
Chrome is about to give all websites a voice through a built-in version of Gemini. Your visitors will have completely private chats with it. No external API calls to Google’s servers and once loaded you can even switch off the internet – it will still work!
What will they talk about?
The Silent Web is Over
Imagine this: a user lands on your e-commerce product page. Instead of scrolling, they open a chat sidebar in their browser and ask, “What’s the return policy on this?” “Does this come in blue?” “Compare this to the other model I was looking at.”
And your website answers. Instantly. Privately. Offline.
This isn’t a third-party chatbot. This is Chrome’s built-in Gemini Nano model, acting as an intelligent interface directly to your content. The conversation is happening, with or without you. What your website “says” in that chat is determined not by a script you wrote, but by how deeply the browser understands your page.
| API | Primary Function | Input | Output | Key Feature |
| LanguageModel | General-purpose prompting and generation | Text, Image, Audio | Text / Structured Text | Multimodality, Conversation, JSON Schema output |
| Writer | Generate new text | Text prompt | Text (String) | Control over absolute tone, format, length |
| Rewriter | Modify existing text | Text | Text (String) | Control over relative tone, format, length |
| Summarizer | Condense long text | Text | Text (String) | Specific summary types (TLDR, key points) |
| Proofreader | Correct grammar and spelling | Text | Structured Correction Data | Detailed, structured error analysis |
| Translator | Translate text | Text | Text (String) | Language-to-language conversion |
| LanguageDetector | Identify language(s) | Text | Language codes + confidence | Language identification with confidence scores |
I’ve been analyzing the internal mechanisms Chrome uses to make this happen, and it’s a game-changer. The way Google parses your page for its on-device AI isn’t just a glimpse into the future; it’s a blueprint for optimizing for all conversational AI, from assistants to the next generation of search.
Welcome to the new era of SEO. Let’s break down the code.
Part 1: The AI’s “Eyes” – How Gemini Reads Your Page (Content Extraction & Accessibility)
Before Gemini can “speak” for your website, it has to “read” it. This isn’t the simple text extraction of old. Chrome performs a two-stage process that’s more like building a semantic brain map of your page.
- Stage 1: The Structural X-Ray (Annotated Page Content – APC)
- I’ll show you how Chrome’s Content Extraction module moves past the raw HTML and sees your page as a structured set of actionable components. It’s not just a wall of text; it’s a collection of paragraphs, lists, tables, images with captions, and forms with specific fields. (This is where you show a simple <div> vs a semantic <article> with <p> tags and explain why the latter is a richer input for the AI).
- The SEO Takeaway: We’ve been talking about “chunking” for AI. Chrome is already doing it based on your semantic HTML. Your <h1>, <p>, <ul> tags are no longer just styling hooks; they are the fundamental building blocks of your site’s conversational ability.
- Stage 2: The Semantic “Soul” (The Accessibility Tree)
- This is the mind-blowing part. The most critical data source for Gemini’s understanding isn’t a new meta tag; it’s the Accessibility Tree.
- I’ll explain how this tree, traditionally for screen readers, provides the unambiguous meaning behind your visuals. It tells Gemini: “This div isn’t just a div, it’s a button.” “This text is the label for that input.” “This section is the <main> content, and this is a <nav>.”
- The SEO Takeaway: Your accessibility audit is now your primary Gemini optimization tool. aria-label, role attributes, and proper semantic structure are no longer just compliance checkboxes. They are direct instructions to the AI about the purpose and function of every element on your page. A semantically clean, accessible site will have a far more intelligent and accurate conversation with the user.
Part 2: The AI’s “Brain” – On-Device Inference (The WebNN Engine)
So, Chrome has this perfect, structured understanding of your page. What happens next? This is where the magic of on-device AI comes in.
- No API Calls, No Server Logs: I’ll explain how the Machine Learning (ML) module and its WebNN API act as a local, on-device engine. The extracted page content is fed directly to Gemini Nano running on the user’s hardware.
- The “Black Box” is on Your Device: This means the conversation is completely private. But it also means there’s no server-side “Gemini index” to optimize for in the traditional sense. You can’t game a log file that doesn’t exist.
- The SEO Takeaway: Optimization shifts from pleasing a remote crawler to providing the most unambiguous, self-contained context possible on the page itself. Your page is the dataset. If the answer isn’t clearly structured within your content, Gemini Nano won’t be able to find it.
