
Note: Highlighted bits of this article indicate the parts used to ground Gemini with article title as prompt.
Our prior analysis showed that Google doesn’t use your full page content when grounding its Gemini-powered AI systems. Now we have substantially more data to share, specifically around how much content gets selected and what determines that selection.
Dataset Overview
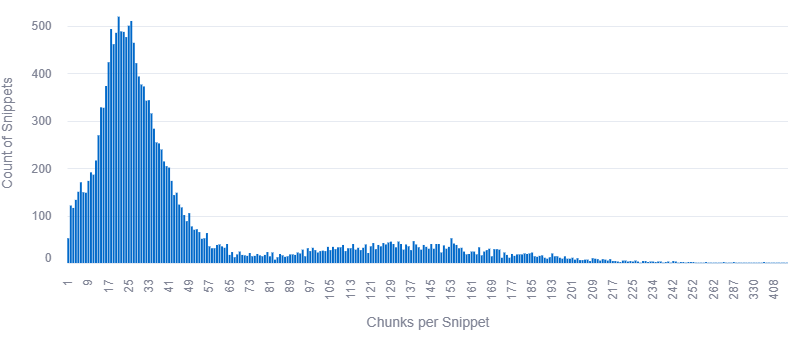
We analysed 7,060 queries with 3+ sources, comparing grounding snippets against full page content for 2,275 tokenized pages.
| Metric | Value |
|---|---|
| Queries Analysed | 7,060 |
| Pages Tokenized | 2,275 |
| Total Snippets | 883,262 |
| Avg Words / Chunk | 15.5 |
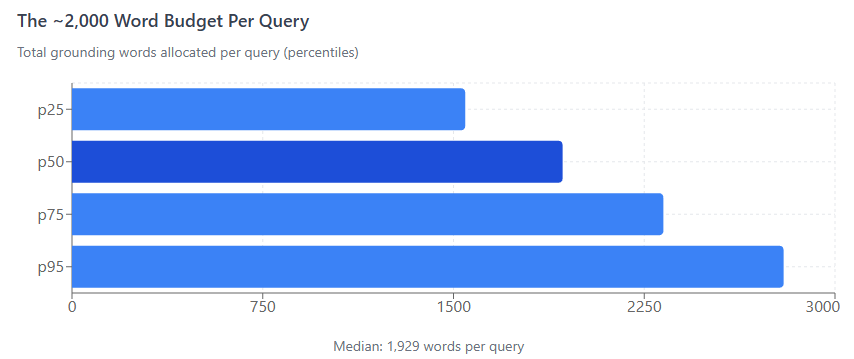
The ~2,000 Word Budget
Each query has a fixed grounding budget of approximately 2,000 words total, distributed across sources by relevance rank.
| Percentile | Total Words Per Query |
|---|---|
| p25 | 1,546 |
| p50 (median) | 1,929 |
| p75 | 2,325 |
| p95 | 2,798 |
This budget is remarkably consistent regardless of how many sources are used or how long the individual pages are.
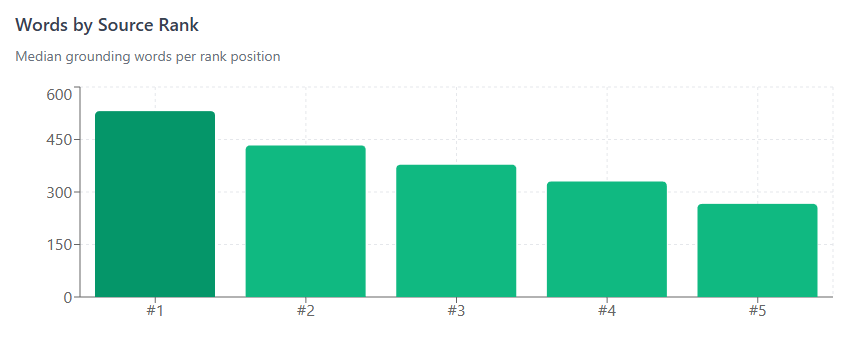
Rank Determines Your Share
The total budget is divided among sources based on their relevance ranking:
| Rank | Median Words | Share of Total |
|---|---|---|
| #1 | 531 | 28% |
| #2 | 433 | 23% |
| #3 | 378 | 20% |
| #4 | 330 | 17% |
| #5 | 266 | 13% |
Being the #1 ranked source gets you 2x the grounding compared to being #5. You’re competing for share of a fixed pie, not expanding the pie.
