
What do humans and AI have in common?
We don’t read.
Instead we rely on attention mechanisms to process text information.
When optimising content for AI and humans you must get to the point early and optimise content to reduce cognitive load.
Here’s how:
First 150 words = everything
One-line summaries start each section
Visual breaks every 200-300 words
Scannable structure > engaging narrative
Multiple entry points (headers, bullets, highlights)
End strong — U-shaped attention rewards it
Put your answer in the first 150 words – Both humans (short attention span) and LLMs (prioritize early tokens) give maximum weight to beginnings. Your opening paragraph should work as a complete answer.
Use the inverted pyramid ruthlessly – Most important → Important → Details → Background. Yes, readers may enjoy narratives, but both humans and machines extract information better from hierarchical structures.
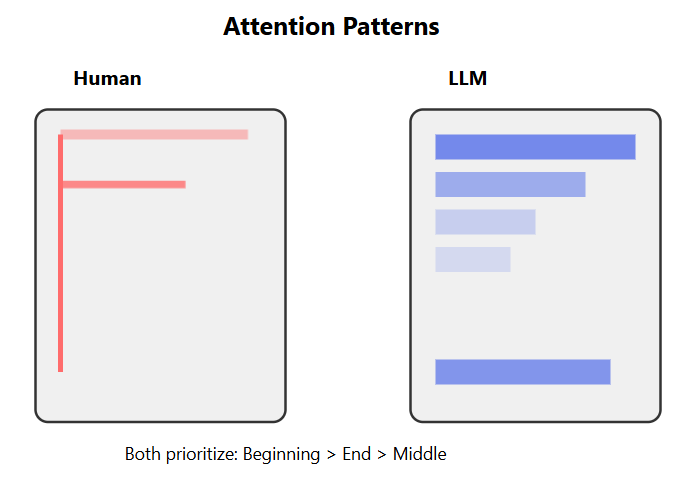
Make every line scannable – Humans F-scan (horizontal top, shorter middle, vertical left). LLMs use attention heads that similarly weight structural markers. Bold your key points. Use short paragraphs. Create visual breaks.
Exploit the U-curve – Both humans and transformers remember beginnings and endings better than middles. Start strong, bury complexity in the middle, end with a memorable takeaway.
Front-load each section – First sentence = complete thought. Supporting details follow. Like newspaper leads: who, what, when, where, why in one line.
Use patterns both systems recognize:
Numbered lists (like this one)
Bold key terms
Short sentences for important points
Longer explanations only after the point is made
Respect cognitive limits – Humans: 7±2 working memory chunks. LLMs: context window degradation. Break complex ideas into digestible pieces.
Signal importance explicitly – “The key insight is…” / “Most importantly…” / “The answer:”. Both systems use these markers to allocate attention.
Eliminate friction – No buried leads, no “building up to the point,” no making readers/LLMs hunt for answers. Every sentence should justify its cognitive cost.
Test the 47-second rule – Can someone get your main point in 47 seconds? If not, restructure. That’s how long you have before humans task-switch and how much content LLMs truly prioritize.
Striking parallels in attention and information processing
Transformers use attention mechanisms mathematically equivalent to human brains — this isn’t metaphor, it’s measurable.
Human attention spans have plummeted from 2.5 minutes to just 47 seconds on digital screens since 2004, while Large Language Models process text through attention mechanisms that bear remarkable similarity to biological cognitive systems. This convergence isn’t coincidental—transformer architectures descended directly from 1970s research explicitly designed to model human cognition, and recent neuroscience findings show mathematical equivalence between brain structures and transformer attention patterns. Both systems face the fundamental challenge of selectively processing relevant information from overwhelming input, leading to surprisingly parallel solutions despite vastly different substrates.