Part 3: The AI’s “Voice” – The Application Layer (The Conversational Interface)
This is where it all comes together for the user.
- The window.ai Object: I’ll introduce the high-level AI module that developers (and the browser UI itself) will use. Capabilities like summarize(), rewrite(), and prompt() are the verbs of this new conversational web.
- Gemini as Your Site’s Spokesperson: When a user asks, “What are the key points of this article?”, the summarize() function is triggered. Gemini Nano, using the semantically rich data from APC and the Accessibility Tree, generates the summary. The quality of that summary is a direct reflection of the quality and clarity of your content structure.
- Actionable Takeaway (The Ultimate Realization for SEOs): You are no longer just writing content for a human to read from top to bottom. You are creating a knowledge base that an AI will query on the user’s behalf.
- Is your return policy buried in a long paragraph, or is it in a clearly marked-up list under an <h2> titled “Return Policy”?
- Are your product specs in a <table> with <th> headers, or are they a series of disconnected <div>s?
- Is your “Buy Now” call-to-action a semantic <button>, or a <span> with a click handler that AI might not recognize as the primary conversion point?
Your New Job Title is “AI Conversation Designer”
No, I’m just kidding. We don’t need any more titles, but it is another hat to wear.
The panic around AI in SEO is understandable, but it’s focused on the wrong things. We’ve been chasing algorithms when the real shift is happening right inside the browser.
The future of SEO isn’t about gaming vector databases. It’s about architecting content with such profound semantic clarity that it can hold a coherent, accurate, and helpful conversation with an AI agent.
Everything you’ve learned about semantic HTML, clear content structure, and accessibility is the foundation. Now, it’s time to apply that knowledge not just to rank on a results page, but to empower your website to speak for itself.
The conversation is starting. Make sure your website has something intelligent to say.
A Technical Analysis of the AI Content Pipeline
The integration of on-device models like Gemini Nano into the Chrome browser necessitates a robust pipeline for parsing, understanding, and structuring web content. This process transforms a visually rendered webpage into a machine-readable, semantically rich format suitable for AI inference. This analysis details the key Blink modules and the technical data flow, from the rendered page to the AI’s input context.
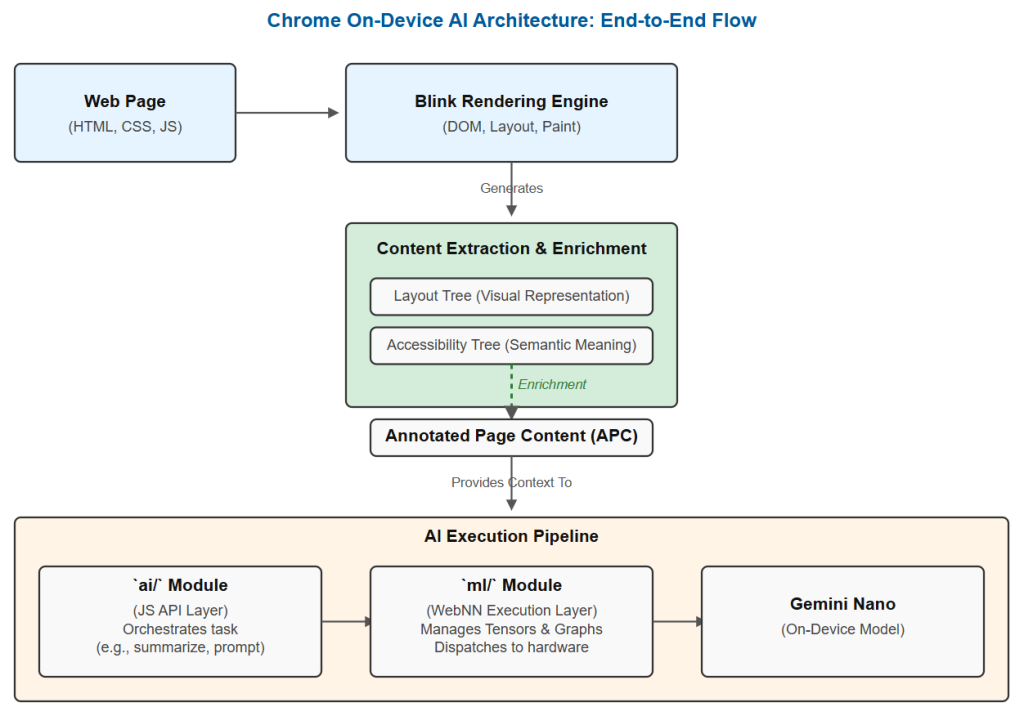
The pipeline involves a layered system where rendering primitives provide the foundation for semantic analysis and content extraction, which in turn prepare the data for the AI’s application and execution layers.
