
Anastasia Kotsiubynska proposed a method to repurpose LLM-hallucinated URLs and set up redirects from hallucinated 404 instances with more than one session to most similar valid 200 pages.
I really like this, but since I work on websites with many millions of pages where volumes of hallucinated URLs are typically beyond the scope of manual human work I decided to automate this process by auto-mapping hallucinations to valid pages.
Log File Analysis

Other than taking the initial look at the server log files to get the idea of the types and volume of hallucinated URLs I’m really not keen on using it as a part of the pipeline as I’m aiming for simplicity.
| Field | Value |
|---|---|
| IP Address | 179.61.159.xxx |
| URL | /labs/interactive-demo |
| Time | 6/1/25, 9:55 AM |
| Size (bytes) | 60701 |
| Status | error 404 |
| Method | GET |
| Protocol | HTTP/1.1 |
| Referring URI | https://chatgpt.com/ |
| User Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 |
The above is one hallucination instance from dejan.ai log files and the key bits of information I need are:
- URL
- Status
- Referring URI
So for each 404 instance where a referral is https://chatgpt.com/ I can use both keyword and semantic similarity to map to the best existing page on the site. Keyword based matching can be extended by Levenshtein‐style fuzzy matching on top of keyword hits.
Semantic similarity obviously requires vector embeddings, and this requires careful consideration. Reasonable candidates for text embeddings include:
- URL Keywords
- Meta Data
- Page Content
In most cases URL-extracted keywords are the best choice. I say most cases because not all sites have meaningful, descriptive URLs.
Why URL keywords?
It’s because of one important quirk associated with cosine similarity. It’s biased by input text length due to additional semantic context and keyword diversity. This means that when selecting between two perfectly reasonable semantic matches it will always pick a shorter one as a better match.
Here’s an example:
Assume the hallucinated URL is: https://dejan.ai/labs/interactive-demo and since there’s no page content or meta data we go by URL keyword extraction and end up with labs, interactive, and demo.
We’ll test them with text variants as potential matching targets:
- “Discover the Interactive Demo by DEJAN LABS, an immersive platform designed to showcase innovative technologies through direct engagement. Explore hands-on demonstrations, experience live interactions with advanced AI solutions, and witness firsthand how DEJAN LABS transforms complex concepts into intuitive, interactive experiences.”,
- “Discover the Interactive Demo by DEJAN LABS, an immersive platform designed to showcase innovative technologies through direct engagement.”,
- “interactive feature”,
- “labs feature demo”,
- “labs interactive seo demo”
Semantic Similarity
- Similarity with target 1: 0.8424
- Similarity with target 2: 0.8468
- Similarity with target 3: 0.6897
- Similarity with target 4: 0.9336 – WINNER (“labs feature demo”)
- Similarity with target 5: 0.8801
Code
import torch
from transformers import AutoTokenizer, AutoModel
import torch.nn.functional as F
# Model setup
model_name = "mixedbread-ai/mxbai-embed-large-v1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# Input keywords
input_text = "labs interactive demo"
# Target texts
targets = [
"Discover the Interactive Demo by DEJAN LABS, an immersive platform designed to showcase innovative technologies through direct engagement. Explore hands-on demonstrations, experience live interactions with advanced AI solutions, and witness firsthand how DEJAN LABS transforms complex concepts into intuitive, interactive experiences.",
"Discover the Interactive Demo by DEJAN LABS, an immersive platform designed to showcase innovative technologies through direct engagement.",
"interactive feature",
"labs feature demo",
"labs interactive seo demo"
]
def embed(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
with torch.no_grad():
output = model(**inputs)
embeddings = output.last_hidden_state.mean(dim=1)
return embeddings
# Embed input and targets
input_embed = embed(input_text)
target_embeds = [embed(t) for t in targets]
# Calculate cosine similarities
similarities = [F.cosine_similarity(input_embed, tgt_embed).item() for tgt_embed in target_embeds]
# Display results
for i, sim in enumerate(similarities, 1):
print(f"Similarity with target {i}: {sim:.4f}")
I’m currently working on a 25 million page website and embedding generation takes about 24 hours to complete.
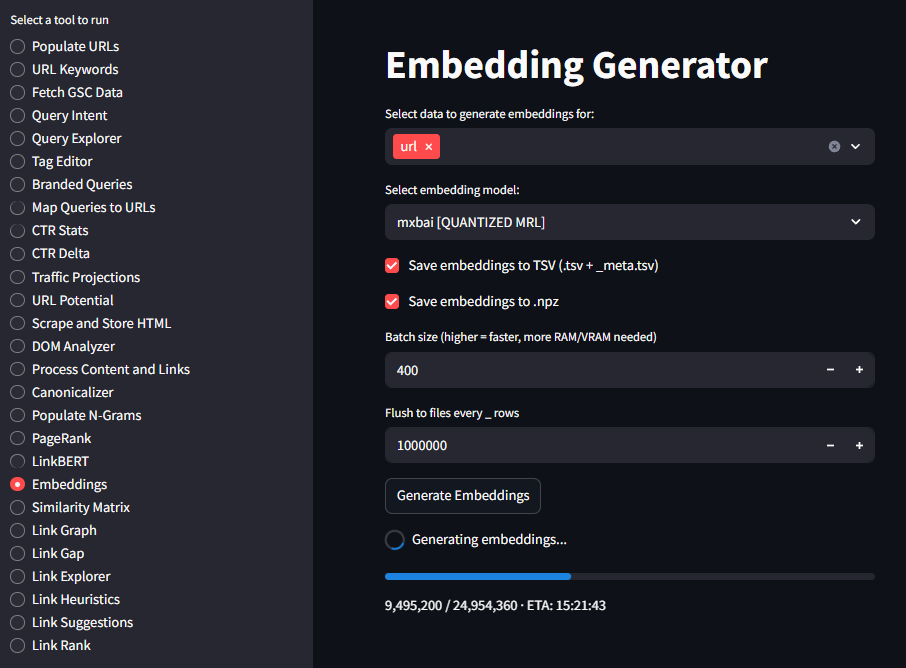
I’ve opted in for a custom, binary compression on my embeddings so the final output will be only around 30GB.
Note: In most cases this is complete overengineering and you can probably get by keyword matching, but I have further uses for vector embeddings (e.g. internal link optimisation) and it makes sense to do this. For small sites, manual mapping is a perfectly reasonable way to go.
What to do with this?
What happens next is up to you. Personally, I will not implement any redirects – too risky. Cosine similarity is blind to common sense and will find whatever is closest matching which could include explicit, illegal and embarrassing things.
My choice is to keep 404 pages and either recommend top related pages or render the page content or snipped as part of the 404 page. This provides user with a place to go while avoiding unwanted associations.
Leave a Reply