Analysis of how Google selects content to ground Gemini-powered AI shows a fixed 2,000-word budget per query, where relevance rank determines word share.
When Google uses your website to ground its Gemini AI, it doesn't actually read your entire page. Instead, it operates on a strict budget. For any given query, Google allocates a total budget of about two thousand words, and it splits this fixed amount among all the sources it pulls from.
Your search rank determines how much of that budget you get. The top-ranked source gets the lion's share, usually around five hundred words. By the time you get down to the fifth spot, that share is cut in half.
This also means writing longer articles won't help you get more coverage. In fact, after about fifteen hundred words, you hit a wall of diminishing returns. Google simply stops selecting more content. A tight, eight-hundred-word article might see more than half of its text used. But a massive four-thousand-word page will only see about thirteen percent of its content make the cut.
The takeaway for content strategy is clear. Density beats length. Don't try to write the longest page on the web. Instead, focus on being the most relevant, concise source for the query.

Our prior analysis showed that Google doesn’t use your full page content when grounding its Gemini-powered AI systems. Now we have substantially more data to share, specifically around how much content gets selected and what determines that selection.
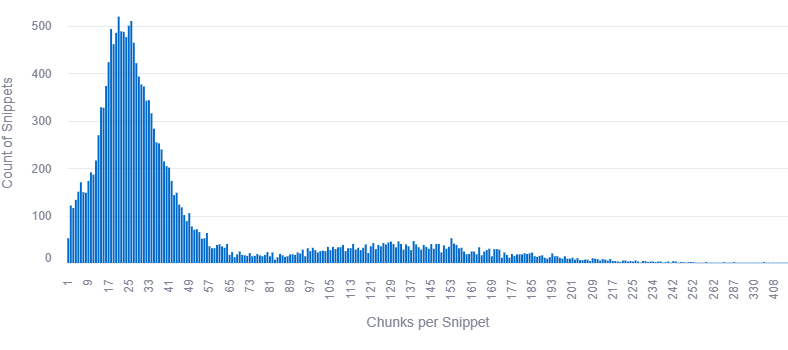
We analysed 7,060 queries with 3+ sources, comparing grounding snippets against full page content for 2,275 tokenized pages.
MetricValueQueries Analysed7,060Pages Tokenized2,275Total Snippets883,262Avg Words / Chunk15.5Each query has a fixed grounding budget of approximately 2,000 words total, distributed across sources by relevance rank.
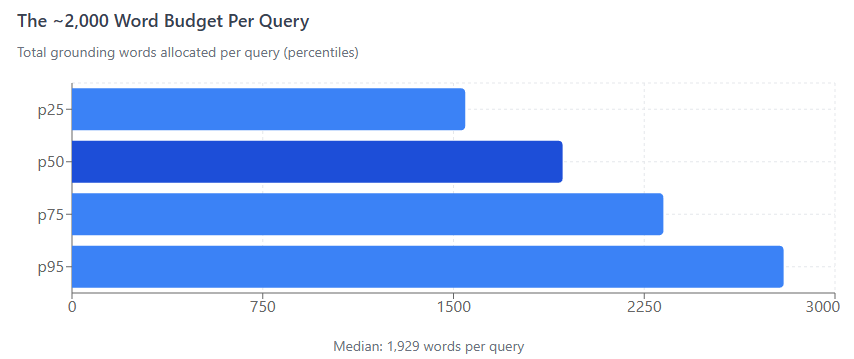
This budget is remarkably consistent regardless of how many sources are used or how long the individual pages are.
The total budget is divided among sources based on their relevance ranking:
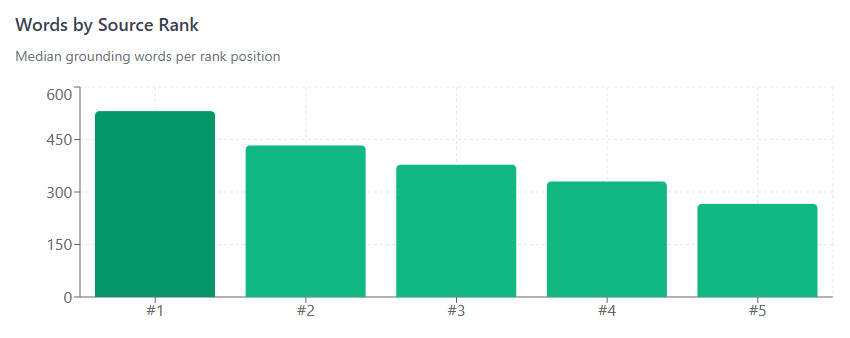
Being the #1 ranked source gets you 2x the grounding compared to being #5. You’re competing for share of a fixed pie, not expanding the pie.
