An experimental study reproducing the vec2vec research paper by attempting to translate and align Gemini and MxbAI embedding spaces using unsupervised methods.
Can we translate text embeddings from one AI model to another without any paired data? A recent research paper claims they all share a universal geometry, meaning we can map them to each other, or even reverse-engineer them.
To test this, I set up an experiment comparing Google's Gemini embeddings with an open-source model called Mixedbread AI. In the first round, the models had different dimensions. Interestingly, translating from the higher-dimensional Gemini space to the lower-dimensional Mixedbread space was highly accurate. But going the other way, from low to high, completely failed.
For the next attempt, I used a technique called Matryoshka Representation Learning to make their dimensions equal. I trained a translation model to align the two spaces, but the mapping barely moved the needle. Document retrieval was no better than random guessing. Even when I scaled up to a much larger dataset, the translation quality remained very low.
While the theory of a universal embedding geometry is fascinating, these tests show that practical translation is incredibly difficult. The quality depends heavily on the direction of translation, the size of the dataset, and how we handle different dimensionalities.
Prompted by Darwin Santos on the 22th of May and a few days later by Dan Hickley, I had no choice but to jump on this experiment, it’s just too fun to skip. Especially now that I’m aware of the Gemini embedding model.
The objective is to do reproduce the claims of this research paper which claims that all embeddings share common geometry in multi-dimensional space and can therefore be mapped to each other, or even reverse engineered. I’m a little skeptical at this stage but happy to give it a try.
Harnessing the Universal Geometry of Embeddings
Rishi Jha, Collin Zhang, Vitaly Shmatikov, John X. Morris
We introduce the first method for translating text embeddings from one vector space to another without any paired data, encoders, or predefined sets of matches. Our unsupervised approach translates any embedding to and from a universal latent representation (i.e., a universal semantic structure conjectured by the Platonic Representation Hypothesis). Our translations achieve high cosine similarity across model pairs with different architectures, parameter counts, and training datasets.
The ability to translate unknown embeddings into a different space while preserving their geometry has serious implications for the security of vector databases. An adversary with access only to embedding vectors can extract sensitive information about the underlying documents, sufficient for classification and attribute inference.
I’ll be live blogging as I do things so keep an eye on this post as things develop.
Testing Gemini model embedding generation. Done.
Observation: The gemini-embedding-exp-03-07 model produces 3,072-dimensional vectors.
Defining the scrape list based on post and page sitemaps.
Scraping the site:
Generating Gemini embeddings (API calls):
Generating mxbai-embed-large-v1 embeddings (locally):
On the task are several AI Agents.
Manus
Codex
Jules
The original vec2vec paper reported the following metrics for different model pairs:
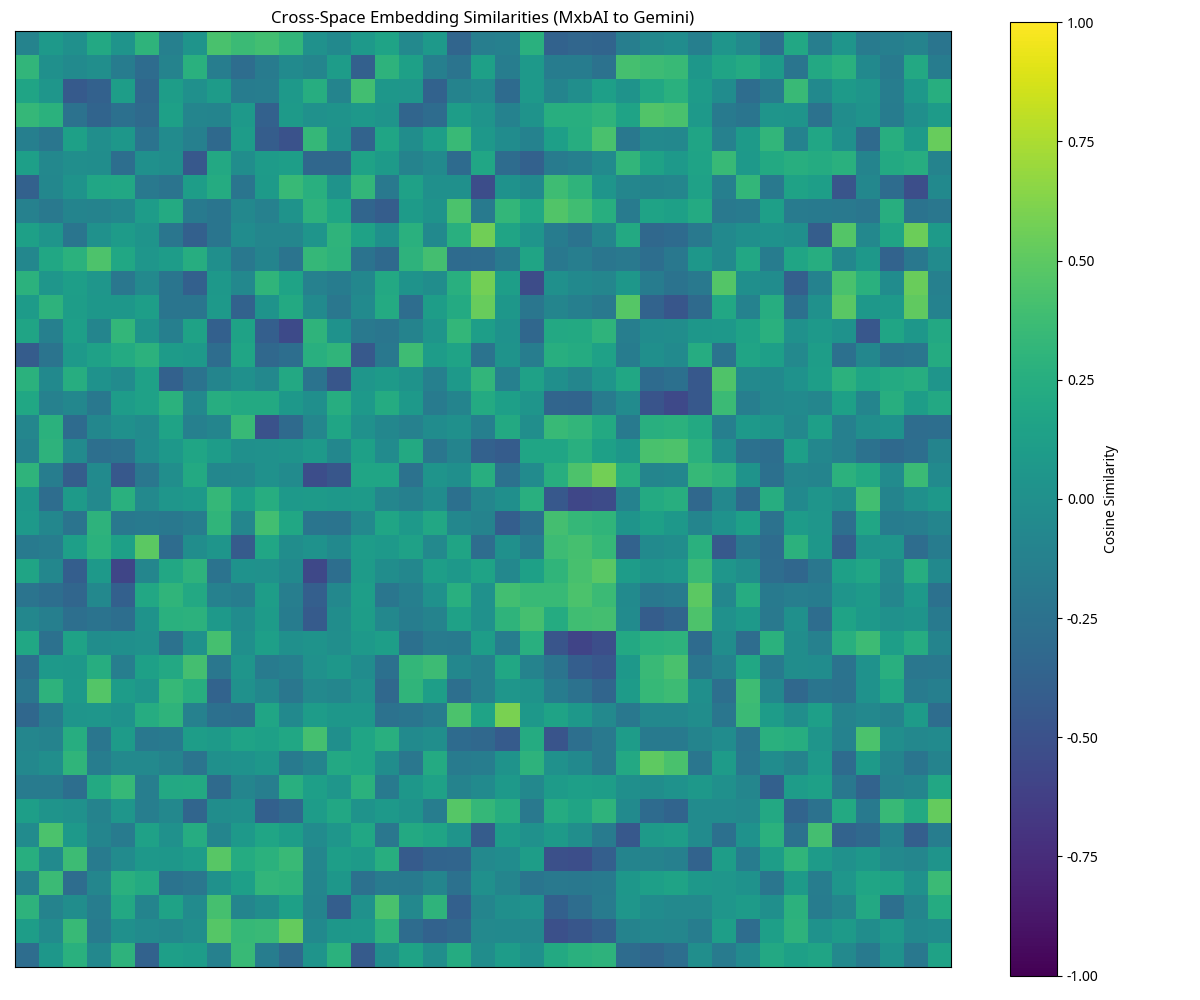
Our results show moderate alignment with the paper’s findings, achieving reasonable cosine similarity between the MxbAI and Gemini embedding spaces.
