An excerpt from François Chollet’s Deep Learning with Python exploring the manifold hypothesis and how structured information enables deep learning to work.
Why does artificial intelligence actually work? It turns out, the secret is not just in the algorithms, but in the structure of the real world itself.
Think about all the possible ways you can arrange pixels on a screen. The number is astronomical. Yet, the real-world images we care about, like human faces or handwritten numbers, occupy only a tiny, highly structured fraction of that space. This is the manifold hypothesis. It suggests that all natural data lies on a lower-dimensional surface within a much larger space.
We humans do this naturally. To survive, our brains evolved to compress the chaotic, high-dimensional world into simple symbols and concepts.
Large language models do the exact same thing. They map complex ideas into what is called a latent space. Just as we might compress a complex person into a simple label, like a scientist or an expert, machine learning models organize massive amounts of data into simplified, multidimensional maps.
By exploring this latent space, we can see how ideas connect. Two concepts that seem completely unrelated might actually be right next to each other when viewed from the right angle. It allows us to probe the hidden patterns of our world and discover the true nature of information.

Here’s a powerful excerpt from “Deep Learning with Python” by François Chollet”:
The nature of generalisation in deep learning has rather little to do with the deep learning models themselves and much to do with the structure of the information in the real world.

The input to an MNIST classifier (before preprocessing) is a 28 × 28 array of integers between 0 and 255. The total number of possible input values is thus 256 to the power of 784 — much greater than the number of atoms in the universe.

However, very few of these inputs would look like valid MNIST samples: actual handwritten digits occupy only a tiny subspace of the parent space of all possible 28 × 28 integer arrays. What’s more, this subspace isn’t just a set of points sprinkled at random in the parent space: it is highly structured.
A manifold is a lower dimensional subspace of a parent space that is locally similar to a linear Euclidean space.
A smooth curve on a plane is a 1D manifold within a 2D space because for every point of the curve you can draw a tangent, a curve can be approximated by a line at every point. A smooth surface with a 3D space is a 2D manifold and so on.
The manifold hypothesis posits that all natural data lies on a low dimensional manifold within high dimensional space where its encoded.
That’s a pretty strong statement about the structure of the information in the universe. As far as we know it’s accurate and its why deep learning works.
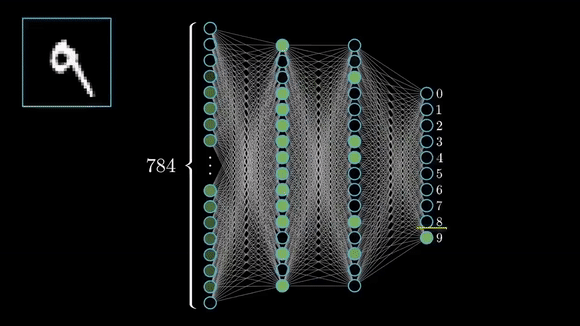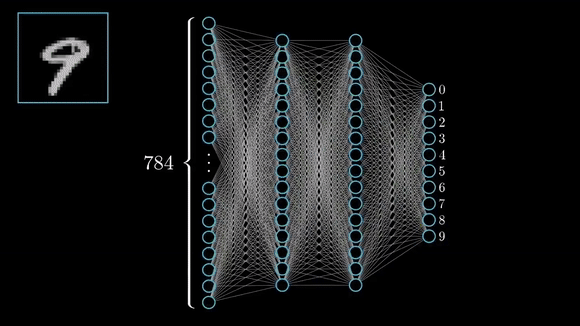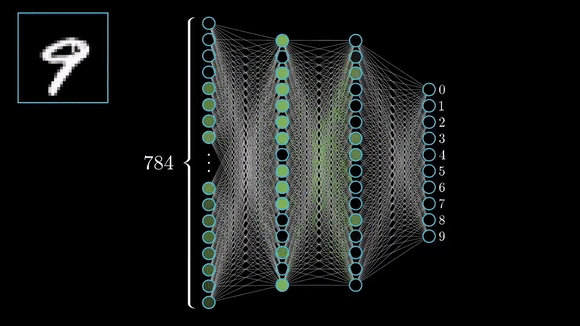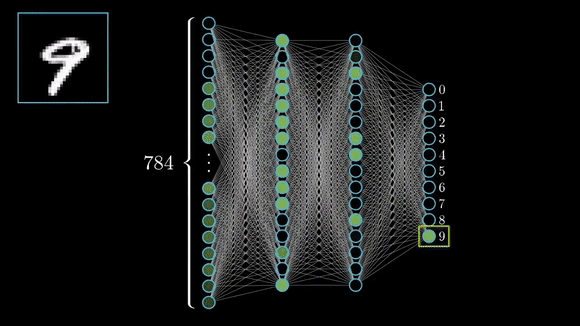
It’s true for MNIST digits, but also for human faces, tree morphology, the sound of human voice and even natural language.
Intelligence is an emergent property of structured complexity which is why we’re conscious and able to think. But 100,000 years ago energy meant survival and so we evolved a neural network optimised for efficiency.
We reduce the world around us to lower-dimensional representations of high dimensional input and stimuli.
We use symbols, icons and other information compression entities.
We do it. LLMs do it:
Dan Petrovic
Compression:
“The SEO Scientist”
Representation: Known for his methodical, experimental approach to SEO, Dan is often associated with data-driven experimentation, technical SEO insights, and thought leadership in testing how Google works.
Lily Ray
Compression:
“The E-A-T Expert”
Representation: Lily is widely associated with expertise in Google’s E-A-T (Expertise, Authoritativeness, Trustworthiness) guidelines and how they relate to content strategy. She’s also often perceived as a voice of clarity when it comes to interpreting Google’s quality updates.
Mike King (iPullRank)
Compression:
“The Hip-Hop SEO”
Representation: Mike is recognized for blending creativity with technical expertise, often known as the guy who talks about SEO while connecting it to his background in hip-hop. He’s also the go-to figure for technical SEO and machine learning in SEO.
Two seemingly distant concepts may have a latent proximity in the latent space.
Likewise concepts that appear close may be distant when “viewed” from a different perspective.
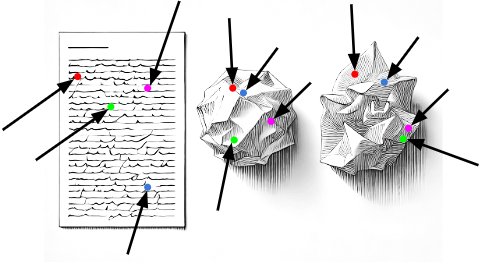
We’re now able to probe the latent space, view information from countless angles, find hidden patterns, connections and discover the truth about the very nature of information around us.
Visual Guides to Deep Learning
https://dejan.ai/ml-resources/
 Dan Petrovic ·
Dec 26, 14:42
Dan Petrovic ·
Dec 26, 14:42