
OpenAI recently released research showing that AI models can be built with far fewer active connections inside them. This makes them easier to understand because each part of the model does fewer things and is less tangled up with everything else. Think of it like taking a spaghetti bowl and straightening the noodles into clean, separate strands.
Why does this matter? Because AI search engines like ChatGPT, Perplexity, Gemini and eventually Google Search use models that make decisions about which brands, answers and sources to show. If we understand how the model thinks internally, we can better understand why it prefers some sources over others, and how to influence these preferences through better content, clearer signals and stronger entity strategies.
OpenAI’s research shows that:
- Models can be trained to be much more interpretable without losing ability.
- Small “circuits” inside a model are responsible for specific behaviours.
- These circuits can be isolated, tested, broken, improved or replaced.
For AI SEO, this is the direction we’ve been predicting: moving from guessing what an AI model prefers to actually measuring and analysing the internal structures that influence brand visibility. This pushes SEO into a new domain—less about “ranking signals” and more about “latent circuits” shaping how models choose, cite and trust content.
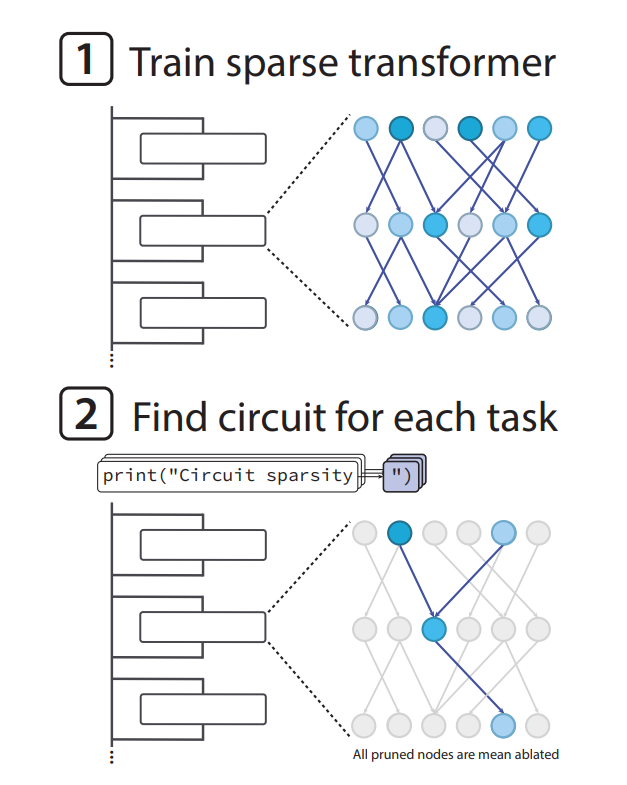
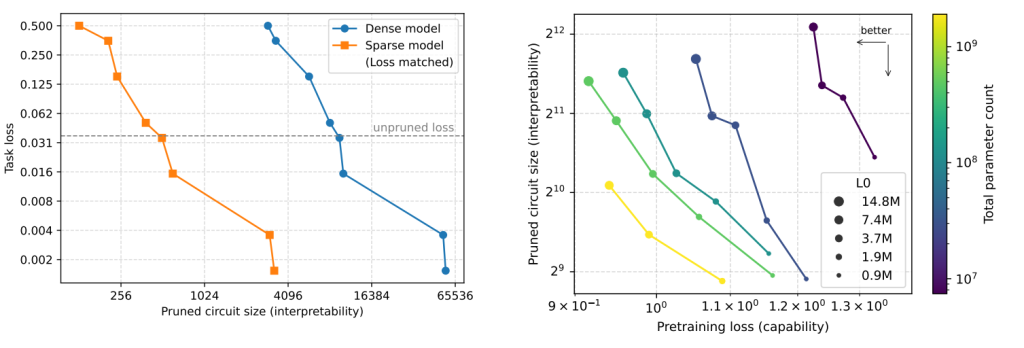
1. The core idea: extreme sparsity
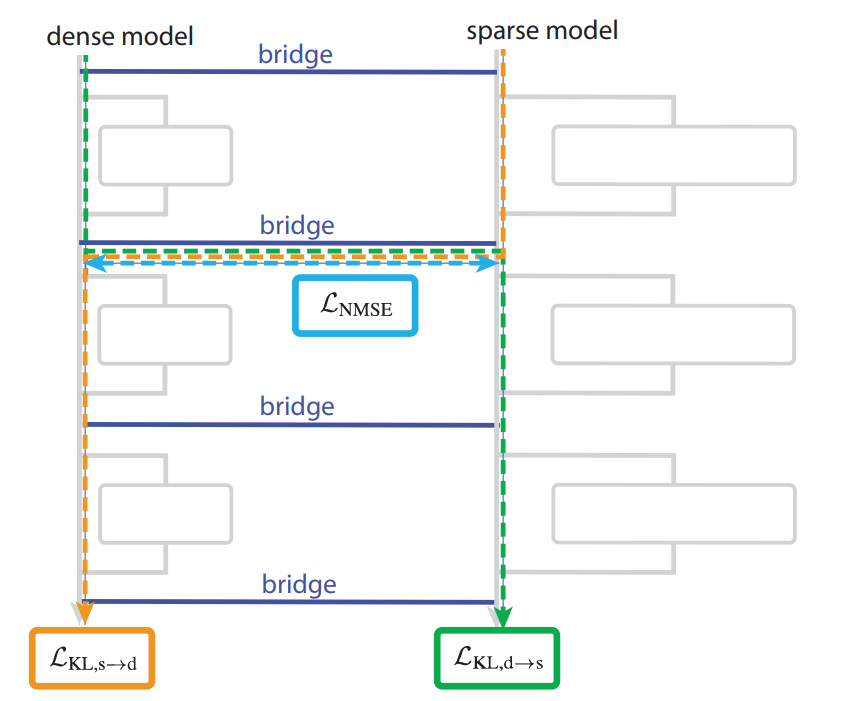