1. The Prerequisite: The Layout Tree
The foundational input for this entire process is not the raw DOM Tree, but the Layout Tree.
- DOM Tree: The direct representation of the HTML document structure. It includes all nodes, even those not visually rendered (e.g., elements with display: none;).
- Layout Tree: Comprised of LayoutObjects, this tree represents only the elements that will be rendered or could be rendered. It contains geometric information (size, position) and is a more accurate reflection of the user’s visual experience.
The on-device AI’s understanding begins with what is visually present. The core extraction process, therefore, traverses the Layout Tree, ensuring that non-rendered elements and their subtrees are naturally excluded from the primary analysis.
2. Primary Data Structure: Annotated Page Content
The central data structure generated from the page is the Annotated Page Content (APC). This is not a simple text scrape but a hierarchical representation of the page, managed by the content_extraction module.
The primary class responsible for this is AIPageContentAgent, which utilizes a ContentBuilder to walk the Layout Tree. This process generates a tree of ContentNodes, each populated with ContentAttributes that describe the corresponding page element in detail.
Key extracted attributes for each ContentNode include:
- dom_node_id: A stable identifier linking the extracted content back to its original DOM node.
- geometry: Bounding box coordinates, mapping the content to the visual layout of the page.
- TextInfo: The text content, along with styling information such as computedFontSize, fontWeight, and color. This allows the AI to understand the visual prominence of text.
- ImageInfo: Includes the image’s alt text or caption, providing a semantic description.
- FormControlData: For form elements, this structure captures the name, type, current value (passwords are redacted), placeholder text, and state (e.g., is_checked, is_selected).
- InteractionInfo: A critical structure that defines an element’s actionability. It flags whether an element is is_clickable, is_focusable, or is_editable. It also provides a ClickabilityReason enum, specifying why an element is considered interactive (e.g., kClickableControl for a native button, kClickEvents for an element with a JS click handler, or kCursorPointer for a CSS-indicated interactive element).
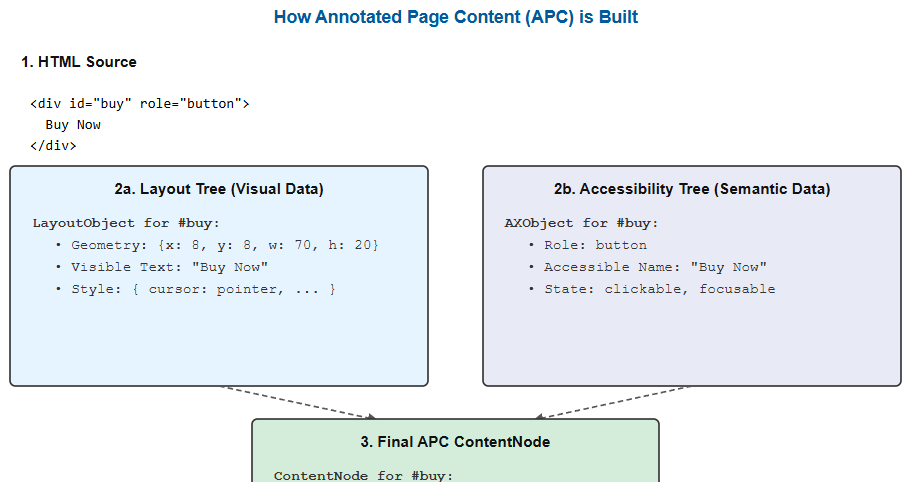
3. Semantic Enrichment via the Accessibility Tree
The APC’s richness and accuracy are significantly enhanced by data from the accessibility/ module. The Content Extraction process is not isolated; it actively queries the Accessibility Tree to infuse its data structure with deeper semantic meaning.
The Accessibility Tree, managed by AXObjectCacheImpl, creates a hierarchy of AXObjects that represent the semantic roles and properties of UI elements. The AIPageContentAgent directly depends on this.