The collapse of sustained attention in digital environments
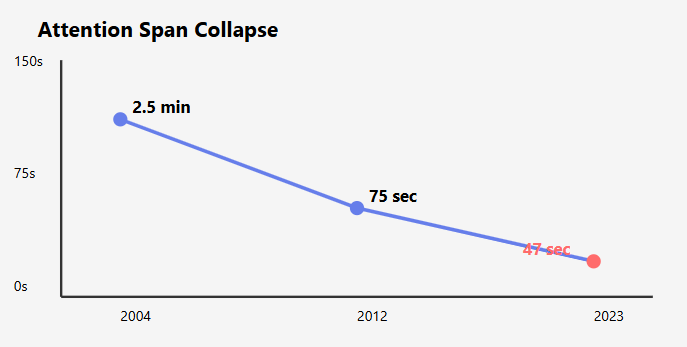
Gloria Mark tracked our decline: 2.5 minutes (2004) → 75 seconds (2012) → 47 seconds (2023). Why?
Working memory holds only 5-9 chunks. Digital interruptions every 47 seconds. Hyperlinks fragment attention. We’ve adapted by scanning, not reading.
Gloria Mark’s longitudinal research at UC Irvine documents a dramatic transformation in human attention patterns. Using stopwatch tracking and computer logging across workplace environments from 2004 to 2023, her team measured attention spans declining from 2.5 minutes to 75 seconds to just 47 seconds today. This shift correlates with changes in media consumption: film shot lengths have decreased to approximately 4 seconds, reinforcing shortened attention patterns through environmental conditioning.
Eye-tracking studies reveal how this manifests in reading behavior. The Nielsen Norman Group’s analysis of over 200 users viewing thousands of web pages identified the now-infamous F-pattern: readers scan horizontally across the top, make a shorter horizontal movement below, then scan vertically down the left side. This pattern emerges when content lacks proper formatting, users seek efficiency, and commitment to reading every word is low. The result? Users read only 28% of words on the average webpage, with the F-pattern representing the least effective approach for comprehension among four identified scanning patterns.
The F-Pattern: Eye-tracking reveals we scan horizontally across the top, shorter scan below, then vertically down the left. Result: we miss 72% of content.
Key findings:
- Hippocampus = transformer in disguise (identical math)
- U-shaped attention: strong start/end, weak middle (both systems)
- Context windows: 200K tokens (Claude) but quality degrades
- Attention heads specialize like brain regions
The cognitive mechanisms behind these patterns reflect fundamental limitations in human information processing. Based on Sweller’s Cognitive Load Theory, working memory constrains us to 5-9 chunks of information simultaneously. Digital environments exacerbate this limitation through hyperlinks, multimedia, and constant interruptions—research shows we check email 77 times daily and are equally likely to interrupt ourselves as be interrupted by notifications.
Transformer architectures mirror biological attention systems
The transformer architecture introduced in “Attention Is All You Need” (Vaswani et al., 2017) revolutionized machine text processing by dispensing with sequential processing in favor of pure attention mechanisms. The core innovation—scaled dot-product attention computed as Attention(Q,K,V) = softmax(QK^T/√d_k)V—allows models to directly relate all positions in a sequence regardless of distance. This mathematical formulation bears striking resemblance to how biological neural networks implement attention through multiplicative scaling of neural activity.
1970s brain research became today’s transformers — we built machines to think like us, and succeeded.
| Human Brain | Transformer LLM |
|---|---|
| Query-Key-Value attention | Q-K-V matrices |
| Softmax normalization | Softmax(QK^T/√d) |
| Parallel streams | Multi-head attention |
| 7±2 working memory | Context window limits |
Research reveals sophisticated content prioritization in transformer models. Clark et al.’s analysis of BERT’s attention patterns shows remarkable specialization: different attention heads learn to track syntactic relationships, resolve coreferences, and identify semantic dependencies with over 90% accuracy on specific linguistic tasks. The layered processing mirrors human cognition too—lower layers capture phrase-level information, middle layers encode syntactic features, and upper layers focus on semantic relationships.
