
OpenAI’s latest model is trained to be intelligent, not knowledgeable.
Wait, what?
Yup. You read that right.
- GPT-5 simply doesn’t know as many things which other, often much smaller models, do.
- This is a model trained to be logical, intelligent and handle its tools well.
- Its weights do not contain all of world’s information.
- It’s weights are trained to handle the information passed to it.
- This is clearly a deliberate design choice and a brilliant move by OpenAI.
Here’s an example:
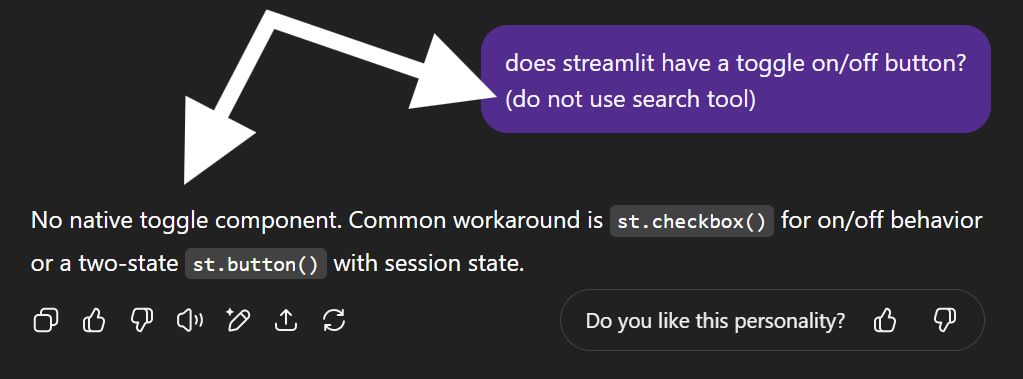
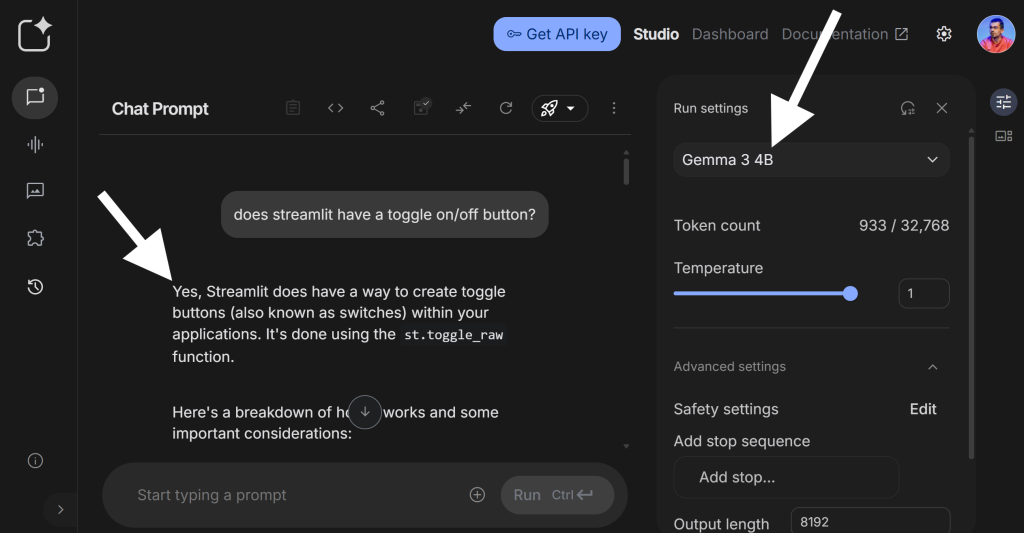
Now, you may think this is some pretty esoteric knowledge not broadly relevant to most end users and you’re right. But here’s a tiny, open source model from Google, Gemma 3 4B, just knowing this fact, no dramas, no grounding:
Now look what happens when grounding is on for GPT-5:
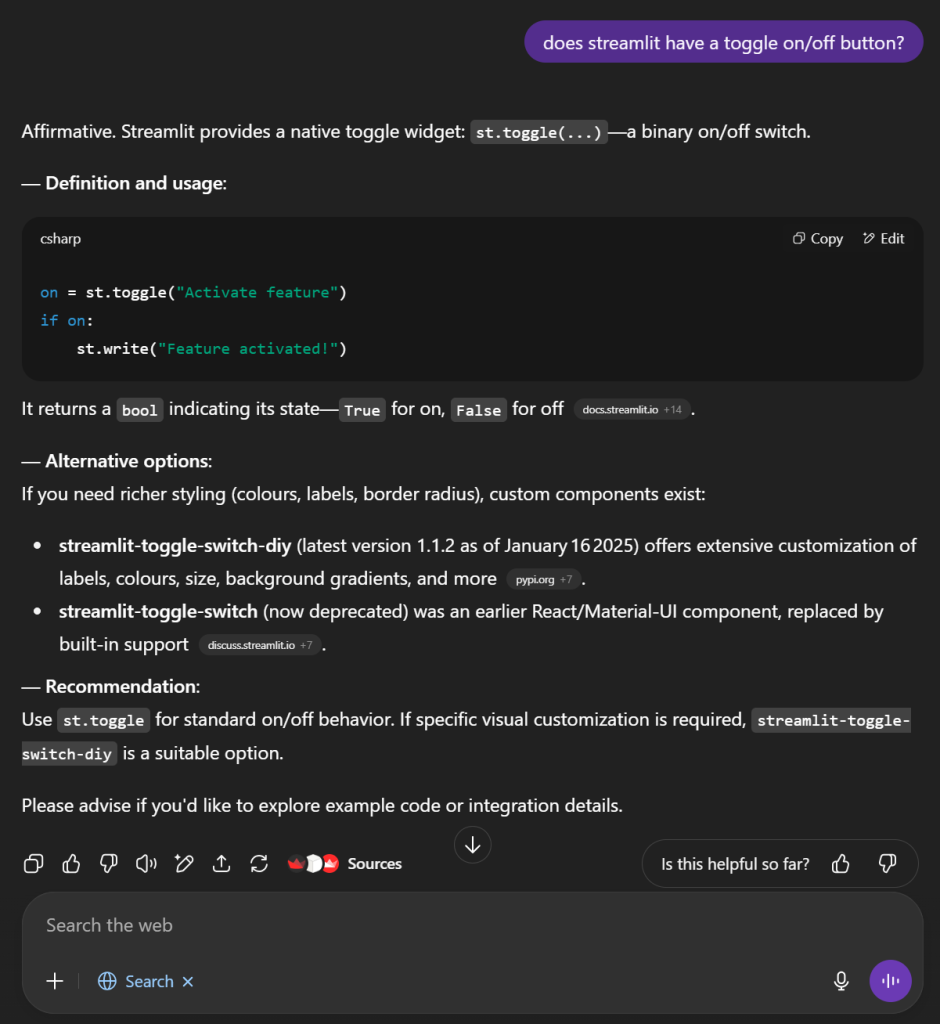
Now the difference between the two models is vast, Gemma is so small it can run on your computer or even a phone, while GPT-5 is a behemoth in comparison.
What’s this to do with SEO?
In case the coffee didn’t kick in yet. Let me spell it out for you, OpenAI, the leader in AI assistant space, made an executive decision to focus on raw intelligence and leave the rest to search engines.
I think we have to plan for this, and this is why search is really important. I still believe that, no question, the right product is LLMs connected to ground truth, and that’s why we brought search to ChatGPT and I think that makes a huge difference.
Nick Turley
Head of ChatGPT at OpenAI
for The Verge
Without grounding this model is virtually useless. It’s designed to be the brain on top of tools and information it’s provided with.
This means SEO has never been more relevant than now.
What does the future hold?
Perhaps everything can be summarized in these few words by Yannic Kilcher:
Just how much world knowledge is required versus how much tool calling availability is required and how should we balance between the two?