For individual sources, the grounding selection follows this distribution:
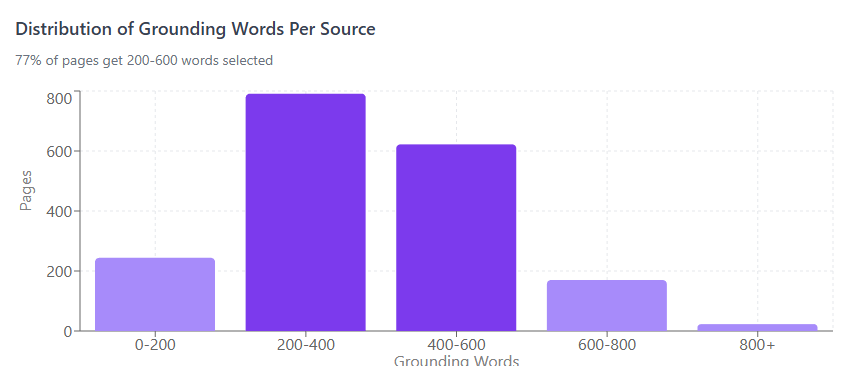
77% of pages get 200-600 words selected. The typical page gets ~377 words.
We compared grounding selection against original page size:
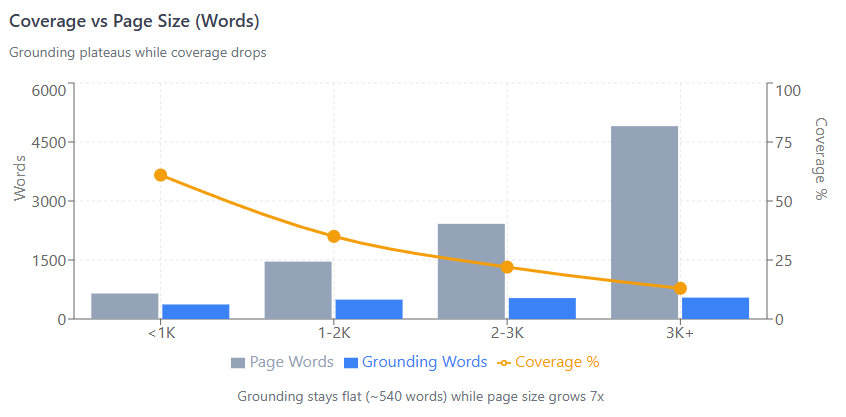
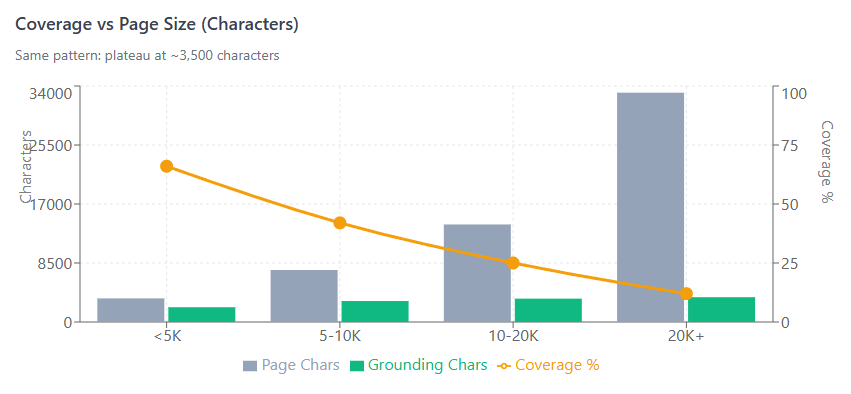
Grounding plateaus at ~540 words / ~3,500 characters. Pages over 2,000 words see diminishing returns—adding more content dilutes your coverage percentage without increasing what gets selected.
