LinkjeBERT is a Dutch language model trained on structured Markdown to predict where humans will place links in text using token-level confidence levels.
We are excited to introduce LinkjeBERT, a new language model trained specifically for our Dutch-speaking friends around the world. LinkjeBERT is a link expert. When you give it plain text, it can predict exactly where a human editor would place a link, doing so even better than models like Gemini, Claude, or GPT.
To achieve this, the model was trained for seven days on two hundred million tokens of high-quality training data from top editorial websites covering news, tech, science, and lifestyle. It is built on top of Microsoft’s multilingual transformer, mDeBERTa-v3-base, and fine-tuned as a binary token classifier. Every single token is evaluated to determine if it should be part of a link anchor. Because links are relatively rare in natural text, we used a specialized loss function to handle the class imbalance.
Our breakthrough came when we changed how the model sees text. Our first versions were trained on flat, unformatted text, but they struggled because they missed the structural cues humans rely on. For LinkjeBERT, we decided to train on structure-preserving Markdown. This means the model can see headings, lists, bold text, and blockquotes. By understanding the document's skeletal structure, it gains the same contextual signals a human editor uses. To our knowledge, this is the first link prediction model ever trained on structured markup rather than flat text, making it an incredibly powerful tool for link building.
Today we're releasing LinkjeBERT (link-ye-bert) a new language model trained for our Dutch speaking friends around the world. This model is a link expert and is able to predict human behaviour. Specifically when supplied plain text, it can predict where a human will place a link. It can do that better than Gemini, Claude or GPT. This makes it the most powerful link building tool imaginable, bested only by its big brother LinkBERT, the original English language link expert model we released a few years ago.
To illustrate what LinkjeBERT does we've used a part of this page and fed its plain text content to the model. Here are the links created by a human editor:

And here are LinkjeBERT's predictions showing as a heatmap. We've purposely allowed display of low probability tokens to illustrate that the link placement isn't binary and instead model returns confidence levels for each token.

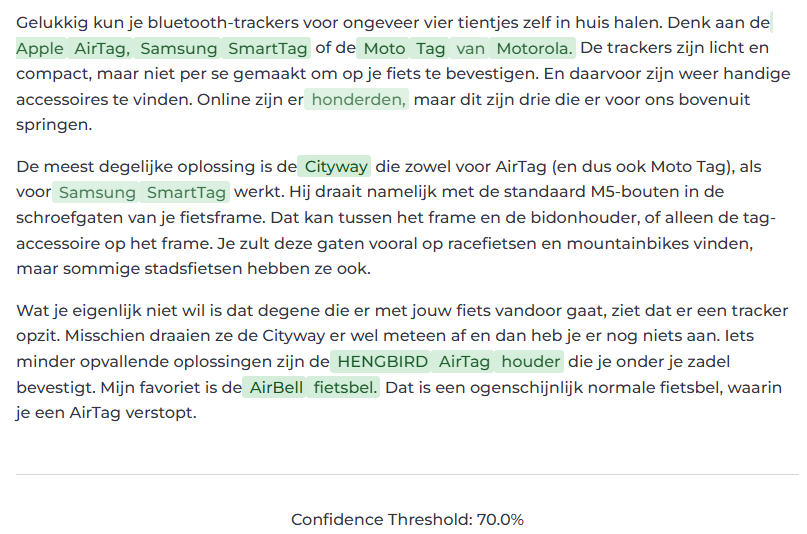
In a production pipeline we typically define an acceptable threshold for the task at hand and reduce link recommendations to those which meet the criteria. Here's one example:
LinkjeBERT was trained for 7 days on 200,000,000 tokens of training data sourced from the highest quality editorial websites including news, politics, tech, cooking, science and lifestyle.
Training Details
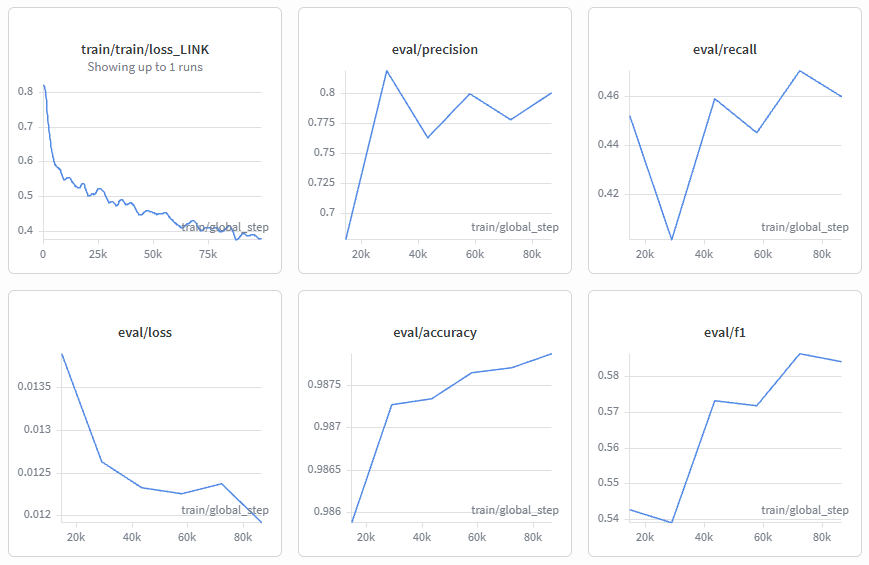
LinkjeBERT is built on top of Microsoft's mDeBERTa-v3-base, a multilingual transformer, fine-tuned as a binary token classifier. Every token in the input is classified as either O (not a link) or LINK (part of a link anchor). We used focal loss (γ=2.0) to handle the heavy class imbalance — in natural text, the vast majority of tokens are not links. Training ran for 10 epochs with early stopping (patience 3, monitoring F1), learning rate 2e-5 with linear warmup, effective batch size 32, and bf16 mixed precision on an RTX 4090. Documents longer than 512 tokens are handled via overlapping windows (stride 128) with max-pooled probabilities across overlaps. Shows it works on real articles, not just short chunks.
What we tried and discarded
LinkjeBERT went through three major iterations. The first two versions were trained on flat extracted text — paragraphs stripped of all formatting. They worked, but something was off. The model was missing structural cues that human editors clearly rely on: is this a heading or body text? Is this a list item or a blockquote? Flat text erased all of that.
The Markdown breakthrough
This is where LinkjeBERT diverges from its English predecessor. The original LinkBERT was trained on plain text. LinkjeBERT3 is trained on structure-preserving Markdown. The training data retains headings (#, ##), bold (**), italics (*), lists (-), and blockquotes (>). The model sees the document's skeletal structure as part of its input, giving it the same contextual signals a human editor uses when deciding where a link belongs. To our knowledge, this is the first link prediction model trained on structured markup rather than flat text.
 Dan Petrovic ·
Jul 05, 15:09
Dan Petrovic ·
Jul 05, 15:09