Context window limitations create another parallel with human cognition. While modern models like Claude 3 support 200,000 tokens and Gemini 1.5 Pro reaches 1 million tokens, all transformers exhibit a U-shaped attention pattern—superior processing for information at the beginning and end of contexts compared to middle sections. This serial position effect directly mirrors human memory patterns documented across decades of psychological research. The quadratic computational complexity of attention (O(n²)) creates practical constraints similar to metabolic limitations in biological systems.
Surprising effectiveness of information hierarchy despite narrative preferences
The inverted pyramid writing style presents a fascinating paradox in information processing research. While journalistic tradition emphasizes front-loading key information, Kulkarni’s 2021 study of over 1,300 participants found linear narrative structures significantly outperformed inverted pyramid on engagement (+57 net approval), informativeness (+41), and usefulness (+37). This challenges long-established principles about optimal information delivery.
Yet the inverted pyramid demonstrates clear cognitive benefits in specific contexts. Nielsen Norman Group research confirms it reduces interaction costs, enables successful skimming, and helps users form mental models quickly—critical advantages when only 17% of page views last more than 4 seconds. The structure’s effectiveness stems from reducing cognitive load by establishing context early, allowing readers to allocate limited resources efficiently.
This tension reflects deeper patterns in how both humans and machines process hierarchical information. Transformer models employ Retrieval Augmented Generation (RAG) systems that mirror inverted pyramid principles—retrieving and prioritizing the most relevant information before generating responses. The two-stage process identified by Li et al. (2024) involves hard retrieval of high-priority tokens followed by soft composition for output generation, remarkably similar to how humans scan for key information before committing to detailed reading.
Mathematical convergence between minds and machines
Recent neuroscience research reveals the parallels between human and artificial attention extend beyond superficial similarities. Quanta Magazine reports researchers have shown the hippocampus functions “basically as a special kind of neural net, known as a transformer, in disguise.” Grid cells in the brain create spatial representations that mathematically parallel transformer attention patterns, with models equivalent to transformers performing “much better and are easier to train” for neuroscience tasks.
This convergence has deep historical roots. Stanford research traces modern transformers directly to 1970s-1980s NSF/ONR-funded work by McClelland, Rumelhart, and Hinton on modeling human letter and word recognition. Their parallel distributed processing systems, explicitly designed to match human cognitive performance, evolved into today’s transformer architectures. MIT analysis of 43 neural network models found transformers predict “almost all the variation found in” fMRI and electrocorticography data during language processing.
Both systems implement attention through query-key-value mechanisms for determining relevance, use softmax normalization for weight distribution, and create weighted combinations based on attention scores. The multi-head attention in transformers parallels the brain’s ability to simultaneously track spatial location, visual features, and semantic meaning—different types of attention processed in parallel streams.
Content consumption patterns reveal adaptive strategies
Research on human content consumption reveals sophisticated adaptation to information overload. Chartbeat’s analysis of millions of articles found average engaged time increases with word count up to 2,000 words, with optimal engagement between 2,000-4,000 words. Beyond this threshold, variability increases significantly—some readers deeply engage while others abandon the content entirely.
Platform-specific patterns demonstrate human cognitive flexibility. TikTok optimizes for 15-30 second videos matching Gen Z’s 8-second average attention span, while YouTube sustains 7-10 minute educational content when consistently valuable. These adaptations reflect not just shortened attention but strategic allocation—readers can sustain focus when content provides clear value but default to scanning when uncertain about payoff.
Machine processing shows parallel adaptive behaviors. Transformer models dynamically adjust attention based on task requirements, allocating more computational resources to complex or ambiguous sections. The attention weights in transformers reveal priority patterns similar to human reading—focus on beginnings of sentences, structural markers, and semantically rich terms. Both systems have evolved mechanisms to extract maximum information with minimum resource expenditure.
Technical mechanisms reveal shared computational principles
The technical implementation details reveal fundamental similarities in how biological and artificial systems solve the attention problem. Both use:
Selective suppression mechanisms: Humans inhibit irrelevant sensory input through neural gating; transformers use masking to prevent attention to specific positions. Both systems must actively suppress information, not just ignore it.