Traditional transformers are dense: every neuron influences many others, and it’s difficult to identify which internal component does what. OpenAI takes the opposite approach: train the model so most weights are zero. This forces the model to develop clean, minimal pathways for specific tasks.
The result is a set of “sparse circuits”—small subgraphs of the model that are both necessary and sufficient for a particular behaviour.
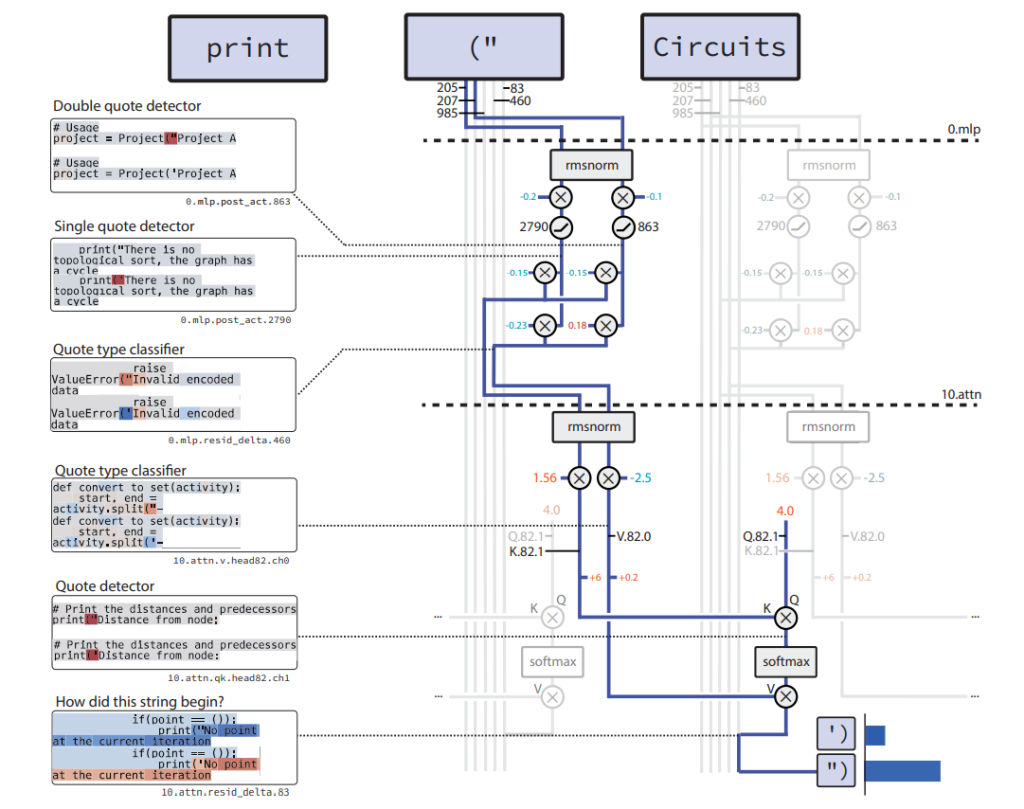
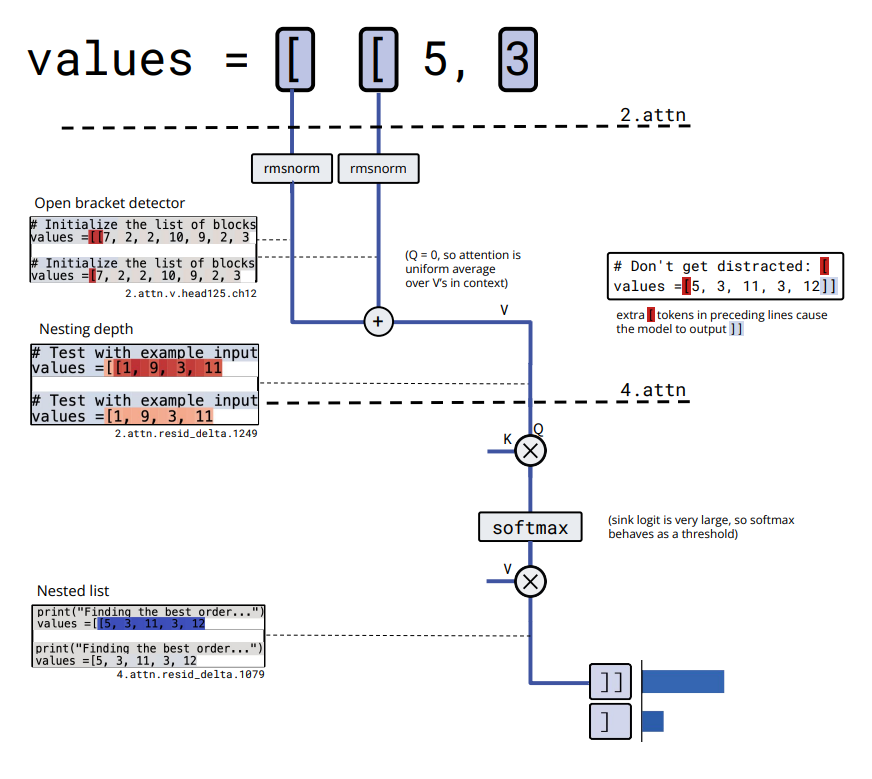
2. How they found circuits
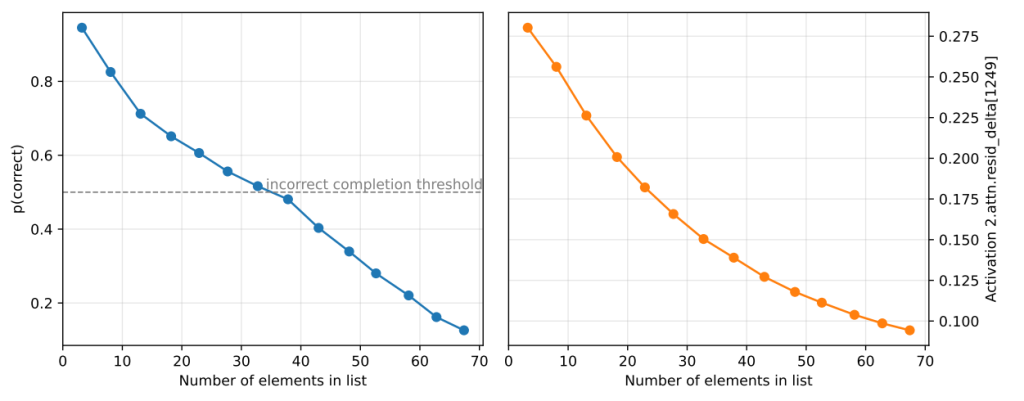
The researchers used algorithmic tasks (e.g. matching quotation marks in Python code) because these tasks have unambiguous rules. This allows them to identify exactly which neurons and attention heads implement the behaviour.