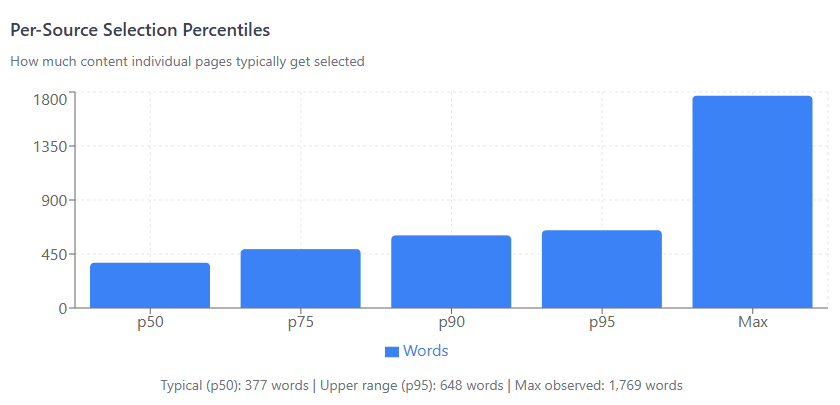
The implication for content strategy is clear: density beats length. Focus on being the most relevant source for a query, not the longest.
Investigation Report: How Google selects the Perfect Snippet.
 Dan Petrovic ·
Dec 20, 18:16
Dan Petrovic ·
Dec 20, 18:16
Great thinking! I’m going to test small modular content pieces that can be assembled into different content units like lego blocks and take charge of completeness of context. Avoid undesirable narrative fragmentation.
Dan Petrovic ·
SupportsSuggests · ·
Dec 25, 05:04
Great research as always, and very interesting! One thought:
– Longer articles don’t seem to lead to more coverage, but the SEO ranking does seem to impact the share of words that a ranked website receives. So, we might see a cat-and-mouse game play out, where articles become shorter, allowing a higher percentage of the text to be included in the grounding process, but resulting in lower SEO rankings and therefore a smaller word budget.
You’re quickly becoming my favorite person in the SEO space. Can you share more about your methodology?
I did a pretty detailed reply on LinkedIn so I’ll copy paste it here for full context:
From: Rohit Singh
Daniel Cheung few problems here – dataset not shared neither anything on approach. Only results are shared to make a claim.
I am not saying claim by Dan Petrovic is incorrect. But if a claim is made it, it should get independently verified.
I am not saying by me, anyone can do it.
Few questions to ask –
1) How were the 7,060 queries selected? If queries were hand-picked or concentrated in specific domains (e.g., technical, news, e-commerce, etc.), the findings may not generalize to all search types .
2) How were “grounding words” matched to original page content? Whether exact string matching, fuzzy matching, or semantic similarity was used significantly affects measurement accuracy .
3) Were confounding variables controlled (page authority, freshness, structure)? The “density beats length” conclusion assumes content length is the primary variable, but other factors like domain trust or formatting could drive the results.
4) Why no confidence intervals or significance tests for the “~2,000 word budget” claim? The data shows substantial variance but no statistical testing validates whether this represents a true fixed budget or random variation.
Dan Petrovic
1. Several clients: health, travel, finance, marketing, sports, b2b, marketplace, gambling… perhaps a few industries I forgot. First I define primary entities and then expand them to an arbitrary number of prompts, each prompt is mined via google search enabled grounding tool API call, all metadata collected and saved (fanouts, grounded chunks, grounding urls, confidence scores…etc).
2. I observe actual grounding snippets supplied to the model as context before it synthesizes its answers. No fuzzy matching the segments are exact with some minor goofs. They map cleanly to page source text as it’s extractive and not abstractive summarization.
3. No.
4. ~2,000 is a median. p95: 2,798 it goes up to ~5,000 and one sample with ~30,000 but I think that’s a bug in my pipeline.
I can’t share the data in public for two reasons:
1. client data
2. (can’t tell the 2nd reason or I’d be revealing it)
If you’re interested in peer-review analysis I’ll share with you directly.
Dan Petrovic ·
QuestionsExpands · ·
Dec 25, 05:02
Does it mean that if a topic is covered completely one one document and if that goes beyond 2000words, and if the answer to query lies at bottom end. It wont get cited?
Sign in with Google to comment.
Great study thanks for sharing this Dan! This suggests a move a way from long form content, which is seen as important for traditional SEO (obviously EEAT takes precedence over length). Do you foresee a future where we are creating “AI dictionaries” as part of a site where there is lots of detailed, focussed, shorter content designed to only be read by AI’s alongside the more in-depth content? Or an evolution where content actually starts to become shorter overall?