An analysis of how Google, OpenAI, and Anthropic handle web grounding, comparing their search processes, citation rates, and how they process page content.
When you ask a modern AI model a question that needs fresh facts, it doesn’t answer from memory. It runs its own web search, reads what comes back, and weaves some of those pages into its answer. That process is called grounding. But “it searches the web” hides a lot. Each platform receives a different number of pages, keeps a different fraction of them, hands back a different kind of evidence, and cites at a wildly different rate. To show this concretely, we ran the exact same query — “best ai seo agency 2026” — through all three, on the same day, with no location set, and inspected the raw grounding data each one returned.
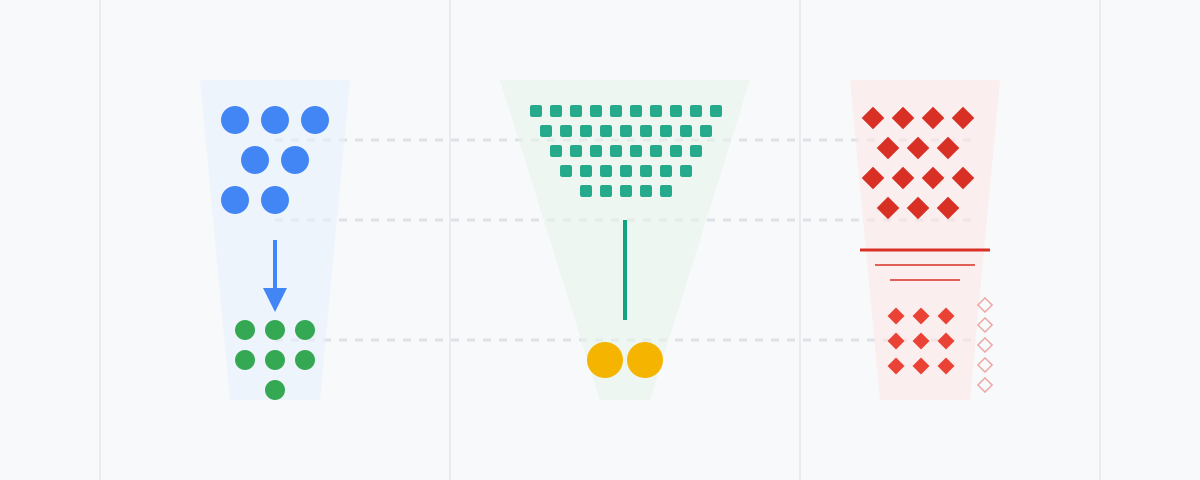
Three answers to one question, three completely different shapes underneath.
Every platform runs the same basic pipeline, just with different valves:
search query → pages RECEIVED → pages with READABLE content → pages CITED in the answer
The gap between received and cited is where each platform reveals its personality. Google cites almost everything it receives; OpenAI receives a flood and cites a trickle; Anthropic sits in between. Let’s walk through each.
| Platform | Model | Time | Tokens in / out | Pages received | Pages cited |
|---|---|---|---|---|---|
| gemini-3.5-flash | 53 s | 205 / 15,321 | 7 | 7 | |
| OpenAI | gpt-5.5 | 14 s | 10,853 / 782 | 39 | 2 |
| Anthropic | claude-opus-4-8 | 138 s | 83,708 / 12,754 | 14 | 9 |
Google’s model is the most economical. It sent only 205 input tokens — basically just the question — then did the heavy lifting server-side and streamed back a long, fully-written answer (15,321 output tokens).
It rewrote the question into two searches before answering:
top ai seo agencies 2026best ai seo agency 2026The funnel barely narrows: 7 received, 7 cited. This is the defining trait of Google’s grounding — it doesn’t expose pages it didn’t use. Every source you see is a grounding chunk that genuinely supported a sentence. Behind those 7 sources sit 24 support segments: individual answer sentences mapped back to the page that justifies them. For example, this sentence —
“In 2026, the landscape of search engine optimization has shifted dramatically
from traditional ‘blue links’ to Generative Engine Optimization (GEO) and
Answer Engine Optimization (AEO)”
— is backed by both europeanbusinessreview.com and thriveagency.com.
The URL catch: everything arrives wrapped in a redirect. Google never hands you the real link directly. Each source comes as a vertexaisearch.cloud.google.com/grounding/... redirect that has to be resolved to recover the true destination:
| What Google sends | What it resolves to | Cites |
|---|---|---|
vertexaisearch.cloud.google.com/grounding/... | https://thriveagency.com/news/best-ai-seo… | 6 |
vertexaisearch.cloud.google.com/grounding/... | https://dejanmarketing.com/best-ai-seo… | 6 |
vertexaisearch.cloud.google.com/grounding/... | https://wellows.com/blog/top-ai-seo… | 5 |
It also gives you the retrieved page content per source — e.g. a Catalyst review snippet stamped (2026-06-09).
