
The answer is no.
There’s a widely held intuition in SEO and ecommerce search: short queries have high volume, long queries have low volume. “laptop” gets millions of searches. “left handed ergonomic vertical mouse wireless” does not. It feels obvious.
But is query length actually a reliable predictor of search volume? Or is it a convenient heuristic that falls apart under scrutiny?
I tested this using 39.6 million unique Amazon search queries with known volume data, spanning everything from head terms like “airpods” to long-tail queries like “replacement gasket for instant pot duo 8 quart.” The results surprised me.
The Setup
I bucketed queries into five volume classes based on their occurrence count across nearly 400 million Amazon search sessions:
| Class | Occurrences | Unique Queries |
|---|---|---|
| Very High | 10,000+ | ~18K |
| High | 1,000–9,999 | ~30K |
| Medium | 100–999 | ~321K |
| Low | 10–99 | ~4.6M |
| Very Low | <10 | ~34.7M |
Then I measured two simple length metrics — character count and word count — across a balanced sample of 5,000 queries per class. The question: can you predict volume class from length alone?
The Averages Look Promising
At first glance, the data confirms the intuition. There’s a clean trend:
| Volume Class | Avg Characters | Avg Words | Median Characters |
|---|---|---|---|
| Very High | 16.0 | 2.6 | 16 |
| High | 17.2 | 2.8 | 16 |
| Medium | 19.6 | 3.2 | 19 |
| Low | 22.3 | 3.7 | 21 |
| Very Low | 23.2 | 3.9 | 22 |
Very high volume queries average 16 characters and 2.6 words. Very low volume queries average 23 characters and 3.9 words. The pattern is monotonic and statistically significant (p ≈ 0). Case closed?
Not quite.
The Distributions Tell a Different Story
The problem becomes obvious when you look at the actual distributions instead of the averages. The character count distributions for all five classes overlap almost entirely:
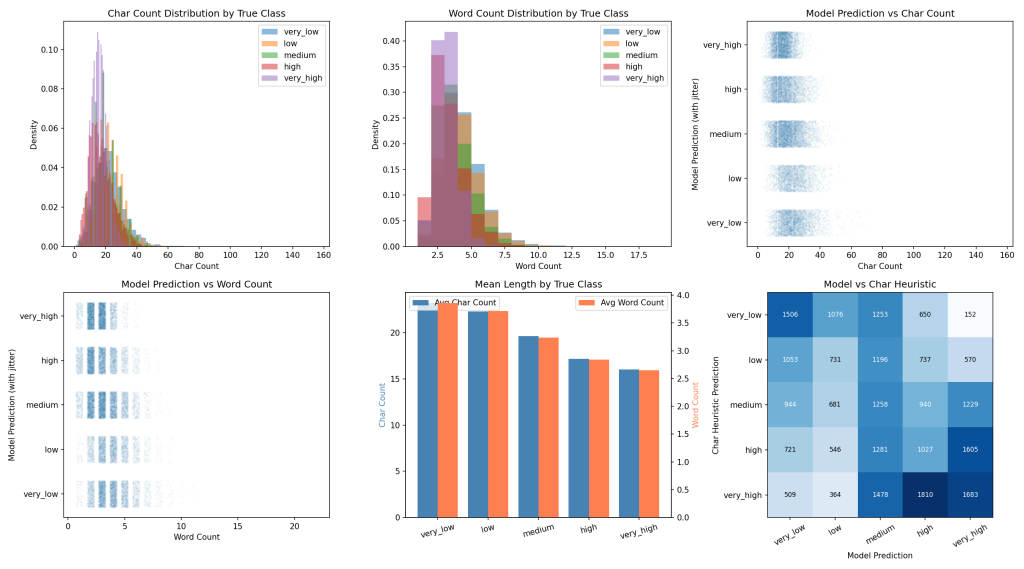
- A 15-character query could be very high volume (“wireless mouse”) or very low volume (“purple cat bed”)
- A 3-word query could be anything from very high (“protein powder”) to very low (“bamboo utensil set”)
- The median difference between very high and very low is only 6 characters
When every class shares most of the same length range, length simply can’t discriminate between them.
Quantifying the Failure
To put a number on it, I built simple heuristic classifiers — one using character count, one using word count — that bin queries into volume classes based on percentile thresholds. For a fair comparison, I also trained a DeBERTa language model on the same data to predict volume class from the query text itself.
The results:
| Method | Accuracy | Spearman Correlation |
|---|---|---|
| DeBERTa model | 72.1% | 0.896 |
| Word count heuristic | 25.4% | -0.345 |
| Char count heuristic | 24.9% | -0.336 |
The length heuristics achieved roughly 25% accuracy — barely above random chance for a 5-class problem (20%). The Spearman correlation between true volume class and query length is only -0.34. For comparison, the trained model achieved 0.90.
