
Demo: https://dejan.ai/tools/substance/
Preface
In 1951, Isaac Asimov proposed an NLP method called Symbolic Logic Analysis (SLA) where text is reduced to its essential logical components.
This method involves breaking down sentences into symbolic forms, allowing for a precise examination of salience and semantics analogous to contemporary transformer-based NER (named entity recognition) and summarisation techniques.
In the Foundation novel, scientists at the Foundation use natural language processing to analyze the transcript of an Imperial envoy’s five-day speech. They discovered that despite the elaborate and seemingly profound language, the speech contained no substantial guarantees or meaningful promises.
This analysis revealed that the envoy effectively said nothing.
Click to expand for the relevant parts of the book. I guarantee you it’s worth it!
Hardin said, “There wasn’t any information in Dorwin’s statement at all. Listen, Lee, I’ve got the transcript of his entire five days of talk. It has been analyzed and reanalyzed by our symbolic logic experts.
He said nothing—and I mean absolutely nothing!” He lifted his arms on high and declaimed in mock tragedy, “He said that to expect the Empire to take any action in our favor would be silly.
He said that no promises could be made for the future. He said that no method could be given to us for forcing the Empire to our aid. He said that, actually, there was no way for us to obtain Imperial help. In short, he talked much and said nothing.”
Hardin looked up, and his eyes were blue ice. “Do you know what I’m going to do? I’m going to let you have the transcript of that speech, and you can read it at your leisure. You’ll find it perfectly simple once you analyze it.
Why, the very first principles of psychohistory would tell you—if you knew anything about psychohistory—that Dorwin made no guarantees at all. No guarantees, understand. None.
Do you know what the symbolic logic analysts did with it? They split it up into sentences and, like splitting a bamboo, found nothing in it.”
“He said nothing at all,” growled Yohan Lee, disgustedly, “and took five days to say it!”
Cyberfluff: Curriculum-Driven Contrastive Pretraining for Quality Content Detection
Abstract
We present a novel approach to detecting low-quality web content, termed cyberfluff, by leveraging a curriculum-based contrastive pretraining strategy followed by single-sample classification fine-tuning. Our method first teaches a transformer-based model to distinguish between stylistically paired texts (fluff vs. substance) across 10 escalating levels of contrast difficulty. We then transition the model into a binary classifier, fine-tuning it on isolated samples, shuffled and rebalanced, across the same difficulty progression. The final model achieves robust generalization, correctly classifying substance-rich content across diverse domains while avoiding overfitting to surface-level features.
1. Introduction
The modern web is saturated with content of widely varying informational quality. Despite advances in text classification and LLMs, reliable automated systems for flagging low-substance, high-fluff content remain underdeveloped. We address this by reframing the problem as one of contrastive learning, inspired by how humans learn to distinguish signal from noise through exposure to increasing complexity and nuance.
Rather than relying solely on flat binary classification, we train models in two distinct phases:
- Pairwise contrastive pretraining, where the model is exposed to structured article pairs annotated as
fluffvs.substance. - Single-sample fine-tuning, where the model is converted into a standard classifier and retrained over progressively harder datasets.
This curriculum-driven progression enables the model to form robust internal representations of quality-relevant features before facing real-world, noisy inference scenarios.
2. Dataset and Difficulty Modeling
We constructed a proprietary dataset of article pairs across domains (e.g., technology, health, policy) in which each pair contains:
- A “fluff” sample: stylistically verbose, emotionally padded, or general.
- A “substance” sample: factually dense, citation-supported, or structurally analytical.
Each pair is labeled with a contrast difficulty level (L1 to L10), determined by how easily the distinction can be made by humans. Levels are based on pair_number and content heuristics.
3. Training Pipeline
3.1 Phase 1: Contrastive Pretraining
We train a binary classifier where each input is a pair:
[Fluff Text] [SEP] [Substance Text]
The model must predict whether the fluff comes first (0) or second (1). This is trained in curriculum order: L1 → L10, one epoch per level, saving checkpoints progressively.