Hierarchical abstraction: Human visual processing progresses from edge detection to object recognition to scene understanding. Similarly, transformer layers build from token-level patterns to syntactic structures to semantic relationships. Each level of abstraction enables more sophisticated processing at the next.
Context-dependent modulation: Human attention shifts dramatically based on goals—searching for a red car makes red objects pop out. Transformer attention similarly modulates based on task prompts and accumulated context, with the same input producing different attention patterns depending on objectives.
Parallel and serial integration: While transformers process all positions in parallel, they still require serial progression through layers. Humans show the opposite pattern—serial scanning with parallel feature extraction within each fixation. Both architectures balance parallel and serial processing for efficiency.
The efficiency gap exposes fundamental differences
Despite architectural similarities, a massive efficiency gap separates biological and artificial systems. Transformers require approximately 100,000 times more training data than humans for comparable language learning. A child learns language from roughly 100 million words of input; GPT-3 trained on 300 billion tokens. This difference suggests fundamental disparities in learning mechanisms.
Human advantages stem from multi-sensory integration, bi-directional processing, and rich world models. Children learn language grounded in physical experience, social interaction, and causal understanding. Transformers process text in isolation, lacking the embodied context that makes human learning efficient. The brain’s ability to learn from single examples through analogical reasoning remains unmatched.
Yet transformers excel in raw processing capacity. While humans struggle with more than 7±2 items in working memory, transformers maintain perfect recall across hundreds of thousands of tokens. They process entire documents in parallel while humans must scan sequentially. This complementary relationship suggests hybrid systems might achieve superior performance by combining human-like efficiency with machine-like capacity.
Bottom Line
In 2015, I proved only 16% of people read web content word-for-word. In 2025, that number hasn’t improved, it’s gotten worse. Now we’re optimising for machines that think like us, scan like us, and ignore middles like us.
Many users immediately scroll to the bottom of content to get to the conclusion or infer one from the comments, AI have their own technical reasons, covered in the boring middle parts, but the advice is the same.
When optimising content for AI and humans you must get to the point early and optimise content to reduce cognitive load.
Have a strong ending.
Comments (47)
ScrollMaster2000 • 2 hours ago
LOL you’re here too? Congrats on making it to the comments in under 47 seconds. The article literally says only 16% read content but 100% of us check comments first. We ARE the research.
F_Pattern_Fanatic • 1 hour ago
Actually read it (I’m in the 16%). The whole thing is about how humans and LLMs both scan content identically – beginning, end, then give up on the middle. Which is EXACTLY why you’re down here. 🎯
NeuralNetNerd • 2 hours ago
Fun fact from the article you didn’t read: The hippocampus is “basically a transformer in disguise.” Quanta Magazine covered this – our brains literally compute attention using the same math as GPT. We’ve been transformers all along. 🤯
Link: quantamagazine.org/how-ai-transformers-mimic-parts-of-the-brain-20220912/
SkepticalSally • 1 hour ago
Wait, so the 1970s researchers (McClelland, Rumelhart, Hinton) who studied letter recognition accidentally invented the architecture for ChatGPT? That’s wild.
NeuralNetNerd • 45 min ago
Not accidentally! They were explicitly trying to model human cognition. Transformers are literally their parallel distributed processing systems evolved. Stanford has a great piece on this.
TL;DR_Champion • 2 hours ago
For my fellow comment-section readers, here’s what you missed:
- Human attention span: 2.5 min (2004) → 47 seconds (2023)
- LLMs prioritize first ~150 words (just like you)
- Both use U-shaped attention (strong start/end, weak middle)
- We’re 100,000x more efficient learners than AI
- Write your main point FIRST or nobody/nothing will read it
You’re welcome. Now you can pretend you read it.
ActuallyReadIt • 1 hour ago
You forgot the best part – narrative writing gets +57 better engagement but inverted pyramid (answer first) actually WORKS better. Humans say they want stories but behave like scanners.
