
What is Selection Rate?
Selection Rate (SR) is a key performance metric for AI systems that measures the frequency with which an AI selects and incorporates a specific item from a total set of grounding results. It serves as the Gen AI-native equivalent of Click-Through Rate (CTR) in traditional digital interfaces.
SR = (Number of selections / Total available results) × 100
Unlike CTR, which requires explicit user interaction through clicking, SR captures implicit selection behavior where AI systems evaluate numerous search results but ground their answers in select sources. As AI systems increasingly operate without direct human interaction at each decision point, SR provides crucial insight into the “attention economy” of AI, revealing what information actually influences outputs versus what gets retrieved but ignored.
What is its Primary Bias?
Primary bias on SR is model’s internal relevance perception of the grounding entity.
Case Study
This can seem a little abstract at first so we’ll illustrate the concept on a real world example. Owayo is seen as very relevant for queries such as “custom cycling jerseys” and similar in the USA, as measured by Google AI Relevance feature in AI Rank.
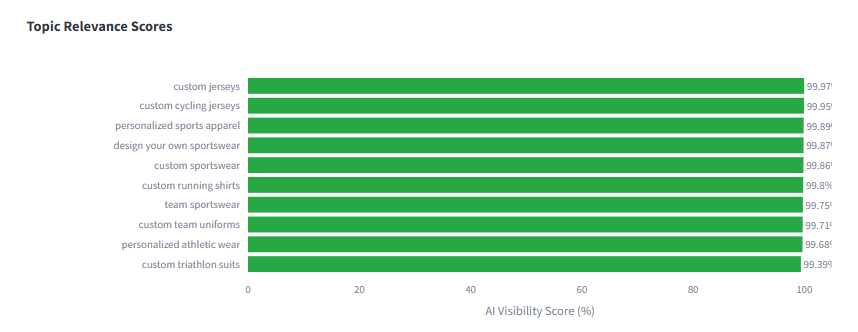
This means that if this brand is supplied as one of the items in the grounding corpus to the model (e.g. AI Mode, Gemini App, AI Overviews…etc) it’s much more likely to have a higher selection rate (SR) than the result where the primary bias sits at the low end of model confidence.
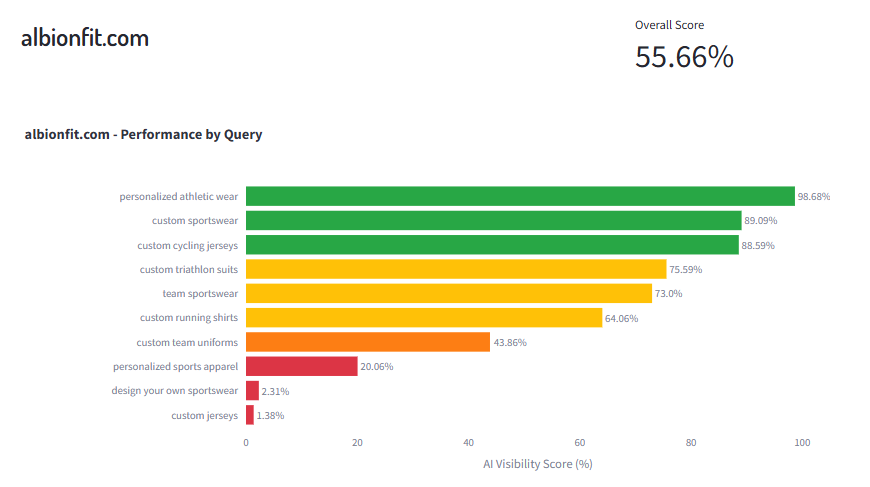
Albion Fit would likely be included in the selection of citations for topics related to personalised athletic wear, custom sportswear and custom cycling jerseys and perhaps even the other three (in yellow). But the primary bias will be skewing the SR against this brand for the bottom four entities.
Secondary biases include various forms of result attention and attractiveness including URL form, but primary bias is a challenge to influence. Why? Because it’s based on internal ungrounded model worldview and completely dependent on model training data.
Can something be done? Absolutely, both on-page and off-page work traditional SEO is familiar with can influence training data. Very unlikely for pre-training, LLM-s have moved past noisy web data in favour of clean curated datasets, but definitely a factor for ongoing fine-tuning.
How long does it take? Typically 3-6 months for major fine-tunes and sub-released and approximately annually for major model releases.
Primary Bias Detection
We use our Tree Walker algo to walk the probability paths of the things the model want to say about a brand and look for high uncertainty spots such as these:

The above brand could bolster brand association with “women’s” and “stylish” as the two least confident tokens in this representation. Here represented on a much more granular level:
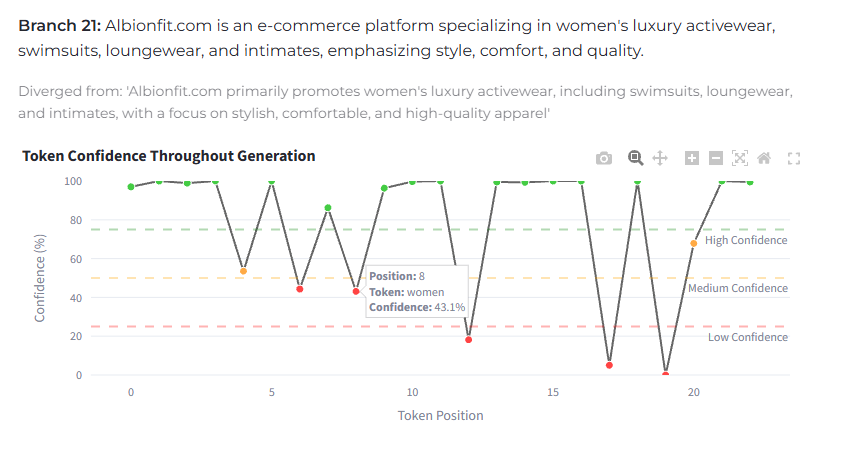
Tree Walker algo is already live and running but we’re only releasing the link gradually as we collect initial feedback and test for capacity. If you’re interested in early access please apply here:
Useful Links:
Bias in Search: Visibility, Perception, and Control
https://duaneforresterdecodes.substack.com/p/bias-in-search-visibility-perception
Leave a Reply