3.2 Phase 2: Single-Sample Fine-Tuning
Starting from the final contrastive checkpoint (L10), we switch to a traditional text classification format:
text → label ∈ {0: fluff, 1: substance}
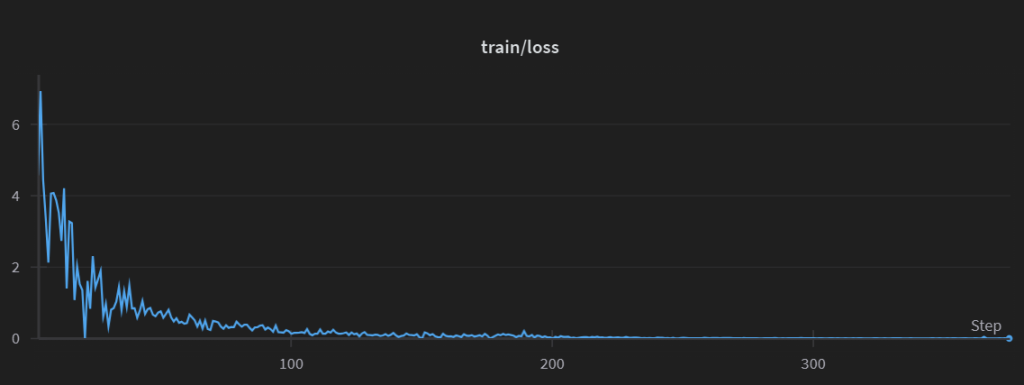
We again train level-by-level (L1 to L10), using shuffled samples to avoid order-based bias. This allows the model to generalize from pairwise contrast into single-instance inference.
4. Evaluation
4.1 Contrast Sweep Test
We apply all 10 classifier checkpoints to a curated set of 10 text samples spanning L1–L10 and observe which checkpoints consistently predict substance. L6 and L7 offer optimal balance between recall and overfitting resistance.
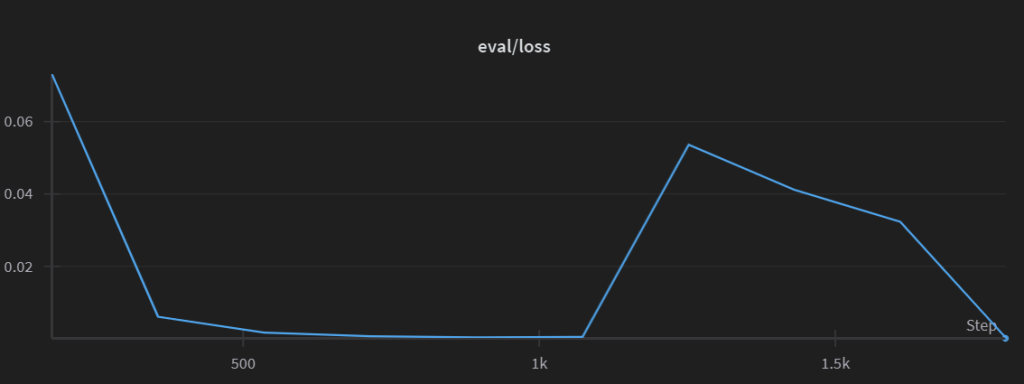
4.2 Real-World Deployment
The final model (L6) is deployed as a Hugging Face-hosted endpoint and used in a live Streamlit app that crawls domains, parses sitemaps, scrapes pages, and classifies content into:
CyberfluffQuality content
4.3 Performance
On a set of 20 manually verified test samples:
- Accuracy: 100% on extreme cases (L1–L3, L8–L10)
- 1 borderline case at L5 misclassified due to ambiguous tone/content alignment
5. System Design
We built a full pipeline to support:
- Sitemap crawling and URL extraction
- Robust page scraping and text extraction (via
trafilatura) - Real-time classification via Hugging Face Transformers
- SQLite storage and resumable analysis
- Streamlit dashboard with bar charts and quality scoring
6. Related Work
- Curriculum Learning (Bengio et al., 2009): foundational inspiration
- Contrastive Learning for NLP (Gao et al., 2021): we extend from contrast to classification
- Style Transfer and Deception Detection: tangential goals, differing execution
7. Conclusion and Future Work
This work demonstrates that contrastive, curriculum-guided pretraining can serve as a strong foundation for subjective content classification. Our system captures the subtle, stylistic shifts that separate fluff from substance and generalizes well in single-input settings.
Future work:
- Multi-label expansion (e.g., misinformation, clickbait, advertorial)
- Triplet-based augmentation without semantic leakage
- Extension to multilingual web content
References
Bengio, Y., Louradour, J., Collobert, R., & Weston, J. (2009).
Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning (pp. 41–48). https://doi.org/10.1145/1553374.1553380
Gao, T., Yao, X., & Chen, D. (2021).
SimCSE: Simple contrastive learning of sentence embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 6894–6910). https://doi.org/10.18653/v1/2021.emnlp-main.552
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2020).
Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140), 1–67. https://jmlr.org/papers/v21/20-074.html
Kiros, R., Zhu, Y., Salakhutdinov, R., Zemel, R., Urtasun, R., Torralba, A., & Fidler, S. (2015).
Skip-thought vectors. In Advances in Neural Information Processing Systems (NeurIPS), 28, 3294–3302. https://proceedings.neurips.cc/paper/2015/hash/4e4e53aa965960a3eaf9f6e10cd4d50e-Abstract.html
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019).
BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT 2019 (pp. 4171–4186). https://doi.org/10.18653/v1/N19-1423
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018).
Improving language understanding by generative pre-training. OpenAI Blog. https://openai.com/research/language-unsupervised
Zhang, W., Wei, F., Zhou, M., & Liu, T. (2014).
Detecting clickbait for news articles using linguistic patterns. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 551–561). https://aclanthology.org/D14-1060/
Zellers, R., Holtzman, A., Rashkin, H., Bisk, Y., Farhadi, A., Roesner, F., & Choi, Y. (2019).
Defending against neural fake news. In Advances in Neural Information Processing Systems (NeurIPS), 32. https://papers.nips.cc/paper_files/paper/2019/hash/ccfa5d4cfc6a5e7cce1e3b64b1b985e8-Abstract.html
Training Data Examples:
class,text
0,”Making coffee is a wonderful way to start your day. It’s really quite simple! First, you need some coffee. Get some good beans, maybe from a nice store. Then you need water. Hot water is key! You can use a coffee maker, which does most of the work for you. Just put the coffee grounds in the filter, add water, and push the button. Soon, you’ll smell that amazing coffee aroma filling your kitchen. It’s such a comforting smell. Or, if you like, you can try other methods. Some people use special pots or presses. Whatever way you choose, the goal is the same: a delicious cup of coffee to enjoy. Remember to add milk or sugar if you like it that way. It’s all about personal preference. Making coffee isn’t just about the drink, it’s about the ritual, the warmth, the moment of pause before the day rushes in. It’s a small pleasure that makes a big difference. So go ahead, brew yourself a cup and savor the moment. There’s nothing quite like it. Enjoy your perfect cup!”
1,”Brewing exceptional coffee hinges on controlling key variables: grind size, water temperature, coffee-to-water ratio, and extraction time. For pour-over methods like the V60 or Chemex, start with a medium-fine grind. Water temperature should ideally be between 195-205°F (90-96°C); boiling water can scorch the grounds, leading to bitterness. A standard ratio is 1:15 to 1:17 (e.g., 20 grams of coffee to 300-340 grams of water). Begin by ‘blooming’ the grounds: pour just enough hot water (around twice the weight of the coffee) to saturate them evenly, then wait 30 seconds. This releases CO2 gas, allowing for better extraction. Proceed with pouring the remaining water in slow, controlled circles, avoiding the filter’s edges. Aim for a total brew time of 2.5 to 4 minutes, depending on the brewer and volume. For French press, use a coarse grind and a similar ratio, steeping for about 4 minutes before plunging slowly. Espresso requires a very fine grind and specialized equipment to force hot water through compacted grounds under pressure. Regardless of method, using freshly roasted, quality beans ground just before brewing significantly enhances flavor and aroma. Experimenting with these parameters allows you to tailor the brew to your specific taste preferences.”
0,”Staying hydrated is super important, everyone knows that! Drinking water is just one of those things you should do every day, like eating or sleeping. It makes you feel good, you know? When you drink enough water, your body just works better. Think about it – your body is mostly water! So, obviously, putting more water into it is beneficial. It can help with energy levels, making you feel less tired during the day. Some people even say it helps their skin look amazing! It’s like a natural beauty treatment. Plus, on hot days, or after exercise, water is the best thing to cool you down and replace what you lost through sweat. It’s just common sense, really. There are so many amazing benefits to just drinking plain old water. It helps everything run smoothly, from your brain to your muscles. So make sure you grab that water bottle and keep sipping throughout the day – your body will definitely thank you for it. It’s simple, easy, and makes a huge difference to your overall well-being. Water is truly life!”
1,”Adequate water intake is crucial for maintaining physiological homeostasis. Water constitutes approximately 60% of adult body weight and plays vital roles in numerous bodily functions. Cellular function, nutrient transport, waste elimination, and thermoregulation all depend on sufficient hydration. For instance, water acts as a solvent for metabolic reactions and facilitates the transport of oxygen and nutrients via the bloodstream. During physical activity or exposure to heat, perspiration helps regulate body temperature, but this necessitates fluid replacement to prevent dehydration. Dehydration can impair cognitive function, reduce physical performance, and, in severe cases, lead to serious health complications like heatstroke or kidney problems. Recommended daily intake varies based on factors like age, sex, climate, and activity level, but general guidelines often suggest around 2-3 liters (8-12 cups) daily from all sources, including beverages and water-rich foods. While individual needs differ, consistently monitoring urine color (aiming for pale yellow) and thirst signals can help gauge hydration status. Ensuring adequate water consumption is a fundamental component of preventative health, supporting systemic functions from renal processing to maintaining mucosal membrane integrity and joint lubrication. It underpins overall health and optimal physiological performance across multiple domains.”
Leave a Reply