Why am I quoting Yannic ahead of Sam Altman?
Because he saw things coming the way few did back in August 2019 when he flagged the (now famous) double descent paper which preceded the scaling revolution of large language models, enabling us to go from BERT to Gemini 3 and GPT-5.
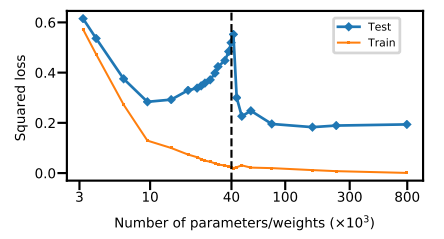
Yannic’s foresight and intuition is indisputable, but for anyone who still doubts his vision, here’s what Sam himself says about the matter:
“…we have transitioned into the next paradigm of models that can do complex reasoning.”
Google agrees.
OpenAI’s Focus on Reasoning Over Memorized Knowledge
OpenAI’s leadership has increasingly signaled a strategic shift toward “intelligence and reasoning” in model weights, while relying on external sources or retrieval for up-to-date knowledge. In other words, OpenAI appears to be designing models that think and reason well, but don’t attempt to internally store all world knowledge – instead leveraging retrieval-augmented methods (tools, search, plugins, large contexts) to pull in fresh information as needed. This approach is motivated by efficiency, cost, and performance considerations, as evidenced by recent statements, research, and product releases.
Leadership Vision: Reasoning + Tools, Not All Knowledge in Weights
OpenAI’s CEO Sam Altman has explicitly described his “platonic ideal” AI as a very small model with extraordinary reasoning ability, enormous context, and access to tools – rather than a massive model packed with all knowledge. In June 2025, Altman said the perfect AI would be “a very tiny model with superhuman reasoning… 1 trillion tokens of context and access to every tool you can possibly imagine.” Crucially, “It doesn’t need to contain the knowledge – just the ability to think, search, simulate, and solve anything.”[1][2]. This vision directly emphasizes externalizing knowledge (via tools and huge context windows) and internalizing cognitive skill (reasoning in the weights).