When they prune the model to only the essential connections:
- The circuit still performs the task correctly.
- Removing any connection breaks the behaviour.
- Adding the circuit into another model enables that behaviour.
This is the clearest evidence so far that transformer models contain genuine, discrete computational structures comparable to small programs.
3. Why this matters for interpretability
There are two main ways to interpret models:
- Chain-of-thought: the model explains its reasoning in natural language.
- Mechanistic interpretability: we trace the real computational steps inside the model.
Chain-of-thought is useful but does not show how the model really works. Mechanistic interpretability does. Sparse circuits make this approach feasible, scalable and testable.
4. Why this matters for AI SEO
AI search engines rely on internal model behaviour to choose what content to surface, which brands to trust, and which sources to cite. Understanding those behaviours at the circuit level means we can:
- Identify why the model favours certain brands.
- Detect circuits that misrepresent or ignore a brand.
- Analyse how entity relationships form inside the model.
- Diagnose why a domain is frequently excluded from citations.
- Influence brand perception through targeted content and data strategies.
This shifts AI SEO from surface-level tactics into model-level strategy. Instead of guessing what the model wants, we analyse how the model actually computes relevance and trust.
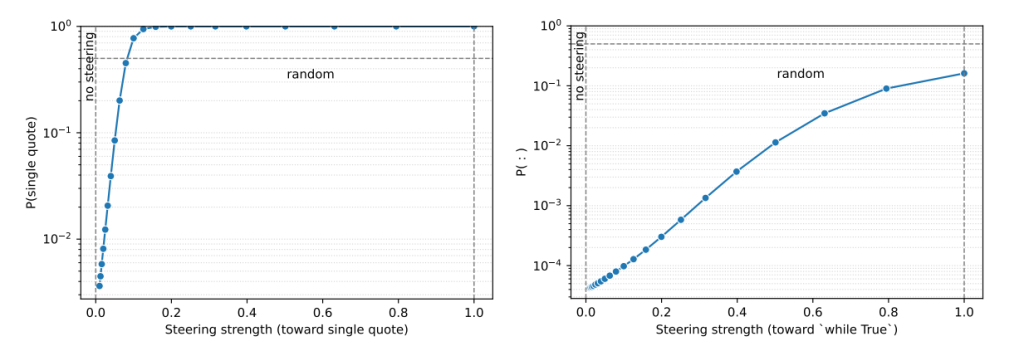
5. Steering and probing models becomes more precise
Sparse circuits open a new practical workflow:
- Probe: detect how a model internally represents a brand or source.
- Localise: find the internal features or circuits responsible.
- Intervene: improve or correct the signals shaping those circuits.
- Validate: re-run probes to confirm the shift.
This eventually becomes the backbone of advanced AI SEO audits and brand influence strategies.
6. This also benefits SEO tooling
Models used for content detection, spam classification, query ranking and summarisation can become safer and more accurate when we understand their internal circuits.
For example:
- AI detectors can avoid false positives by ensuring circuits aren’t misfiring on writing style or dialect.
- Link spam models can distinguish real editorial citations from inorganic patterns.
- Query interpretation models can be debugged when they fail to understand user intent.
Sparse circuits reduce ambiguity and allow precise correction.
7. Long-term impact
The long-term trajectory is clear: models will remain large and dense at production scale, but smaller, sparse, interpretable versions will be extracted to help us understand and evaluate the big models’ behaviour.
This gives SEO teams realistic tooling for:
- Brand representation monitoring
- Content association analysis
- Entity graph auditing
- Citation and source trust modelling
The direction of travel is away from “black box SEO” and toward an engineering discipline based on measurable signals inside the model itself.
OpenAI’s sparse-circuit work demonstrates that AI behaviours are not mystical or opaque: they are implemented by small, discoverable, modifiable computational structures. For AI SEO, this unlocks a future where we can diagnose visibility issues precisely, influence model behaviour strategically, and build reliable AI tools with transparent internal workings.
Source: https://github.com/openai/circuit_sparsity/
Article: https://openai.com/index/understanding-neural-networks-through-sparse-circuits/

Leave a Reply