An exploration of building tiny, logic-first models using cellular automata to challenge the transformer paradigm and identify the primitives of reasoning.
A weekend project that turned into a bet against the whole transformer playbook.
Almost every AI you’ve heard of is a transformer trained on a firehose of text. It learns language first, and reasoning sort of comes along for the ride. I’m trying the opposite: a tiny model that learns logic and reasoning first, with language deferred — maybe learned later, maybe allowed to emerge on its own.

Oh, and the model is about 10 megabytes. People have JPEGs bigger than that.
I started on ARC-AGI — a benchmark of little grid puzzles where you see a few input-to-output examples, infer the rule, and apply it to a fresh grid. It’s deliberately built to resist memorization. You can’t brute-force it with scale; you have to actually generalize from a handful of examples. That’s the part of intelligence I care about.
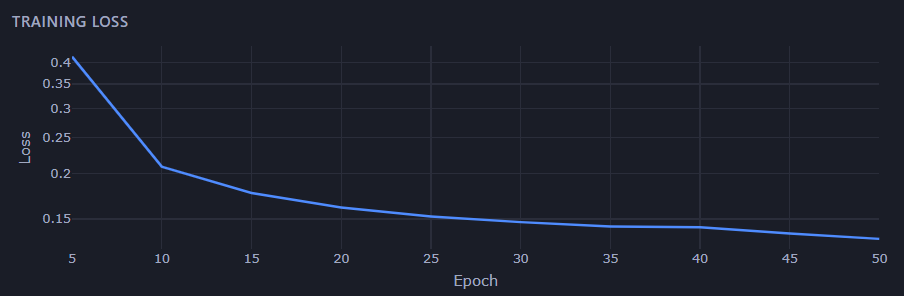
My first model wasn’t a transformer at all. It was a cellular automaton — think Conway’s Game of Life, except the update rule is learned and conditioned on each puzzle’s examples. Every cell only talks to its immediate neighbors. Intelligence, if it shows up, has to emerge from purely local interactions.
It works — on some puzzles. The model cleanly generalizes things like recoloring, filling holes, and drawing outlines. These are all local operations: what a cell should become depends only on what’s around it.
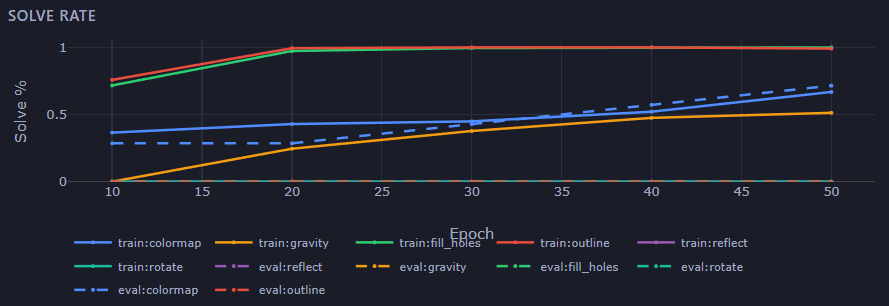
And it completely fails — 0%, even on the training data — on reflection, rotation, and gravity.
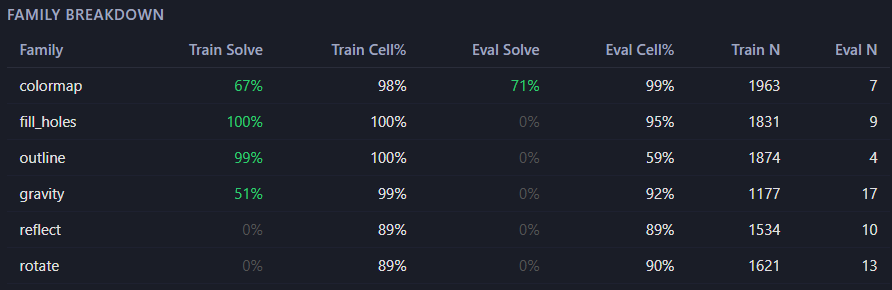
Those require a cell to know about the whole grid: where’s the axis of symmetry? How wide am I? A purely local rule structurally can’t answer that. It’s not a tuning problem I can grind away with more epochs — it’s a ceiling baked into the design.
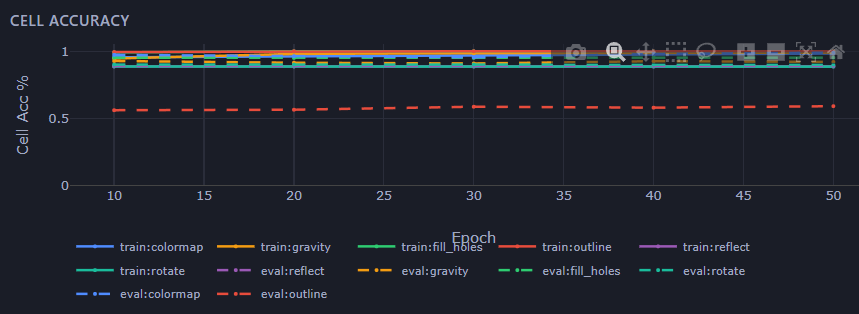
That failure is the most useful result I’ve gotten. It draws a sharp line: locality buys you one specific slice of reasoning and nothing past it. Now I know exactly what the next building block has to add.
Here’s the thought I keep circling back to. Transformers didn’t win because they’re the only road to intelligence. They won because they hit a sweet spot of three things at once: they’re expressive, they’re trainable at scale, and they map beautifully onto GPUs. Then the whole industry — CUDA, PyTorch, Nvidia, the entire stack — calcified around that one choice.
But intelligence is computational, and there are probably countless configurations of computation that could get us there. The brain is one of them — wildly efficient, runs on roughly 20 watts — and even it “just is”: a path evolution happened to stumble into, not necessarily the best one.
So I’m asking a different question. Not “how do I scale the thing everyone already scales,” but: what are the primitives — the actual building blocks — that an intelligent system needs, that the transformer paradigm quietly skipped?
Every time I write that list down, it converges on the same handful of ideas — and they look a lot like how brains actually work:
None of this is in a transformer. All of it is in you.
You don’t need a 5090 and a cloud bill to test a primitive. That’s the whole point of starting small: the interesting traits of intelligence — generalizing, binding concepts together, adapting on the fly — should start showing up in tiny seed-stage models, before scale and complexity bog everything down. So I build small, add one primitive at a time, and watch which abilities switch on. Churn fast, test fast, take notes.
Will it beat ARC-AGI-2 with a sub-100MB model? Probably not this weekend. But every “failure” so far has been drawing the map of what reasoning actually requires — and that map is the entire point.
Follow along if that sounds like your kind of rabbit hole.
 Dan Petrovic ·
Jun 19, 13:45
Dan Petrovic ·
Jun 19, 13:45