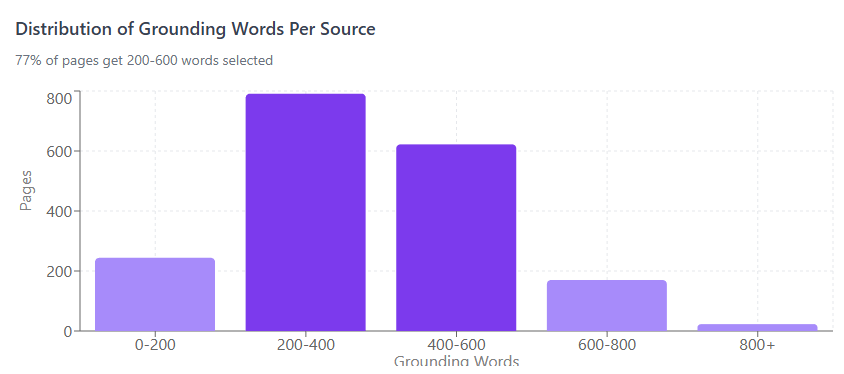
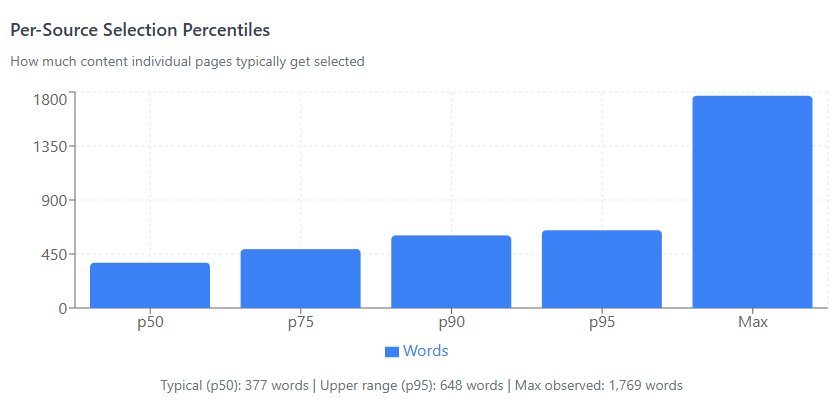
Per-Source Selection
For individual sources, the grounding selection follows this distribution:
| Percentile | Words | Characters |
|---|---|---|
| p50 (median) | 377 | 2,427 |
| p75 | 491 | 3,182 |
| p90 | 605 | 3,863 |
| p95 | 648 | 4,202 |
| Max | 1,769 | 11,541 |
77% of pages get 200-600 words selected. The typical page gets ~377 words.
Coverage Drops as Page Size Increases
We compared grounding selection against original page size:
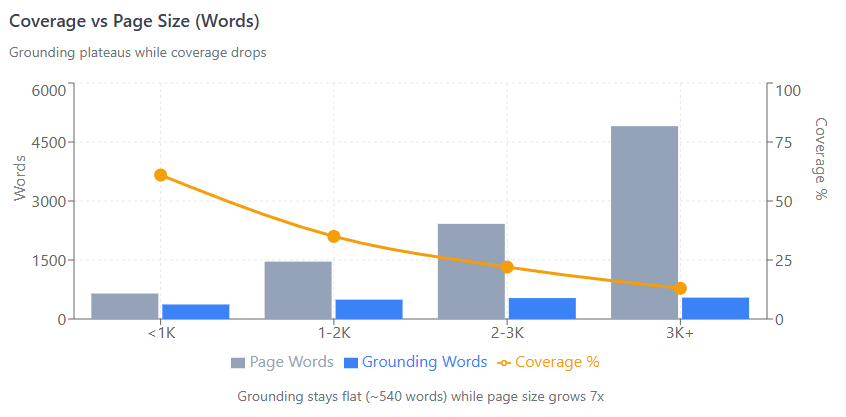
| Page Words | Avg Grounding Words | Coverage |
|---|---|---|
| <1K | 370 | 61% |
| 1-2K | 492 | 35% |
| 2-3K | 532 | 22% |
| 3K+ | 544 | 13% |
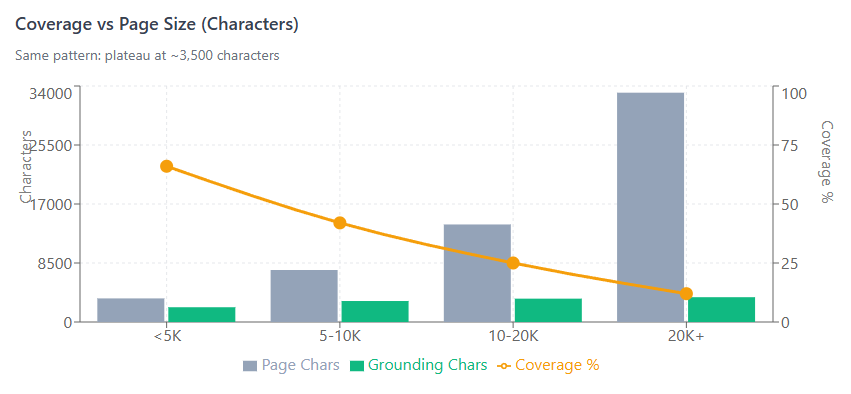
| Page Chars | Avg Grounding Chars | Coverage |
|---|---|---|
| <5K | 2,127 | 66% |
| 5-10K | 3,024 | 42% |
| 10-20K | 3,363 | 25% |
| 20K+ | 3,574 | 12% |
Grounding plateaus at ~540 words / ~3,500 characters. Pages over 2,000 words see diminishing returns—adding more content dilutes your coverage percentage without increasing what gets selected.
Key Takeaways
- Fixed budget per query: ~2,000 words total, split among sources
- Rank matters most: #1 source gets 531 words, #5 gets 266 words
- Diminishing returns: Pages over 1,500 words don’t get more selected
- Concise wins: A tight 800-word page gets 50%+ coverage; a 4,000-word page gets 13%
The implication for content strategy is clear: density beats length. Focus on being the most relevant source for a query, not the longest.
Leave a Reply to Ben Foster Cancel reply