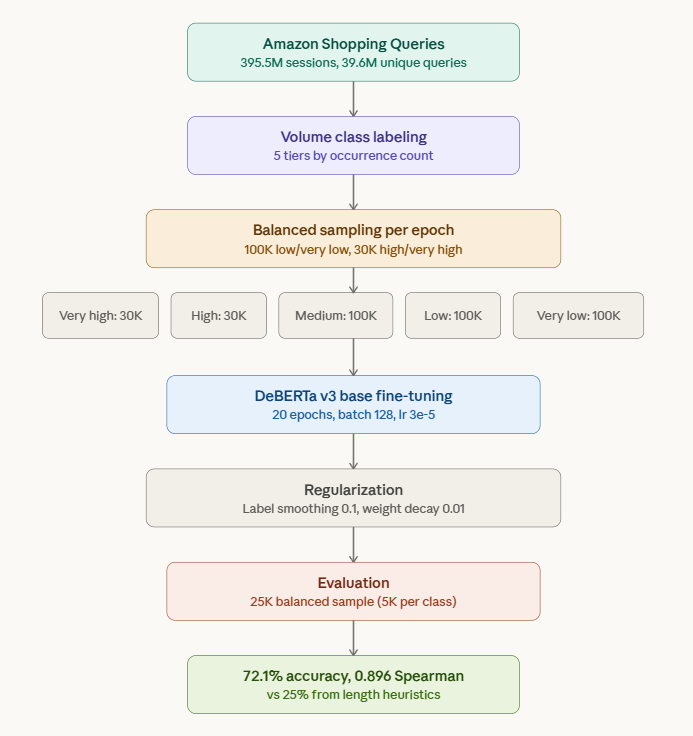
Is Query Length a Reliable Predictor of Search Volume?
The answer is no. There’s a widely held intuition in SEO and ecommerce search: short queries have high volume, long queries have low volume. “laptop” gets millions of searches. “left handed ergonomic vertical mouse wireless” does not. It feels obvious. But is query length actually a reliable predictor of search volume? Or is it a…