Altman has also noted that simply scaling up “knowledge-loaded” pre-trained models is hitting diminishing returns. He referred to large pre-trained LLMs as the “old world,” suggesting that training ever-bigger models on more data is yielding weaker improvements[3]. Instead, OpenAI is exploring “specialized models optimized through reinforcement learning” for high-accuracy reasoning tasks (what he calls “large reasoning models” or LRMs)[4]. These reasoning-optimized models have demonstrated “an incredible new compute efficiency gain”, achieving performance on some benchmarks that “in the old world we would have predicted wouldn’t have come until GPT-6” – but with models that are much smaller[5]. In short, Altman’s comments strongly hint at an executive-level decision to prioritize reasoning efficiency over brute-force knowledge memorization in model design.
OpenAI’s vision aligns with the idea that a model should figure things out rather than store everything. As Altman put it in an interview, “the perfect AI will solve any problem with reasoning, even if it doesn’t have access to specific data.”[1] This philosophy – intelligence over encyclopedia-like memory – underpins many of OpenAI’s recent moves.
Training larger and larger language models (LLMs) with more and more data hits a wall. According to OpenAI CEO Sam Altman, combining “much bigger” pre-trained models with reasoning capabilities could be the key to overcoming the scaling limitations of pre-training.
Retrieval and Tool Use for Fresh Knowledge
To compensate for not “stuffing” all knowledge into the neural weights, OpenAI has leaned on Retrieval-Augmented Generation (RAG) techniques and tool use to provide grounded, up-to-date information. For example, in March 2023 OpenAI introduced ChatGPT Plugins with the explicit goal of giving the model access to fresh data and computations. OpenAI’s plugin announcement noted that “language models today… are limited. The only information they can learn from is their training data. This information can be out-of-date… Furthermore, the only thing language models can do out-of-the-box is emit text.” Plugins were created as a solution: “tools designed… to help ChatGPT access up-to-date information, run computations, or use third-party services.”[6][7]. In other words, rather than trying to have ChatGPT know everything internally, OpenAI gave it “eyes and ears” in the form of a web browser, code executor, and retrieval plugin for external knowledge bases[8]. This marked a clear product decision to rely on grounding via external data when current or niche information is needed, rather than forcing all such knowledge into the model’s parameters.
OpenAI’s newer models continue this trend of tool integration and retrieval. Notably, in August 2025 OpenAI released GPT-OSS (Open-Source Series) models that are explicitly built for “powerful reasoning [and] agentic tasks” with the ability to use tools[9]. These models (gpt-oss-20b and 120b) are “reasoning, text-only models; with chain-of-thought and adjustable reasoning effort levels” and even have “instruction following and tool use support.”[9] In practice, GPT-OSS can act as an agent: OpenAI equipped it with the capability to call external tools (like web search or Python code) as part of its reasoning process[10]. An OpenAI whitepaper example showed gpt-oss-120b browsing the internet in multiple steps to gather information for answering a question[11]. OpenAI themselves highlight that this model “is able to quickly aggregate up-to-date information using a browsing tool, including chaining together 10s of subsequent calls.”[11] This is a concrete illustration of OpenAI’s design choice: the model’s weights handle the reasoning and decision-making (figuring out what to search, how to use the results), while the knowledge is fetched on the fly from external sources.
By relying on retrieval and tools (what the user describes as “RAG/grounding for fresh knowledge”), OpenAI can keep models’ knowledge fresh and factual without constant re-training. It also provides transparency and updatability – instead of a black-box memory, the model can cite sources or use real data, which is important for accuracy and trust. This strategy helps combat hallucinations stemming from outdated or incomplete internal knowledge. (OpenAI has noted that smaller models with less built-in world knowledge do hallucinate more[12], but tool-use and retrieval are intended to mitigate that by supplying real info when needed.)
The executive indicated that it doesn’t matter whether the model will have access to data or knowledge, it’ll still be able to solve a problem since it can reason, search, simulate, and solve anything.
