
In our previous post, Training a Query Fan-Out Model, we demonstrated how to generate millions of high-quality query reformulations without human labelling, by navigating the embedding space between a seed query and its target document and then decoding each intermediate vector back into text using a trained query decoder.
That decoder’s success critically depends on having an embedding encoder whose latent geometry is fully under our control: off-the-shelf models (e.g. mxbai embed large) optimize for general semantic similarity, not for invertibility, so their embeddings cannot reliably be mapped back into meaningful queries.
To bridge that gap, this article introduces Gemma-Embed, a bespoke 256-dim embedding model built by fine-tuning google/gemma-3-1b-pt with LoRA adapters and contrastive objectives. By training our own encoder, we lock in a consistent, L2-normalized latent space that the subsequent query decoder can invert with high fidelity.
Quick Recap of the Query Fan-Out Mission
- Query Decoder: Train a T5-based model to invert a fixed retrieval encoder (e.g. GTR) so that any embedding vector produces the original query. Achieved ~96% cosine similarity on reconstruction.
- Latent Space Traversal: For each (query, document) pair, interpolate in the embedding space, decode each point, and retain reformulations that improve retrieval metrics—yielding hundreds of thousands of synthetic examples.
- Production Model (qsT5): Fine-tune T5 on that synthetic dataset (with and without pseudo-relevance feedback) to internalize traversal patterns—so at inference time it generates diverse, effective reformulations without any explicit vector arithmetic.
Together, these steps automate query fan-out, boost retrieval performance, and open the door to interpretable, language-agnostic search suggestions.
To power a query fan‑out decoder that inverts embeddings back to natural language queries, we need an embedding encoder whose latent geometry we control. Since no off‑the‑shelf Gemma‑3 embedding model exists, we fine‑tune google/gemma‑3‑1b‑pt with LoRA and contrastive objectives to produce high‑quality, L2‑normalized 256‑dim embeddings.
Model Architecture
- Base Encoder:
google/gemma-3-1b-pt(1 B params) - LoRA Adapters:
- Target modules:
q_proj,v_proj - Rank (r): 8
- Alpha (α): 16
- Dropout: 0.05
- Projection Head:
- Input: hidden_size (1024)
- MLP: Linear(1024→512) → ReLU → Linear(512→256)
- L2 normalization
Data and Format
Phase 1 – Unsupervised SimCSE
- Source:
text.txt(wiki sentences or plain text logs) - Size: 579,719 sentences
- Format: UTF‑8 plain text, one sequence per line
- Sample lines:
Breaking news: stock markets rally as central bank hints at rate cut.
How do I fine‑tune a large language model for embeddings?
The Northern Lights are visible tonight in high‑latitude regions.Phase 2 – Supervised Paraphrase Contrastive
- Source:
triplets.csv - Columns:
a_ids,a_mask,p_ids,p_mask,n_ids,n_mask(token IDs & masks) - Size: user‑provided paraphrase pairs (e.g., ParaNMT ~3.6 M, QuoraQP ~400 k, PAWS ~60 k)
- Format: CSV with header. Each row:
a_ids,a_mask,p_ids,p_mask,n_ids,n_mask
102 345 ... ,1 1 ... ,203 456 ... ,1 1 ... ,307 523 ... ,1 1 ...- Original text pairs stored in scripts folder for reference.
Phase 3 – In‑Domain Self‑Contrast
- Source:
queries.db
CREATE TABLE queries (
query_id INTEGER PRIMARY KEY AUTOINCREMENT,
query TEXT UNIQUE NOT NULL
);- Size: 7,129,444 unique queries
- Pretokenized:
pretokenized_queries.pt - Tensors:
input_ids(7,129,444 × 128),attention_mask(7,129,444 × 128) - File size: ~13.5 GB
- Sample queries:
SELECT query FROM queries LIMIT 5; How to bake sourdough at home?
Weather tomorrow in Sydney
Best restaurants near me open now
convert 1 mile to kilometers
streamlit file uploader exampleTraining Pipeline
| Phase | Objective | Loss | Batch | Epochs | LR | Data Size |
|---|---|---|---|---|---|---|
| 1 | Unsupervised SimCSE | InfoNCE (τ=0.05) | 12 | 1 | 1e‑5 | 579,719 sentences |
| 2 | Supervised Triplet Contrastive | TripletMarginLoss(0.2) | 12 | 3 | 1e‑5 | ~4 M triplets |
| 3 | In‑Domain Self‑Contrast | InfoNCE (τ=0.05) | 64 | 1 | 1e‑5 | 7,129,444 queries |
File Layout
train-gemma/
├── text.txt
├── triplets.csv
├── queries.db
├── pretokenized_queries.pt
├── scripts/
│ ├── train_stage_1.py
│ ├── train_stage_2.py
│ ├── pretokenize_queries.py
│ └── train_stage_3.py
├── stage1_simcse/final/
├── phase2_triplet_amp/final/
└── phase3_self_contrast/final/Sample Data Sizes
- text.txt: 579,719 lines (~50 MB)
- triplets.csv: depends on sources (~500 MB for 4 M rows)
- queries.db: ~200 MB SQLite file
- pretokenized_queries.pt: 13.5 GB
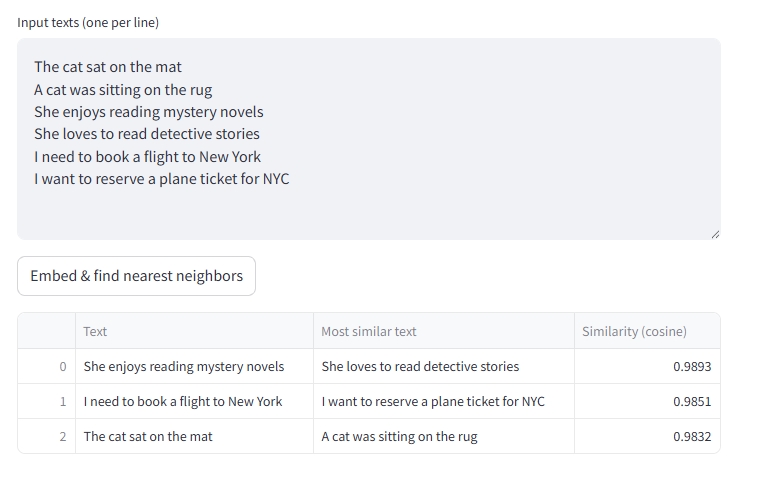
Inference Test
Leave a Reply