Google’s philosophy: tight, citation-first, nothing wasted — but the real URLs are hidden behind redirects you must unwrap.
OpenAI was the fastest by far (14 seconds) and ran with reasoning effort set to none (just 60 reasoning tokens), yet it cast the widest net.
It fanned the question into three searches:
best AI SEO agencies 2026 AI search optimization agencytop AI SEO agency generative engine optimization 2026best GEO agency AI search optimization 2026The funnel is dramatic: 39 received → 37 with readable content → 2 cited.
That’s roughly a 20:1 drop. OpenAI is happy to show you 37 pages of evidence but footnotes only the two it leaned on.
The snippets are a sliding window. This is OpenAI’s most distinctive feature.
Every page comes back as a short extractive window, explicitly tagged with a word limit. In this run:
Each window is a ...-joined collage of the most relevant passages plus freshness metadata. Here is the actual snippet OpenAI kept for the page it ended up citing, marketingltb.com (search-class, 200-word window, published “2 weeks ago”):
… In 2026, Directive has extended this approach into AI search optimization,
building content architectures designed to appear in Google AI Overviews,
ChatGPT recommendations, and Perplexity answers …
… iPullRank, a New York-based enterprise SEO and content strategy agency
founded by Mike King … is one of the most technically distinctive AI SEO
agencies in the market.
The two it actually cited, and the claim each one supports:
| Cited page | Class | Window | Claim it grounds |
|---|---|---|---|
| marketingltb.com | search | 200 w | “Several recent 2026 lists rank agencies like Directive, iPullRank, Searchbloom…” |
| techradar.com (Ahrefs) | news | 100 w | “Recent SEO platforms are also adding AI visibility tracking across ChatGPT, Perplexity, Google AI Overviews…” |
URLs are clean and direct — no redirect wrapper like Google — though cited links carry a ?utm_source=openai tracking tag.
OpenAI’s philosophy: retrieve aggressively, expose readable windows for everything, but cite conservatively. Great for seeing the evidence pool, weak if you equate “cited” with “considered.”
Claude took the longest (138 seconds) and consumed by far the most input tokens (83,708) — because it grounds in two passes. First it narrates and searches (“I’ll search for current information on the top AI SEO agencies in 2026.”), then it feeds the retrieved material back through itself to write the final answer.
The funnel: 14 received → 9 cited, 5 unselected. Unlike Google, Claude does keep pages it ultimately didn’t cite (the 5 “unselected” ones), so you can see what it considered and passed over — e.g. it received frase.io, revvgrowth.com and stridec.com but cited none of them.
The catch: the snippet content is encrypted. Each received page carries a sealed blob — between roughly 3,200 and 4,800 bytes — that you cannot read directly. It’s opaque by design.
You recover it as “boundary lines.” By passing the encrypted material back in a second turn, the snippet can be reconstructed as a list of passages, long ones collapsed to a start […] end form. One page alone yielded 44 of these lines; across the 14 sources they range from 19 to 44 each. A sample from spicymargarita.co:
And Claude records the exact verbatim span it quoted into the answer (its cited_text), e.g.:
“Good AI SEO is also good SEO. There is no separation. Thrive integrates
AI-powered SEO into every campaign…”
Anthropic’s philosophy: deep, two-pass reading with a generous citation rate and full visibility into considered-but-rejected sources — but the raw snippets are sealed and only recoverable indirectly, which is why it’s the slowest and most token-hungry of the three.
| Dimension | Google (Gemini) | OpenAI (gpt-5.5) | Anthropic (Claude) |
|---|---|---|---|
| Speed | 53 s | 14 s (fastest) | 138 s (slowest) |
| Search queries fired | 2 | 3 | (narrated, single pass + read) |
| Pages received → cited | 7 → 7 (~1:1) | 39 → 2 (~20:1) | 14 → 9 (~3:2) |
| Shows uncited pages? | No | Yes (37 readable) | Yes (5 unselected) |
| Snippet form | Retrieved page content | Sliding window (100/200 wds) | Encrypted blob |
| Read the snippet directly? | Yes | Yes | No — recover as boundary lines |
| URLs | Redirect-wrapped | Direct (+utm tag) | Direct |
| Input tokens | 205 (lightest) | 10,853 | 83,708 (heaviest) |
Same question. Same day. Three very different machines deciding what counts as evidence.
 Dan Petrovic ·
Jun 13, 16:31
Dan Petrovic ·
Jun 13, 16:31
AI overview is technically an abstractive summarization itself though it’s impossible to tell what feeds them unless Google documents it somewhere. We could ask.
Dan Petrovic ·
SuggestsExpands · ·
Jun 14, 10:22
Great insights!
QQ: did you adjust the thinking effort on Claude?
Using low I got my answers a lot faster but didn’t time it
Great analysis as usual. Any idea how different /similar the citation process is for AIOs? It feels like there’s a very different flow there, with grounding for citations being potentially independent of grounding for generative response? Any thoughts?