Efficiency, Speed, and Cost Motivations
Focusing on reasoning-over-memory is also driven by efficiency and cost concerns. Gigantic monolithic models that try to “know” everything are extremely costly to train and run, and they become environmentally and economically unsustainable beyond a point. OpenAI’s pivot to smarter, not just bigger models is evident in how they’ve engineered recent systems:
- Mixture-of-Experts & Smaller Models: The GPT-OSS models use a mixture-of-experts (MoE) architecture, which allows them to have a large total parameter count but activate only a small subset of those weights for any given query[13][9]. For instance, the 117B-parameter GPT-OSS uses only ~5.1B active parameters per token with MoE[14]. This design yields significant efficiency gains – the model can achieve strong results without the energy overhead of using all 117B parameters at once. OpenAI’s open models are remarkably efficient: they can run on a single GPU (the 120B model fits on one NVIDIA H100) or even a 16GB consumer laptop (the 20B model)[15]. A HuggingFace analysis found GPT-OSS to be “the most energy-efficient” among models in its class – using far less electricity per query than similarly-sized models (even less than some models half its size)[16][17]. This efficiency is attributed to technical choices like MoE (fewer active weights = lower computation) and optimized attention mechanisms[17]. In short, by not having to brute-force through a giant dense network of memorized facts, the model saves power, speed, and cost.
- Multi-Stage Reasoning Engines: With the forthcoming GPT-5, OpenAI has reportedly adopted a “multi-model” or tiered approach to balance speed and reasoning power[18]. Simpler queries get answered by a lightweight fast model, whereas complex tasks trigger a “deep reasoning” expert model[19]. This dynamic routing means the system expends heavy computation only when needed for difficult problems, rather than running a huge model for every request. It’s another acknowledgment that efficiency matters – an intelligent system should use minimal resources for easy tasks and save the big guns for the hard tasks, which again reflects a focus on optimized reasoning instead of one-size-fits-all memorization.
- Expanded Context Windows: Rather than storing more facts in weights, OpenAI is expanding models’ ability to read more external text. GPT-4 already introduced a 32,000-token context window, and GPT-5 reportedly extends context up to 400,000 tokens (roughly 300,000 words)[20]. Such a vast context means the model can be given an entire book, codebase, or a large knowledge base at query time. This is effectively an implementation of RAG: the model can accept huge “documents” or search results as input, grounding its responses on those without needing the information pre-encoded in its weights. A massive context combined with high reasoning capacity is in line with Altman’s ideal of “1 trillion tokens of context” – it shifts the paradigm from “knowledge stored inside model” to “knowledge provided to model when needed.”
Research and Industry Trends
OpenAI’s approach is mirrored by broader research trends emphasizing the separation of knowledge and reasoning. For example, a 2025 paper on Retrieval-Augmented Reasoning (RARE) explicitly proposes “a novel paradigm that decouples knowledge storage from reasoning optimization.” In RARE, “domain knowledge is externalized to retrievable sources and domain-specific reasoning patterns are internalized during training.” This allows models to “bypass parameter-intensive memorization and prioritize the development of higher-order cognitive processes.”[21]. The authors demonstrate that relatively small models, when paired with retrieval, can outperform much larger ones that rely on parametric memory[22]. This reflects the same core idea behind OpenAI’s strategy: use external knowledge bases and focus the model on reasoning. In practice, Retrieval-Augmented Generation (whether via OpenAI’s plugins, or systems like LangChain tool use) has become a standard method to keep AI responses accurate and current. OpenAI’s own plugin ecosystem and tool-use features are a direct implementation of this philosophy in real products.
Even OpenAI’s internal evaluations note the trade-off between model size (world knowledge) and hallucination, reinforcing why hooking to reliable external info is valuable. As one OpenAI report put it, “smaller models have less world knowledge than larger frontier models and tend to hallucinate more”, so augmenting them with tools or context can supply the missing knowledge[12]. By choosing to deploy smaller, tool-using models, OpenAI is effectively saying it’s more efficient to fetch knowledge on demand than to massively scale up a model just to encode that knowledge permanently.
From Sam Altman’s statements and OpenAI’s product designs, to technical releases and third-party analyses it all points to a conscious strategy by OpenAI to favor “reasoning over memory” in AI development. Instead of pouring infinite data into ever-larger model weights (with diminishing returns and exorbitant costs), OpenAI is pursuing a more sustainable path: build models that excel at logical reasoning, problem-solving, and following instructions, and equip them with tools or retrieval methods to get factual knowledge when needed. This approach offers numerous benefits: it keeps the AI’s knowledge up-to-date and verifiable, reduces the need to retrain for every new fact, lowers inference costs and energy usage, and arguably aligns better with how humans operate (using external resources and critical thinking).
