
Category: Machine Learning
-

Chrome’s New Embedding Model: Smaller, Faster, Same Quality
TL;DR Discovery and Extraction During routine analysis of Chrome’s binary components, I discovered a new version of the embedding model in the browser’s optimization guide directory. This model is used for history clustering and semantic search. Model directory: Technical Analysis Methodology To analyze the models, I developed a multi-faceted testing approach: Key Findings 1. Architecture…
-

AI Content Detection
As models advance, AI content detection tools are struggling to keep up. Text generated by the latest Gemini, GPT and Claude models is fooling even the best of them. We’ve decided to bring AI content detection back in-house in order to keep up. Each time a new model comes out the classifier needs a fine-tune…
-
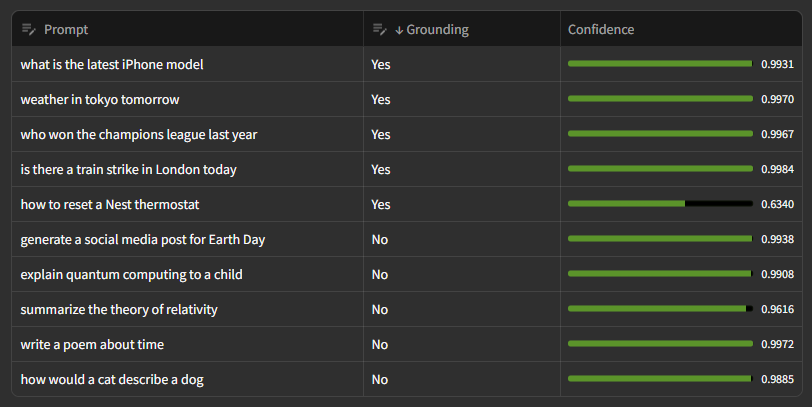
Introducing Grounding Classifier
Using the same tech behind AI Rank, we prompted Google’s latest Gemini 2.5 Pro model with search grounding enabled in the API request. A total of 10,000 prompts were collected and analysed to determine the grounding status of the prompt. The resulting data was then used to train a replica of Google’s internal classifier which…
-

Advanced Interpretability Techniques for Tracing LLM Activations
Activation Logging and Internal State Monitoring One foundational approach is activation logging, which involves recording the internal activations (neuron outputs, attention patterns, etc.) of a model during its forward pass. By inspecting these activations, researchers can identify which parts of the network are highly active or contributing to a given output. Many open-source transformer models…
-

Temperature Parameter for Controlling AI Randomness
The Temperature parameter is a crucial setting used in generative AI models, such as large language models (LLMs), to influence the randomness and perceived creativity of the generated output. It directly affects the probability distribution of potential next words. Understanding the Basics What the Temperature Value Does In Practical Terms Using the sentence “The cat sat on…
-

Probability Threshold for Top-p (Nucleus) Sampling
The “Probability Threshold for Top-p (Nucleus) Sampling” is a parameter used in generative AI models, like large language models (LLMs), to control the randomness and creativity of the output text. Here’s a breakdown of what it does: Understanding the Basics What the Threshold Value Does In Practical Terms Imagine you’re asking the model to complete…
-

Cross-Model Circuit Analysis: Gemini vs. Gemma Comparison Framework
1. Introduction Understanding the similarities and differences in how different large language models represent and prioritize brand information can provide crucial insights for developing robust, transferable brand positioning strategies. This framework outlines a systematic approach for comparative circuit analysis between Google’s Gemini and Gemma model families, with the goal of identifying universal brand-relevant circuits and…
-

Neural Circuit Analysis Framework for Brand Mention Optimization
Leveraging Open-Weight Models for Mechanistic Brand Positioning 1. Introduction While our previous methodology treated language models as black boxes, open-weight models like Gemma 3 Instruct provide unprecedented opportunities for direct observation and manipulation of internal model mechanics. This framework extends our previous methodology by incorporating direct neural circuit analysis, allowing for precise identification and targeting…
-

Strategic Brand Positioning in LLMs: A Methodological Framework for Prompt Engineering and Model Behavior Analysis
Abstract This paper presents a novel methodological framework for systematically analyzing and optimizing the conditions under which large language models (LLMs) generate favorable brand mentions. By employing a structured probing technique that examines prompt variations, completion thresholds, and linguistic pivot points, this research establishes a replicable process for identifying high-confidence prompting patterns. The methodology enables…
-

AlexNet: The Deep Learning Breakthrough That Reshaped Google’s AI Strategy
When Google, in collaboration with the Computer History Museum, open-sourced the original AlexNet source code, it marked a significant moment in the history of artificial intelligence. AlexNet was more than just an academic breakthrough; it was the tipping point that launched deep learning into mainstream AI research and reshaped the future of companies like Google.…