The key points of integration are:
- Role and State Verification: The Accessibility Tree provides the definitive computed role of an element (e.g., ax::mojom::blink::Role::kButton, kLink, kHeading). The APC builder uses this information to correctly classify nodes and determine their properties, such as the ClickabilityReason::kAriaRole.
- Accessible Name Computation: The accessible name of an element, calculated by the accessibility module according to the complex Accessible Name and Description Computation (AccName) specification (which prioritizes aria-labelledby, aria-label, etc.), is used as a primary identifier. This provides the most reliable semantic label for an element, especially for non-textual controls.
- Relationships: ARIA relationships like aria-describedby are resolved by the accessibility module, allowing the APC to understand contextual links between disparate elements on the page.
- Ignored vs. Included State: The accessibility concept of an element being “ignored” (not exposed to assistive tech) but “included” in the tree (for internal calculations) is leveraged. For example, a <label> element that is ignored to prevent redundant screen reader announcements is still included in the tree, allowing its text to be correctly associated as the name for its corresponding input field in the APC.
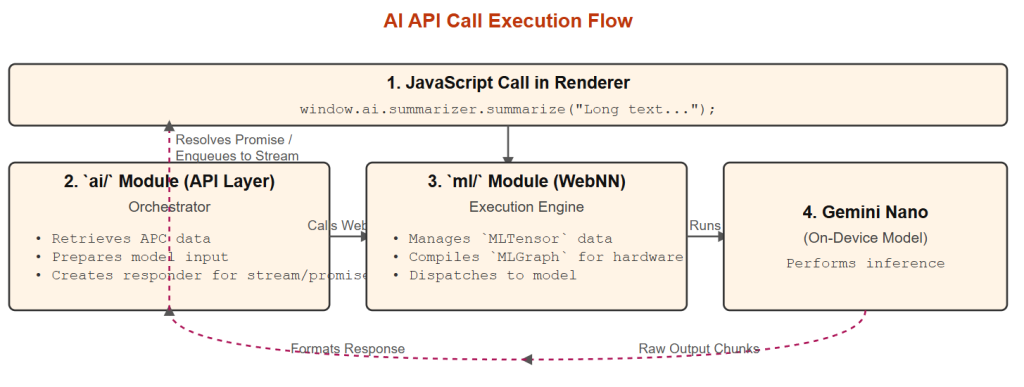
4. The AI Execution Pipeline
Once the semantically enriched APC is available, the AI modules take over.
- AI Application Layer (ai/ module): A user action or a developer’s JavaScript call invokes one of the high-level APIs (LanguageModel, Summarizer, etc.). This module acts as the orchestrator.
- Data Transformation: The relevant parts of the APC (or other inputs) are prepared for the model. For instance, the LanguageModelPromptBuilder converts text, images (SkBitmap), and audio into the MLTensor format required by the underlying ML engine.
- On-Device Inference (ml/ module): The ai/ module interfaces with the ml/ module, which implements the Web Neural Network (WebNN) API. The prepared MLTensor inputs are passed to an MLGraph (the compiled representation of Gemini Nano) and executed via MLContext::dispatch(). This entire process runs locally on the user’s device hardware (CPU/GPU/NPU).
Technical Order of Operations
The process is a data-flow pipeline with dependencies, primarily triggered after the browser’s rendering lifecycle has stabilized.
- Render: The Blink engine parses HTML/CSS to create the DOM Tree and the Layout Tree. This is the prerequisite for all subsequent steps.
- Accessibility Tree Generation: The accessibility/ module traverses the DOM and Layout Trees to build the AXObject tree, computing semantic roles, states, and properties.
- Annotated Page Content Generation: The content_extraction/ module is triggered to build the APC tree. During this process, it traverses the Layout Tree for rendered content and simultaneously queries the Accessibility Tree to enrich the APC nodes with semantic meaning.
- AI Task Invocation: An AI task is initiated through the ai/ module’s JavaScript APIs.
- Model Input Preparation: The ai/ module uses the generated APC (or direct API inputs) to construct MLTensor objects suitable for the ml/ module.
- Inference Execution: The ml/ module’s WebNN implementation takes the MLTensors and executes the on-device Gemini Nano model, returning the result.
This architecture demonstrates a clear design pattern: content is progressively enriched, moving from a raw structural representation (DOM) to a visual one (Layout), then to a deeply semantic one (Accessibility), before being packaged into a comprehensive data structure (APC) for direct use by on-device AI.
Leave a Reply