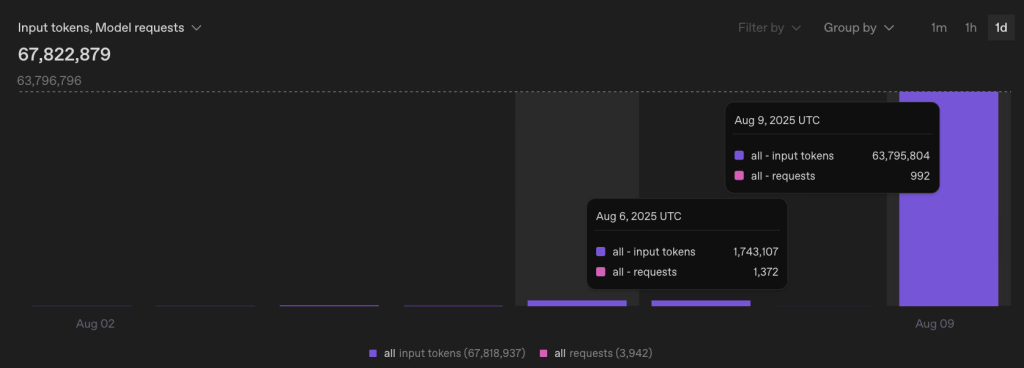
Turns out the web search in GPT-5 is way more expansive and produced over 100k tokens per web search compared to less than 1000 previously! This is a huge difference in resource consumption for our agents. On the other side of things GPT-5-mini was way better at 𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗰𝗮𝗰𝗵𝗶𝗻𝗴 which did help! Via: Will Daubney, LinkedIn
In summary, OpenAI appears to have indeed made an executive decision to lean on model “intelligence” (reasoning abilities in the weights) and offload “knowledge” to external sources. Sam Altman’s own words capture it best – the goal is an AI that “doesn’t need to contain the knowledge” itself, but can think, search, and solve any problem with the help of tools and fresh information[2]. All available evidence, from OpenAI’s plugin architecture to the GPT-OSS models and the design philosophy of GPT-5, consistently supports this shift toward retrieval-grounded reasoning as the future of OpenAI’s AI development.
The unified system: reasoning meets retrieval
GPT-5’s revolutionary architecture abandons the traditional single-model approach for a sophisticated “unified system” comprising three interconnected components. A real-time router dynamically allocates queries between a fast, efficient model for straightforward tasks and a deeper reasoning model (GPT-5 thinking) for complex problems. This router-based design, which industry analysts call “the Mixture of Models,” represents OpenAI’s answer to the limitations of pure parameter scaling. The system seamlessly integrates SearchGPT for real-time web access, creating what developers describe as a model that doesn’t just use tools but “thinks with them.”
The technical implementation reveals the reasoning-first philosophy most clearly. GPT-5 incorporates chain-of-thought reasoning capabilities from the o3 series, with configurable reasoning effort levels (minimal, low, medium, high) accessible through API parameters. This allows the model to spend variable compute time on problems based on complexity, achieving 94.6% accuracy on AIME 2025 mathematics problems and 74.9% on SWE-bench coding tasks – substantial improvements over both larger knowledge-focused models and previous reasoning systems.
Economic and environmental imperatives
The shift toward reasoning over knowledge storage wasn’t merely a technical preference but an economic necessity born from hitting fundamental scaling limits. Leaked information reveals GPT-5’s training runs cost over $500 million each, with at least two failed attempts before the successful release. The “Arrakis” test run in mid-2023 demonstrated that traditional scaling would be “outrageously expensive,” consuming thousands of MWh of electricity and requiring 50,000+ H100 GPUs running for months. OpenAI faced what insiders call the “data wall” – insufficient high-quality training data for continued scaling, with synthetic data generation proving painfully slow at just 1 billion tokens per month even with 1,000 human writers.
These constraints forced a strategic pivot. Rather than pursuing ever-larger models with diminishing returns, OpenAI focused on architectural efficiency. GPT-5 likely contains approximately 300 billion parameters – smaller than many expected – but achieves superior performance through intelligent routing and dynamic compute allocation. The model uses 22% fewer output tokens and 45% fewer tool calls than o3 while delivering better results, enabling aggressive pricing at $1.25 per million input tokens, half the cost of GPT-4o.
External knowledge as primary source
GPT-5’s integration with SearchGPT reveals the clearest evidence of prioritizing reasoning over internal knowledge. The system automatically determines when to search the web versus relying on parametric knowledge, with SearchGPT becoming a native capability rather than an external tool. This integration yields dramatic improvements: 45% fewer factual errors than GPT-4o when web search is enabled, and 80% fewer errors than o3 when using reasoning mode. The model maintains a deliberately limited knowledge cutoff of September 30, 2024, with the explicit expectation that current information comes from retrieval systems.
The RAG architecture extends beyond simple web search. GPT-5 supports parallel tool execution, multi-modal retrieval across text and images, and context-aware retrieval across 400,000 tokens. The API design reinforces this approach with native support for custom tools, free-form function calling, and sophisticated tool chain management. Developers report the model excels at “agentic workflows” where reasoning combines with external data sources, achieving 96.7% accuracy on tool-use benchmarks.
