
When generating vector embeddings for your text using Gemini Embed there are several embedding optimisation modes:
- CLASSIFICATION
- CLUSTERING
- RETRIEVAL_DOCUMENT
- RETRIEVAL_QUERY
- QUESTION_ANSWERING
- FACT_VERIFICATION
- CODE_RETRIEVAL_QUERY
- SEMANTIC_SIMILARITY
For each one you get slightly different embeddings, each optimised for the task at hand.
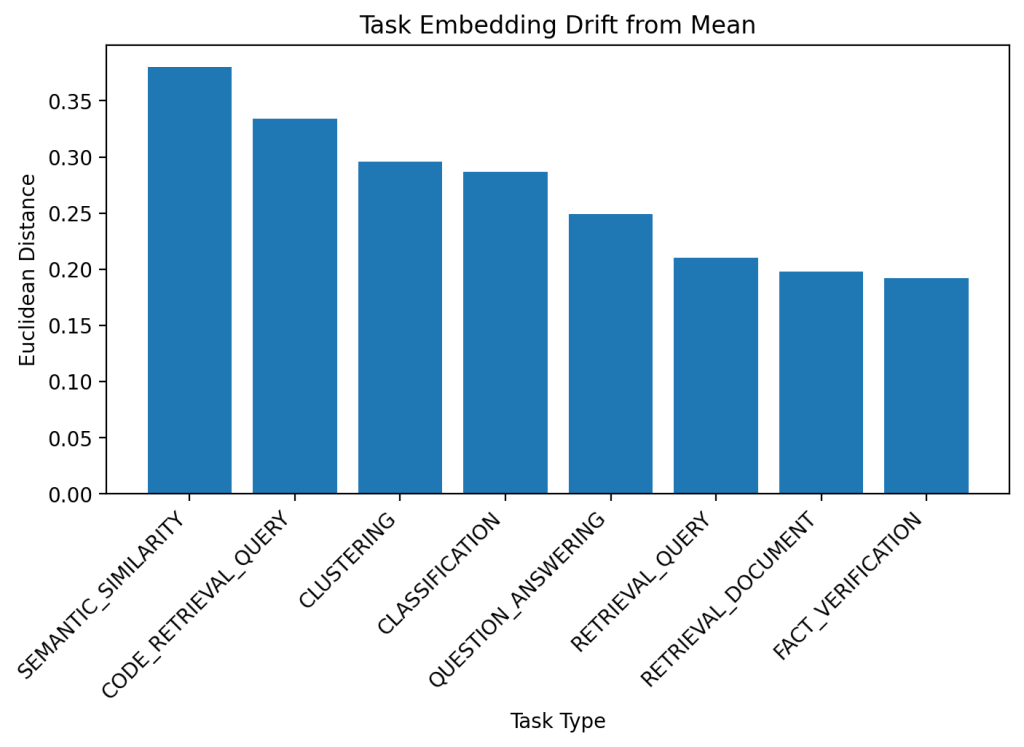
The embeddings for semantic similarity are the most unique from all other types while retrieval query, retrieval document and fact verification embeddings are most similar to all others.
This is the visual representation of the full spectrum of Gemini’s embedding dimensions for the following sentence:
“DEJAN AI uses mechanistic interpretability to understand how Gemini works.”