The agreement rate between the model’s predictions and the length heuristic’s predictions? Just 24–25%. They mostly disagree, meaning the model is learning something fundamentally different from query length.
What Does the Model Actually Learn?
If not length, what signals is the model picking up? Looking at its predictions reveals some patterns:
Brand recognition. “airpods” (9 chars) → very high. The model learns that certain brand names are inherently high-volume. A character-count heuristic has no concept of brand equity.
Category head terms. “laptop” and “headphones” and “dog food” — the model recognizes generic product categories that serve as entry points for broad shopping intent. These are short, but their volume comes from being category names, not from being short.
Specificity markers. “cast iron skillet 12 inch” → medium. “replacement gasket for instant pot duo 8 quart” → very low. Both are moderately long, but the model distinguishes them based on how many qualifiers narrow the intent. Size specifications, compatibility constraints, and material callouts are signals of niche demand.
The middle is messy. The model struggles most with the low class (F1: 0.39), which sits in an ambiguous zone between medium and very low. These queries are often 3–4 words, moderately specific, and could plausibly land in either adjacent bucket. This is arguably a labeling boundary problem more than a modeling problem.
Why the Intuition Persists
The “short = high volume” heuristic isn’t wrong — it’s just weak. There is a real negative correlation between length and volume. The averages are monotonic. If you had to make a single binary bet — “is this 2-word query higher volume than this 7-word query?” — you’d be right more often than not.
But for any practical application — keyword prioritization, bid optimization, content strategy — a 25% accuracy classifier is useless. You’d misclassify three out of four queries.
The fundamental issue is that query length is a confounded signal. Short queries aren’t high volume because they’re short. They’re high volume because they tend to be generic category terms or popular brand names, and those things happen to be expressible in few words. The causal arrow runs from semantic content to volume, with length as a side effect.
The ‘Nonsense Test’
As a final sanity check, I ran the model on completely made-up queries of varying lengths. If the model were simply learning “short = high volume,” nonsensical short queries should still predict high volume. They don’t.
Query Prediction Conf
--------------------------------------------------------------------
zxqwv very_low 52.9%
blorf very_low 50.0%
aa high 55.8%
flurb snax very_low 63.1%
gleep borp very_low 54.6%
wonky plim dazzle very_low 50.3%
grax tooble fent very_low 57.6%
blorpy zint crumble woft very_low 59.3%
quax shimble trogg fleem narg very_low 59.9%
zixo tramble woft greel spunt naffle blorvish very_low 62.5%
wireless blorf adapter very_low 64.5%
organic flurb capsules very_low 72.9%
replacement grax for shimble 8 quart very_low 76.2%
x high 93.1%
q high 91.9%
asdfghjkl very_low 52.4%
aaa bbb ccc ddd eee fff ggg very_low 57.5%Nearly every nonsensical query — regardless of length — is classified as very low volume. One-word gibberish like “blorf” and “zxqwv” are not mistaken for head terms just because they’re short.
The exceptions are telling. “x” and “q” predict high with 93% confidence — because single-letter searches are genuinely common on Amazon (people search “q” for Q-tips, “x” for Xbox). “aa” predicts high because AA batteries are a real product. The model has learned what people actually search for, not how many characters they typed.
Meanwhile, queries with real English structure but nonsense nouns — “wireless blorf adapter,” “organic flurb capsules” — are confidently classified as very low. The model recognizes the product-query template but knows “blorf” isn’t a real product. It even assigns higher confidence to “replacement grax for shimble 8 quart” (76.2%) because the long-tail structure plus unrecognizable nouns is a double signal of obscurity.
The confidence scores are also well-calibrated: nonsense queries hover around 50–60% confidence, reflecting genuine uncertainty, while real queries like “laptop” or “airpods” score 93%+. The model knows what it doesn’t know.
Implications
For SEO/SEM practitioners: Don’t use query length as a proxy for volume in your tooling or mental models. A 2-word query can easily be very low volume (“argon regulator”), and a 5-word query can be high volume (“noise cancelling earbuds for sleeping”). Use actual volume data, or if you need estimates, use a model trained on semantics.
For search engineers: Query length features may add marginal value in a volume prediction model, but they’re dominated by semantic features. A language model that understands what queries mean dramatically outperforms one that counts characters.
For data scientists: This is a nice reminder that when averages show a clean trend, always check the distributions. A monotonic trend in means can coexist with nearly complete overlap in distributions — and the overlap is what determines classifier performance.
Methodology Note
- Dataset: Amazon Shopping Queries, 395.5M sessions, 39.6M unique queries
- Model: DeBERTa v3 base, fine-tuned for 20 epochs on balanced samples (30K–100K per class)
- Heuristic classifiers: quintile-based binning on character/word count
- Evaluation: 25K balanced sample (5K per class), Spearman rank correlation, classification accuracy
- All code and data processing done in DuckDB + PyTorch
Leave a Reply