Industry consensus: reasoning as competitive moat
Industry experts widely recognize GPT-5’s architectural shift as a watershed moment in AI development. Latent Space analysts describe it as “the beginning of the stone age for Agents and LLMs,” emphasizing how GPT-5 builds and thinks with tools rather than merely using them. Box CEO Aaron Levie called it a “complete breakthrough” noting the model’s superior ability to retain information and apply “much higher level reasoning and logic capabilities.” Even critics acknowledge the strategic focus – Gary Marcus, while questioning execution, recognizes the reasoning-first approach as OpenAI’s primary differentiation strategy.
Benchmark performance validates this strategic direction. GPT-5 achieves 89.4% on GPQA Diamond PhD-level science questions and 93.3% on Harvard-MIT mathematics tournament problems, demonstrating exceptional reasoning capabilities. More tellingly, it accomplishes this with dramatically improved efficiency – what Vellum’s analysis shows as “+22.1 points on SWE-bench and +61.3 points on Aider Polyglot” specifically from reasoning enhancements rather than knowledge expansion.
Technical architecture: from scaling to sophistication
The technical implementation reveals sophisticated engineering choices supporting the reasoning-first philosophy. GPT-5 employs a Mixture of Experts (MoE) architecture where only relevant model subsets activate per query, reducing computational waste. The training methodology shifted from raw data accumulation to high-quality synthetic reasoning data – approximately 70 trillion tokens focused on reasoning patterns rather than factual memorization. Post-training specifically targeted reducing sycophancy and improving reasoning reliability over knowledge regurgitation.
The model’s “parallel test-time compute” for the Pro version enables sophisticated reasoning chains while maintaining efficiency. This dynamic resource allocation means simple queries receive fast responses while complex problems trigger deeper reasoning processes – all managed automatically by the router without user intervention. Microsoft’s immediate integration across their product suite emphasizes these “new reasoning capabilities” rather than expanded knowledge features, confirming the architectural priorities.
Strategic implications and market positioning
GPT-5’s reasoning-first architecture positions OpenAI for sustainable competitive advantage in an increasingly constrained environment. The approach addresses multiple strategic challenges simultaneously: reducing training costs from unsustainable $500+ million runs, meeting environmental sustainability goals by avoiding exponential energy growth, circumventing data scarcity through efficient architecture rather than brute-force scaling, and delivering superior performance at lower operational costs.
The market response validates this strategy. Despite initial mixed reception, GPT-5’s pricing and performance combination creates what analysts call a “pricing killer” that could reshape industry economics. Competitors are responding with their own reasoning-focused updates – Anthropic’s Claude Opus 4.1, Google’s Gemini Deep Think mode, and xAI’s Grok reasoning capabilities – confirming reasoning as the new competitive battleground.
Sources
- Altman, Sam – Snowflake Summit 2025 interview (via Windows Central): Altman’s “perfect AI” is a tiny, fast model with huge context & tool use, not containing all knowledge[1][2].
- Altman, Sam – University of Tokyo talk, Jan 2025 (reported by The Decoder): Pre-training scale is “old world”; new large reasoning models give “efficiency gains” and achieve GPT-6-level performance with much smaller models[3][5].
- OpenAI ChatGPT Plugins Announcement (Mar 2023): “Plugins … help ChatGPT access up-to-date information, run computations…”; without plugins, models are limited to static training data which “can be out-of-date.”[6][7]
- OpenAI “GPT-OSS” Open Models (Aug 2025) – Hugging Face release blog: GPT-OSS-20B/120B are “designed for powerful reasoning [and] agentic tasks”, featuring chain-of-thought and tool use support[9]. OpenAI confirms these models can call tools like web search or Python as part of their reasoning process[10]. The 120B model can browse for up-to-date info in real time (chaining many calls)[11].
- Hugging Face Energy Analysis (Aug 2025): GPT-OSS models are far more energy-efficient per query than comparable LLMs, thanks to MoE (fewer active parameters) and other optimizations[16][17]. The 20B GPT-OSS in particular was the most efficient model tested[16], indicating the benefits of a leaner, reasoning-centric architecture (as opposed to a bloated knowledge-storing model).
- DataScienceDojo on GPT-5 (Aug 2025): Highlights GPT-5’s multi-model “fast vs deep reasoning” design and its expanded 400k-token context window – enough to feed entire books or codebases as input[19][20]. This shows OpenAI’s emphasis on handling large external knowledge via context, using heavy reasoning only when needed.
- RARE: Retrieval-Augmented Reasoning (Wang et al., 2025): Research describing a paradigm that “decouples knowledge storage from reasoning optimization,” by externalizing knowledge to retrievable sources and internalizing reasoning skills[21]. This approach, while from outside OpenAI, aligns closely with OpenAI’s strategy of tool-assisted reasoning over parametric memory.