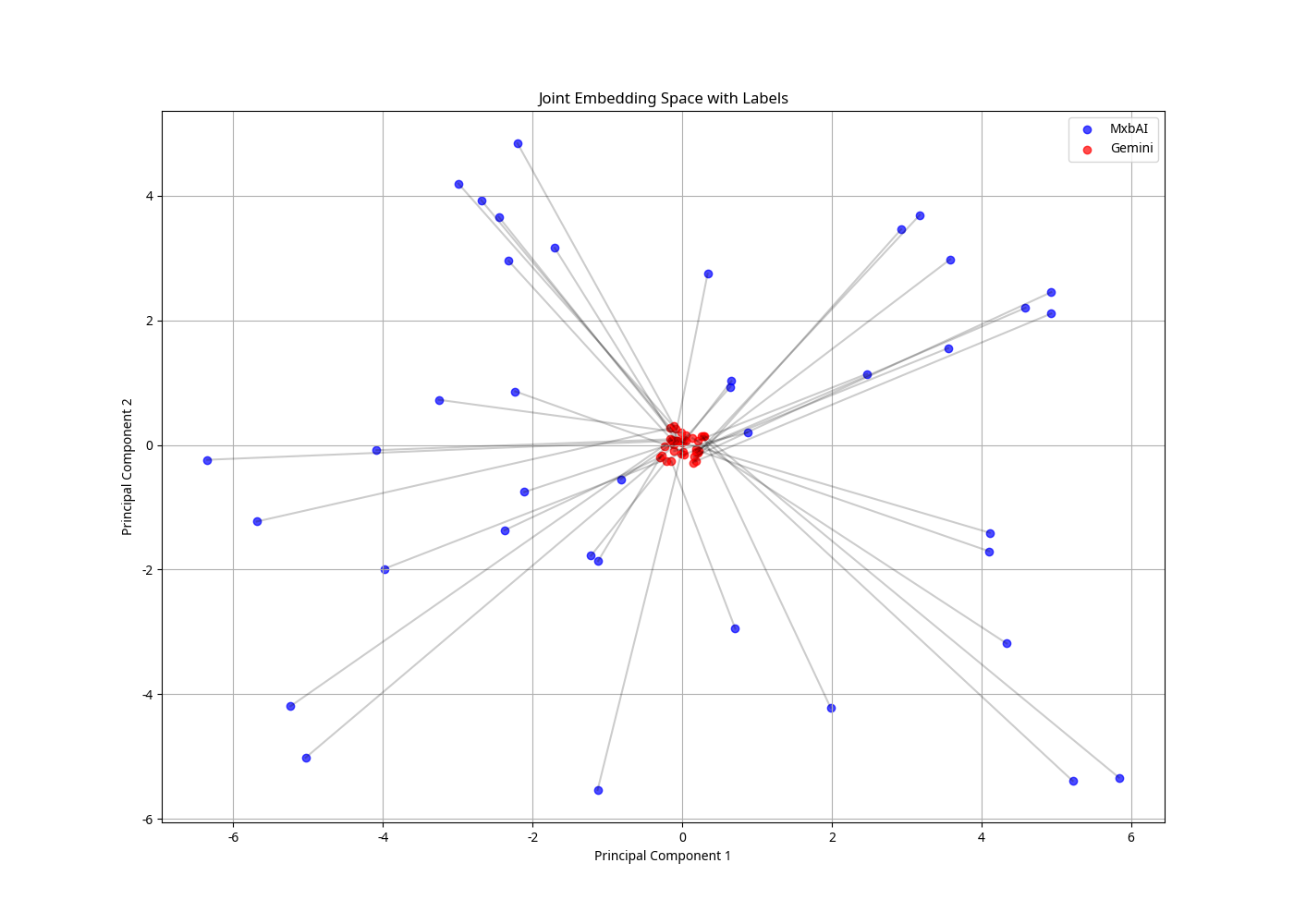
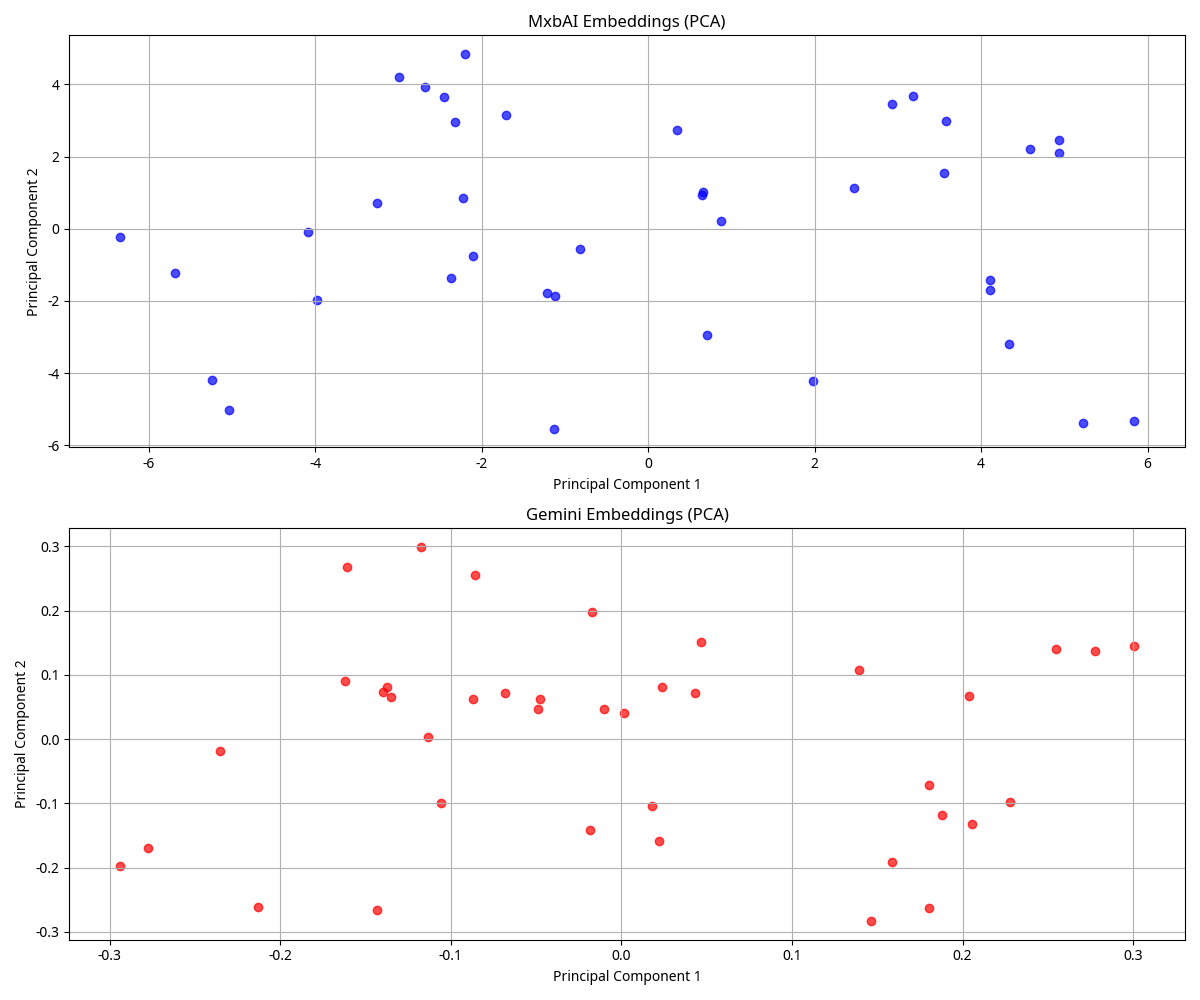
To better understand the structure of each embedding space, we’ve created PCA visualizations that project the high-dimensional embeddings into 2D space:
embedding_spaces_visualization.png: Shows the distribution of embeddings in each spaceembedding_spaces_with_labels.png: Includes URL labels for a subset of points to identify specific contentjoint_embedding_space.png: Visualizes both embedding spaces in a common reduced spacejoint_embedding_space_labeled.png: Includes labels in the joint space visualizationWe’ve also analyzed the similarity relationships within and between embedding spaces:
similarity_heatmaps.png: Shows the cosine similarity matrices for each embedding spacecross_similarity_heatmap.png: Shows the cross-space similarities between dimensionality-reduced MxbAI and Gemini embeddingsThe significant difference in embedding dimensions (MxbAI: 1024 vs Gemini: 3072) suggests that:
The stark difference in translation performance between directions is particularly noteworthy:
This asymmetry suggests that:
The vec2vec paper demonstrated that embedding spaces from different models can be aligned through linear transformations. Our results show that this holds true even when:
However, our results also highlight an important limitation: the translation quality is highly dependent on the direction of translation when embedding spaces have significantly different dimensionalities.
Both mixedbread-ai/mxbai-embed-large-v1 and gemini-embedding-exp-03-07 support MRL (Matryoshka Representation Learning) dimensionality reduction so the feature extraction was adjusted and now we work with consistent embeddings.
This script implements Vec2Vec, an unsupervised embedding translation model inspired by the paper “Harnessing the Universal Geometry of Embeddings”. It learns to map embeddings from two different vector spaces (e.g., Gemini and MxbAI) into a shared latent space using deep residual networks, without any labeled alignment. The architecture includes input/output adapters, a shared backbone, and adversarial discriminators to align both original and latent distributions. Training optimizes reconstruction, cycle-consistency, vector space preservation, and GAN losses. The trainer includes evaluation utilities and checkpointing, making the framework modular and extensible for cross-domain embedding alignment.