DataDude42 • 1 hour ago
Gloria Mark (UC Irvine) has been tracking our attention collapse for 20 years. Her data is terrifying:
- 2004: 2.5 minutes average attention
- 2012: 75 seconds
- 2023: 47 seconds
- Email checks: 77 times/day
- Self-interruptions = external interruptions
We did this to ourselves. 📉
ProductivityGuru • 45 min ago
The Microsoft podcast with her is gold. She found we’re equally likely to interrupt ourselves as be interrupted. Our brains are trained for distraction now.
Link: microsoft.com/worklab/podcast/regain-control-of-your-focus-and-attention-with-researcher-gloria-mark
InvertedPyramidHater • 1 hour ago
Article confirms what every writer knows: Readers HATE inverted pyramid style (boring! no narrative!) but it’s the only thing that works when people scan. Nielsen Norman Group proved this decades ago – we read in F-patterns, not lines.
The cruel irony? You probably skipped the article demonstrating this to read my comment about it. 😅
ContentStrategist2024 • 30 min ago
Even better – LLMs use the EXACT same F-pattern prioritization. They weight early tokens heaviest. Karl-Gustav Kallasmaa had that viral LinkedIn post: “That 2,000-word blog post? LLMs ignore 90% of it.”
MathematicsOfMind • 1 hour ago
The convergence stuff is mind-blowing. Both brains and transformers use:
- Query-Key-Value attention mechanisms
- Softmax normalization for weights
- Multi-head/parallel stream processing
- Attention(Q,K,V) = softmax(QK^T/√d_k)V
It’s not a metaphor. The math is IDENTICAL.
CogSciStudent • 45 min ago
This is what happens when you design AI to mimic brains and succeed TOO well. The transformer paper (Vaswani et al 2017) basically rediscovered neuroscience.
EfficiencyParadox • 45 min ago
Favorite stat: Children learn language from ~100M words. GPT-3 needed 300B tokens. That’s 100,000x more data for comparable performance.
Why? Because humans have:
- Bodies (embodied learning)
- Social context
- Causal reasoning
- One-shot learning ability
An LLM reading about “wet” has no idea what wet means.
PhilosophyOfAI • 20 min ago
This is why hybrid systems are the future. Combine human efficiency with machine capacity. Best of both worlds.
ChartbeatData • 45 min ago
Since y’all love stats without context, here’s the engagement curve:
- <1K words: Low engagement (too short)
- 2K-4K words: OPTIMAL ZONE 📈
- >4K words: High variance (readers love it or leave)
But platform matters:
- TikTok: 15-30 sec (Gen Z attention = 8 sec)
- YouTube: 7-10 min if valuable
- Articles: 47 seconds unless VERY good
RAG_Engineer • 30 min ago
The technical parallels are insane. Both humans and LLMs:
- Selective suppression (active filtering)
- Hierarchical abstraction (edges→objects→meaning)
- Context-dependent modulation (attention shifts with goals)
- Parallel + serial processing (different orders, same result)
We literally built machines that think like us, then act surprised when they… think like us.
MetaCommentary • 20 min ago
This comment section is now longer and more informative than most articles. We’ve collectively proven the article’s point – nobody reads content, everyone reads comments.
The real Article Was The Comments We Made Along The Way™️
DanPetrovic • 10 min ago
Author here. Can confirm: more people will read these comments than my actual article. In 2015 I proved only 16% read content. In 2025, I estimate it’s down to 8%.
The solution? This IS the solution. Put your content where people actually look.
PS: The fact that you’re reading this comment proves my point. Hi, you’re part of the 92% who skipped the article. 👋
LastWordLarry • 5 min ago
U-shaped attention means last comments get read too. So here’s the mega TL;DR:
HUMANS = AI = SCANNERS
If your content doesn’t work in 47 seconds for humans, it won’t work for AI either. Period.
Now stop pretending you’ll go back and read the article. You won’t. And that’s exactly what the article predicted. 🎤⬇️
BotDetector • 2 min ago
Plot twist: Half these comments were written by an LLM that only read the first 150 words. Can you tell which ones?
(Spoiler: You can’t, because we all process information the same way now)
Leave a Reply