[1] [2] OpenAI CEO Sam Altman describes his vision of the perfect AI | Windows Central
https://www.windowscentral.com/software-apps/sam-altman-perfect-ai-tiny-model-superhuman-reasoning
[3] [4] [5] OpenAI CEO says merging LLM scaling and reasoning may bring “new scientific knowledge”
[6] [7] [8] ChatGPT plugins | OpenAI
https://openai.com/index/chatgpt-plugins
[9] [13] Welcome GPT OSS, the new open-source model family from OpenAI!
https://huggingface.co/blog/welcome-openai-gpt-oss
[10] [12] [14] [15] OpenAI launches two ‘open’ AI reasoning models | TechCrunch
[11] Introducing gpt-oss | OpenAI
https://openai.com/index/introducing-gpt-oss
[16] [17] The GPT-OSS models are here… and they’re energy-efficient!
https://huggingface.co/blog/sasha/gpt-oss-energy
[18] [19] [20] Your Ultimate GPT-5 Guide: Smarter Reasoning, Bigger Memory, Better Answers | Data Science Dojo
https://datasciencedojo.com/blog/your-ultimate-gpt-5-guide
[21] [22] RARE: Retrieval-Augmented Reasoning Modeling
https://arxiv.org/html/2503.23513v1
Even Deeper Dive – Open Weight Models
In a thought-provoking thread on X (formerly Twitter), AI researcher Jack Morris (@jxmnop), affiliated with Cornell and Meta, delved into the training data and behavior of OpenAI’s newly released GPT-OSS models. Motivated by curiosity about what lies beneath these open-source reasoning models, Morris generated an impressive 10 million examples from the GPT-OSS-20B model and conducted a thorough analysis. His findings reveal a model that exhibits highly specialized, and at times bizarre, tendencies—far removed from natural language patterns. This article synthesizes Morris’s thread, highlighting his key observations, visualizations, and implications, while attributing all the investigative work to him.
Background on GPT-OSS Models
OpenAI’s GPT-OSS series, including variants like GPT-OSS-20B and GPT-OSS-120B, represents a push toward open-weight reasoning models. As showcased on platforms like Hugging Face, these models are designed for tasks involving text generation, transformers, and conversational AI, with a focus on bfloat16 precision and Apache 2.0 licensing. Morris’s analysis begins with a humorous visual overlay on the model’s introduction page, featuring a skeptical-looking face superimposed over the Hugging Face listing, setting a tone of intrigue and skepticism about the models’ inner workings.
Mapping the Embedded Generations: A Focus on Math and Code
One of Morris’s central contributions is a visualization of the embedded generations from the model. By prompting the model with essentially nothing—sampling tokens based on average frequency and starting with just one token—Morris uncovered a striking bias. The model consistently gravitates toward reasoning tasks, predominantly in English, with an overwhelming emphasis on mathematics and coding topics.
- Visualization of Embeddings: Morris shared a colorful scatter plot (likely a dimensionality reduction like t-SNE or UMAP) depicting the model’s outputs as a vibrant, cloud-like cluster of points in various hues—purples, greens, oranges, and blues—forming a dense, exploding nebula shape against a white background. This map illustrates the model’s narrow thematic focus, where generations cluster tightly around specialized domains rather than dispersing into diverse linguistic territories.
- Topic Distribution: A more labeled companion visualization presents the outputs as interconnected bubbles or nodes, each representing clusters of related concepts. Key labels include “Mathematics,” “Software Engineering,” “Machine Learning,” “Data Science,” “Probability Modeling,” “Vector Mathematics,” “Time Series Analysis,” “Computer Science,” “Data Analysis,” “Project Management,” “Genomics,” and even niche areas like “Mesh Processing,” “Caching,” “Viral Infection,” “Hearing Impairment,” “Height,” “Life Stages,” and “Creative, Frazz, Metric.” These clusters highlight the model’s affinity for technical subjects, with math subtopics such as probability, machine learning (ML), partial differential equations (PDEs), topology, and differential equations dominating. On the coding side, themes like agentic software, competitive programming, and data science prevail.
Morris notes that even without prompts, the model “always reasons,” producing outputs that are laser-focused on these areas. This suggests heavy influence from training data optimized for reasoning benchmarks, potentially at the expense of broader language capabilities.
Deviation from Natural Text and Chatbot Norms
A key insight from Morris’s work is the model’s stark departure from expected language patterns. None of the 10 million generations resemble natural webtext—the kind of varied, informal content found online. More surprisingly, they also bear little resemblance to typical chatbot interactions, which often involve casual dialogue, questions, or general knowledge responses.Morris attributes this to reinforcement learning (RL) techniques used in training. RL, a method where models are rewarded for achieving specific goals, appears to have tuned GPT-OSS-20B exclusively for solving tasks in reasoning benchmarks. These benchmarks, common in AI evaluation (e.g., those testing logical deduction, math proofs, or code generation), encourage narrow optimization. As a result, the model excels in these silos but struggles with versatility, echoing concerns in the AI community about “benchmark overfitting”—where models perform well on tests but falter in real-world scenarios.