Epoch 100: 100%|█████████████████████| 1/1 [00:00<00:00, 17.18it/s, g_loss=13103.4541, rec_loss=3.8386, cc_loss=3.6557]
INFO:__main__:Epoch 100 - d_loss: 0.0816 - g_loss: 13103.4541 - g_loss_adv: 18.3283 - rec_loss: 3.8386 - cc_loss: 3.6557 - vsp_loss: 13010.1836
INFO:__main__:Evaluation - cos_sim_1to2: 0.0039 - cos_sim_2to1: 0.0020 - top1_1to2: 0.0513 - top1_2to1: 0.0513 - rank_1to2: 16.7179 - rank_2to1: 21.3077
INFO:__main__:Saved checkpoint at epoch 100
INFO:__main__:Training completed!
INFO:__main__:Final evaluation...
INFO:__main__:Final metrics - cos_sim_1to2: -0.0058 - cos_sim_2to1: 0.0058 - top1_1to2: 0.0513 - top1_2to1: 0.0513 - rank_1to2: 22.4103 - rank_2to1: 18.5128Download the trained model here.
PS C:\projects\gemini\analysis> python vec2vec_quickstart.py –compare
INFO:vec2vec_implementation:Loaded 39 embeddings of dimension 1024 from gemini.csv
INFO:vec2vec_implementation:Loaded 39 embeddings of dimension 1024 from mxbai.csv
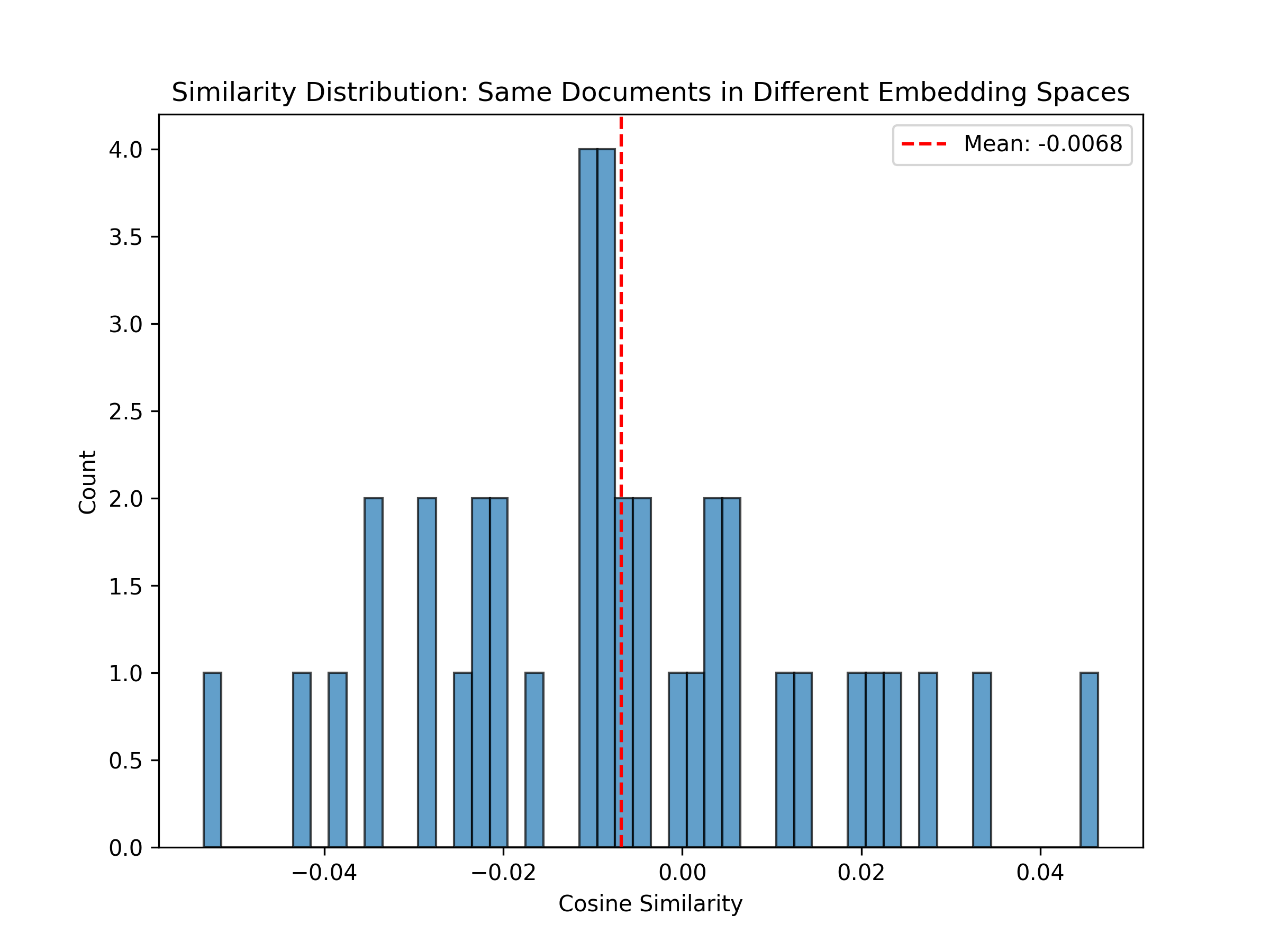
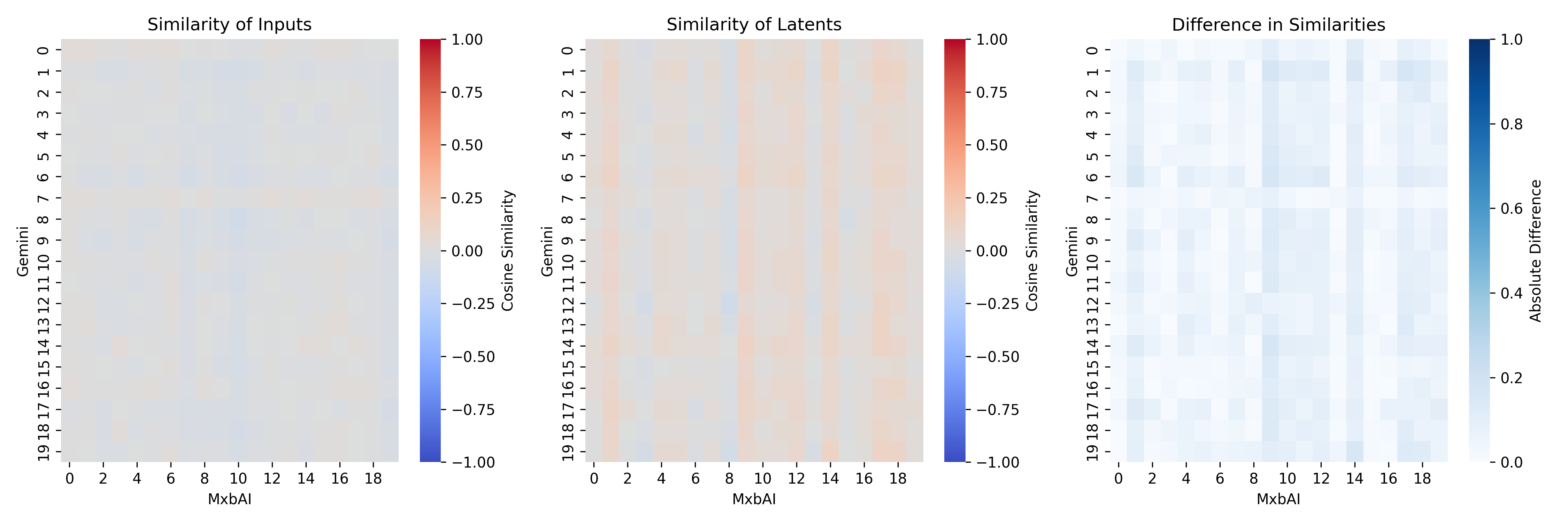
Cosine similarity between same documents in different spaces:
Mean: -0.0068
Std: 0.0213
Min: -0.0535
Max: 0.0465
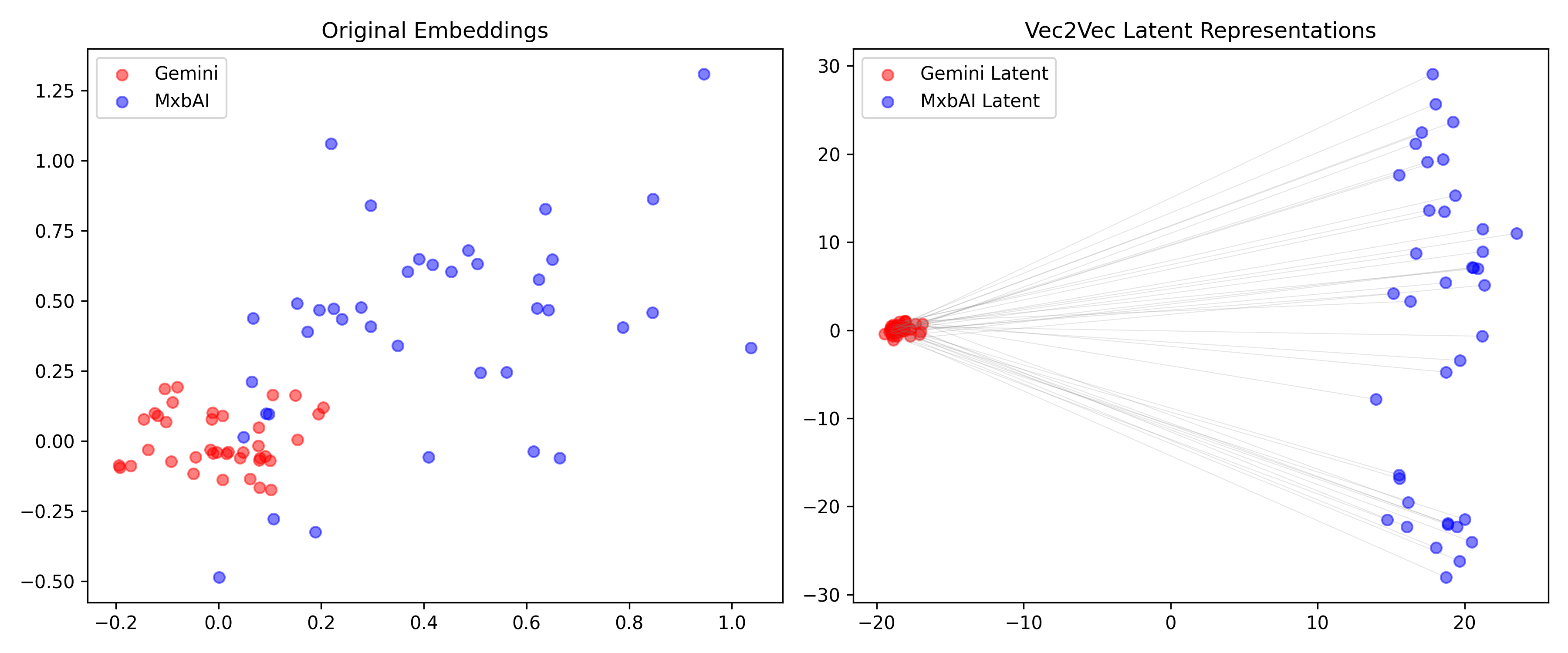
mean_cos_sim_1to2…………. -0.0006
mean_cos_sim_2to1…………. 0.0049
std_cos_sim_1to2………….. 0.0270
std_cos_sim_2to1………….. 0.0299
top1_acc_1to2…………….. 0.0000
top1_acc_2to1…………….. 0.0000
top5_acc_1to2…………….. 0.1795
top5_acc_2to1…………….. 0.1795
top10_acc_1to2……………. 0.3077
top10_acc_2to1……………. 0.2821
mean_rank_1to2……………. 18.4103
mean_rank_2to1……………. 18.4615
cycle_error_1…………….. 1.5673
cycle_error_2…………….. 2.0849
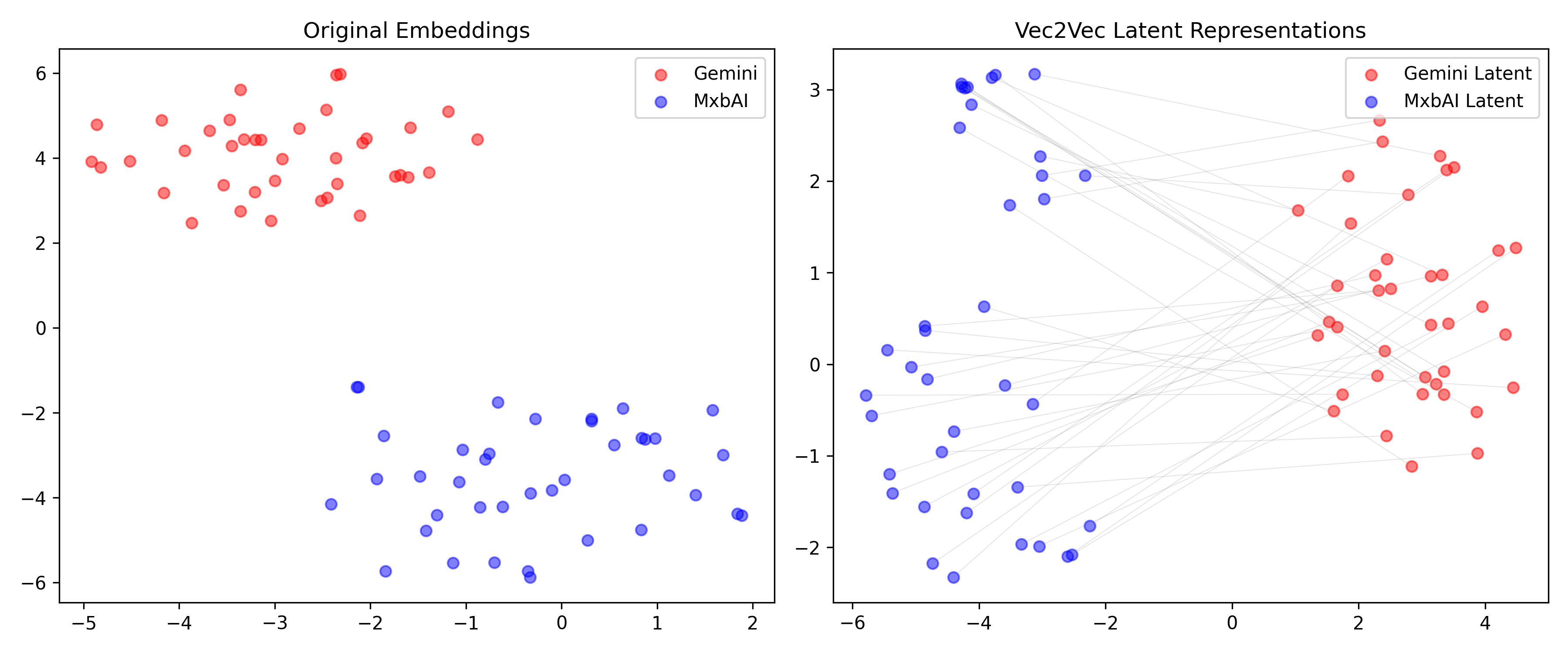
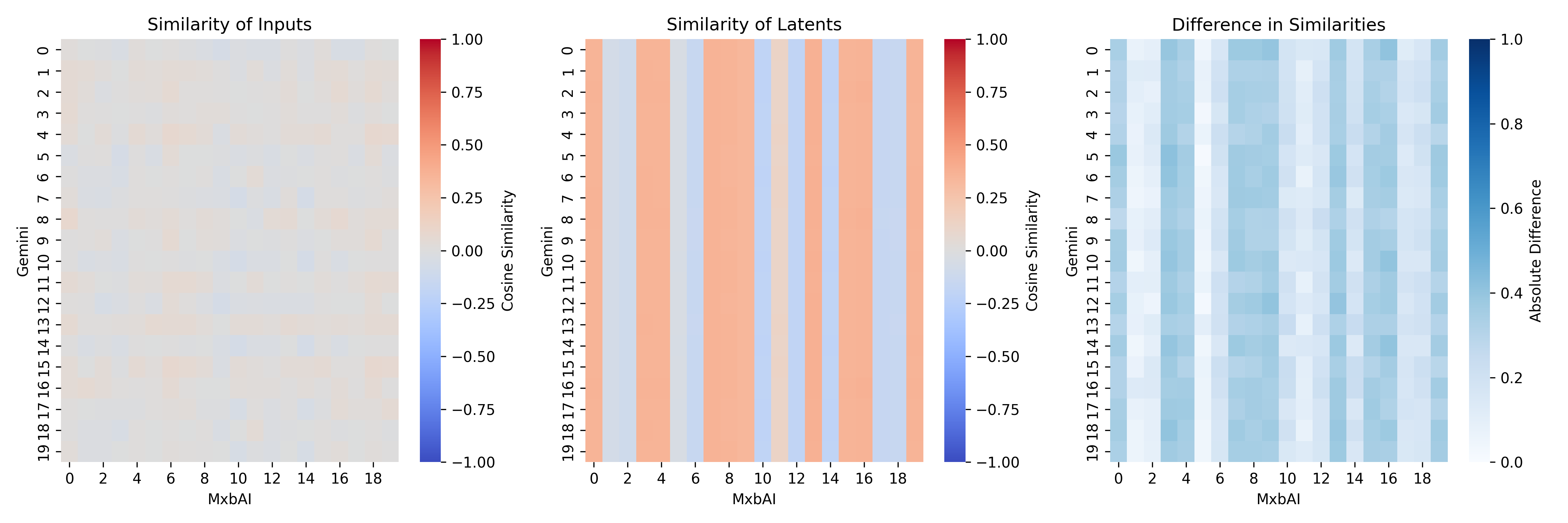
INFO:vec2vec_evaluation:Computing latent alignment…Mean cosine similarity:
Input space: -0.0068 ± 0.0213
Latent space: 0.0346 ± 0.0455
INFO:vec2vec_evaluation:Visualizing latent space…
INFO:vec2vec_evaluation:Plotting similarity heatmaps…
INFO:vec2vec_evaluation:Saving translated embeddings…
INFO:vec2vec_evaluation:Saved translated embeddings to translated_embeddings
INFO:vec2vec_evaluation:
Demonstration: Finding similar documents across spaces
Gemini document 0 (https://dejan.ai/blog/gemini-system-prompt/):
Top 5 similar MxbAI documents after translation:
Gemini document 1 (https://dejan.ai/blog/how-gemini-selects-results/):
Top 5 similar MxbAI documents after translation:
Gemini document 2 (https://dejan.ai/blog/search-query-quality-classifier/):
Top 5 similar MxbAI documents after translation:
Gemini document 3 (https://dejan.ai/blog/query-intent-via-retrieval-augmentation-and-model-distillation/):
Top 5 similar MxbAI documents after translation:
Gemini document 4 (https://dejan.ai/blog/resource-efficient-binary-vector-embeddings-with-matryoshka-representation-learning/):
Top 5 similar MxbAI documents after translation:
pipeline ran end-to-end, but the learned mapping barely moved the needle:
--compare: mean cos sim across spaces = –0.0068 ± 0.0213In progress…
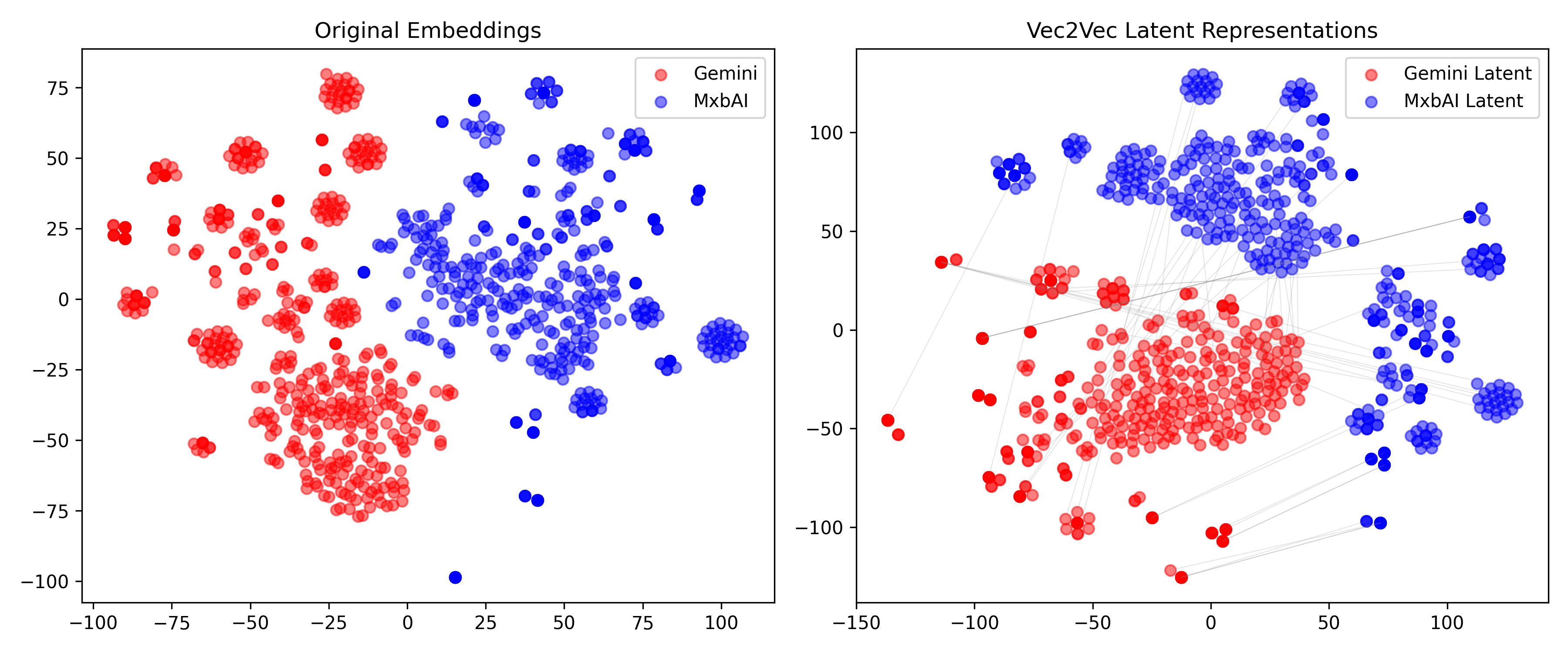
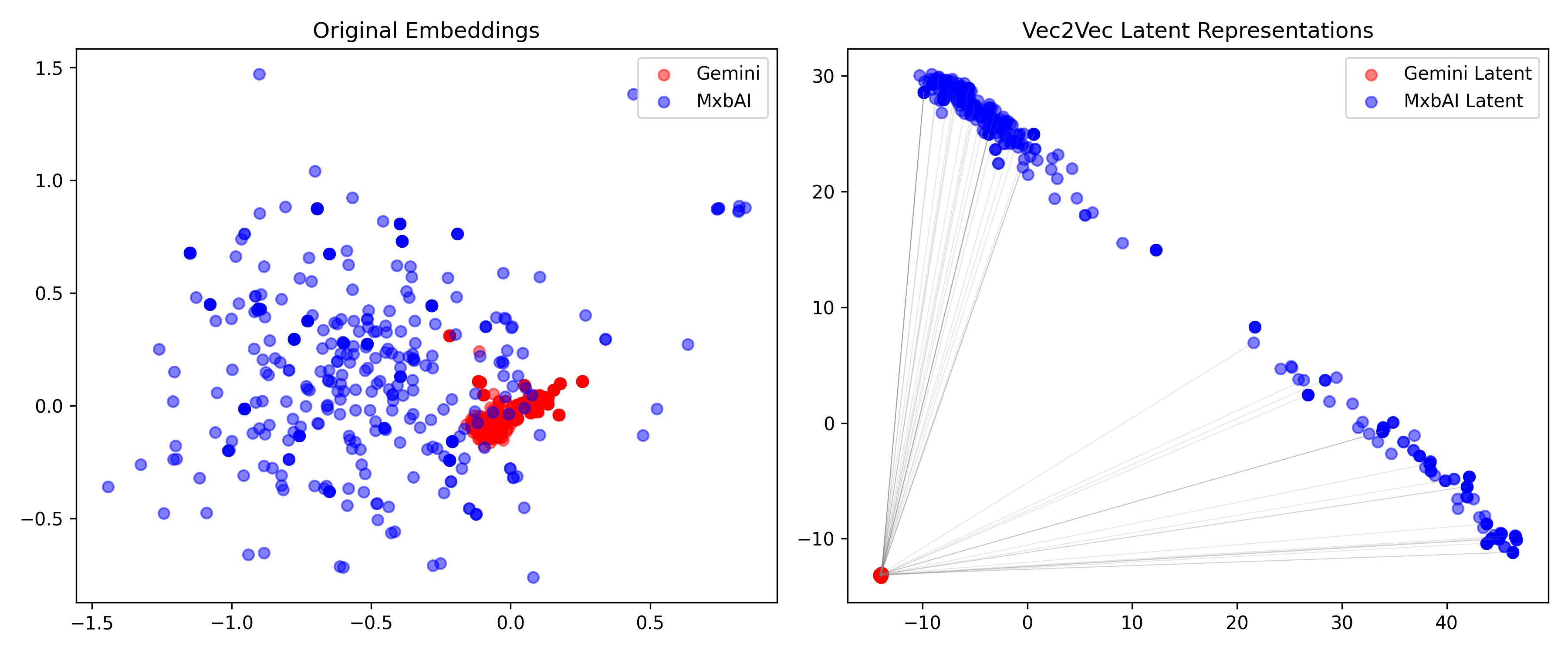
mean_cos_sim_1to2…………. 0.1613
mean_cos_sim_2to1…………. 0.0324
std_cos_sim_1to2………….. 0.0307
std_cos_sim_2to1………….. 0.0230
top1_acc_1to2…………….. 0.0200
top1_acc_2to1…………….. 0.0100
top5_acc_1to2…………….. 0.0900
top5_acc_2to1…………….. 0.0400
top10_acc_1to2……………. 0.1500
top10_acc_2to1……………. 0.0800
mean_rank_1to2……………. 47.1500
mean_rank_2to1……………. 48.3100
cycle_error_1…………….. 0.1456
cycle_error_2…………….. 0.2661
INFO:vec2vec_evaluation:Computing latent alignment…
Mean cosine similarity:
Input space: 0.0031 ± 0.0313
Latent space: 0.1729 ± 0.2319
Gemini document 0 (https://www.engadget.com/products/sony/bravia/kdl-46hx800/):
Top 5 similar MxbAI documents after translation:
Gemini document 1 (https://www.engadget.com/2010-07-13-book-review-you-are-not-a-gadget.html):
Top 5 similar MxbAI documents after translation:
Gemini document 2 (https://www.engadget.com/products/garmin/nuvi/1250/):
Top 5 similar MxbAI documents after translation:
Gemini document 3 (https://www.engadget.com/products/nikon/coolpix/s3100/):
Top 5 similar MxbAI documents after translation:
Gemini document 4 (https://www.engadget.com/sony-a-7-c-review-smart-small-clumsy-153031933.html):
Top 5 similar MxbAI documents after translation:
 Dan Petrovic ·
May 24, 11:39
Dan Petrovic ·
May 24, 11:39
Sign in with Google to comment.