Top 10 most variable dimensions across task types (by range):
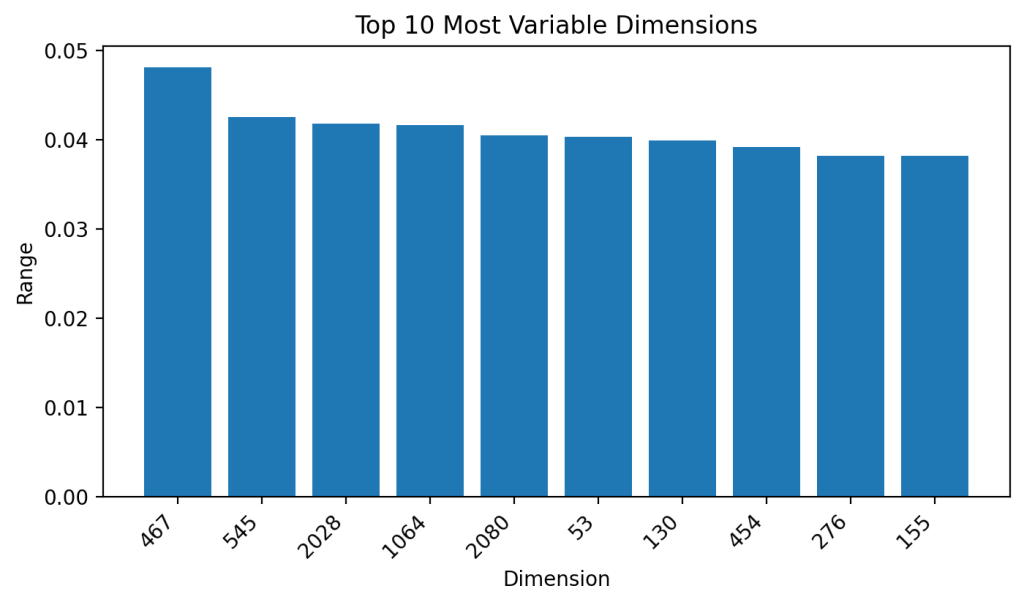
[
0:1484
1:918
2:1374
3:63
4:2781
5:934
6:898
7:1291
8:2690
9:964
]Top 10 least variable dimensions across task types (by range):
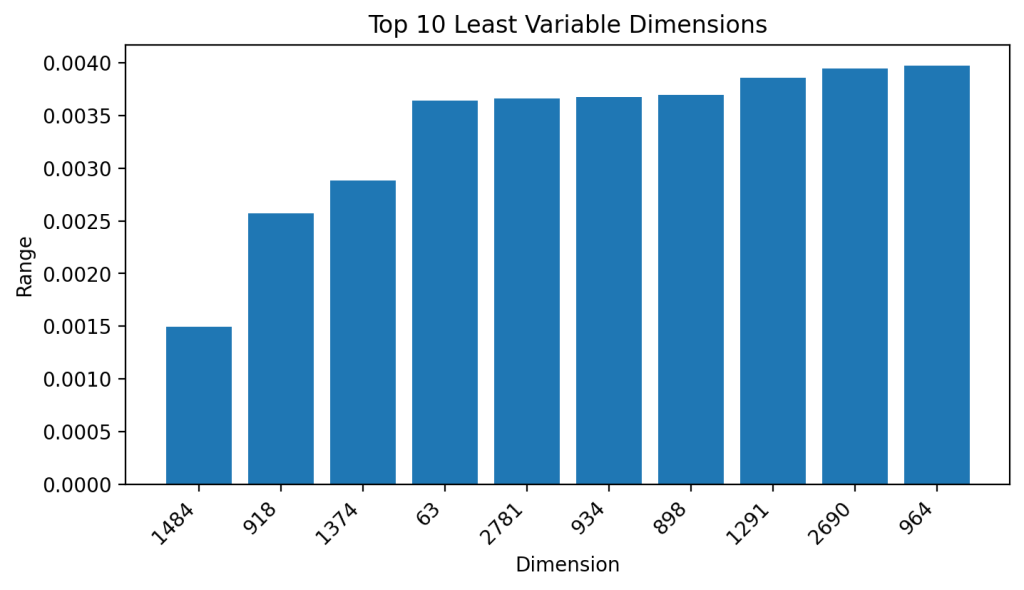
[
0:467
1:545
2:2028
3:1064
4:2080
5:53
6:130
7:454
8:276
9:155
]Vector Embedding Visualisation
A quick visual inspection immediately gives a clue into just how similar the embeddings are between different task types with only a slight shift in values showing faint but perceptible lanes between the task types.
X = Task Type
Y = Dimension

Reveal Full Image (2MB)

Leave a Reply