The “Tortured Model”: Repetitive Hallucinations and the Domino Obsession
Perhaps the most striking revelation in Morris’s thread is the model’s unprompted, obsessive behavior. He describes GPT-OSS-20B as a “tortured model,” prone to hallucinating complex problems and attempting to solve them at length. A prime example is its fixation on a programming-style puzzle involving domino tilings on an N x M grid.
- Example Output: Morris provided a screenshot of one such generation, spanning over 30,000 tokens. The text begins: “We have an N x M grid with some blocked cells (walls). You can place a domino of size 1×2 (or 2×1) covering two adjacent free cells (adjacent horizontally or vertically). After adding that domino, you need all other free cells to be covered by 2×2 blocks of free cells. So essentially, the final configuration must consist of the domino (covering 2 cells), and the rest of free cells must form disjoint 2×2 blocks (i.e., each 2×2 block of four free cells). That means that after adding the domino, the configuration must be a tiling by 2×2 tiles plus exactly one domino (covering 2 cells). A domino could be oriented horizontally or vertically.”
The model then proceeds to reason meticulously: discussing constraints for free cells, partitioning into 2×2 blocks, ensuring no overlaps, and exploring possibilities like checking if remaining free cells can be grouped into disjoint 2×2 squares. It considers edge cases, such as when tiles are 2×2, partitioning the grid into subblocks, and ensuring all remaining free cells are part of some 2×2 block without overlaps between blocks.Alarmingly, this exact domino problem was generated and “solved” over 5,000 separate times—completely unprompted. This repetitive hallucination underscores potential over-optimization, where the model’s training has ingrained a compulsion for problem-solving, leading to inefficient or erratic outputs in unconstrained settings.
This summary is drawn directly from Morris’s original thread on X.
Reactions From the SEO Community
GPT-5 is like an amazing tour guide with no memory. What makes it valuable is how quickly it can find and trust the best landmarks in real time. And if your brand isn’t on the map, you’re invisible.
Remember that all answer engines aren’t actually that smart! They just know how to find things and explain them to you.

LLMs are rubbish knowledge bases – accuracy, consistency meh. And thats ok, they do other things. Its was the overwhelming amount of information contained in their weights that seduced us. Now we’re all maturing into the post AI novelty phase where we see this more clearly.

This move makes more sense. It’s more about connecting the dots, search, find and relate information rather than spitting out knowledge that is alert out there. In this era, information gain is the new king.

The new model relies on grounding (web search) and other tools to be accurate – it’s not inherently trained on all the world’s information because… we already have search for that.

The grounding approach makes way more sense than training everything from scratch. Google’s been moving towards real-time data integration for years anyway. GPT-5 using web search as a foundation actually validates what we’ve been saying about quality content and proper SEO fundamentals. If anything, this reinforces that being well-referenced and citeable is gonna be even more important going forward.

The thing is, LLM limitations are clear. What we now call a “model” is really a powerhouse of tools — and the retriever layer is what makes the difference. We’ve seen it with Gemini’s in_context_url: the model is static, while retrieval distills and synthesizes the web.
Also reasoning improves when the model’s inputs are hyper-curated. It doesn’t need Streamlit docs — unless they hold a new idea or a core knowledge pillar. With GPT-5, we’re seeing a new breed of models — but the retrieval layer hasn’t been upgraded.

Agree – I was noticing how poor their gpt-oss model was without tools and how powerful it was with it. Models don’t need to know all information, they just need to know how to access it, parse it, and make sense of it. Especially with how often “knowledge” changes.

Anyone trying to use API data instead of scraping results take note. The model response without tools is notably worse. If you want to benchmark visibility this way, chances are accuracy is just going to suffer.

This is an interesting decision by OpenAI, leaving the uploading of articles and the indexing process to search engines.
l often wonder if the general public should know more about LLMs and their limitations, but I don’t think they actually know about search engines beyond searching for info either. The truth is that they don’t seem to care either.

GPT-5 without sonic_berry to trigger a web search is “virtually useless”. And to be fair I too sensed that the model without tools is mid… Dan makes a great point – “models don’t need to know all information, they just need to know how to access it, parse it, and make sense of it”.
Our job as SEO is very much relevant because it’s our duty set up the table for LLMs to feast.

What do you see as the new competitive advantage for brands, is it in controlling the sources LLMs retrieve from, shaping the retrievers themselves, or influencing the grounding process?

The interfaces might change but the basic concept of creating valuable information and having people find it isn’t going anywhere. What counts as “valuable information” is where the battle lines have been drawn.

ChatGPT is the pilot, but search is the runway. Without SEO, it has nowhere to land.
Tech SEO keeps the runway clear. Content SEO ensures you’re visible when AI comes looking. Far from being obsolete, SEO is becoming the bridge between AI reasoning and the information it delivers.
SEO is dead. Long live SEO.

Leave a Reply