An examination of the Chrome codebase reveals that the history_embeddings component uses the dot product of normalized vectors to perform similarity searches.
If you want to understand how Google engineers approach machine learning, looking at the open source Chrome codebase is a great place to start. A close look at Chrome's browser history search tool reveals a clever, highly efficient approach to vector similarity.
To find similar history items, Chrome compares vector embeddings. Instead of using a standard cosine similarity formula, the code normalizes all vectors to a unit length of one. Then, it calculates the dot product between them.
Mathematically, when your vectors are already normalized to a magnitude of one, the dot product and cosine similarity are exactly the same. The standard cosine formula requires dividing the dot product by the magnitudes of the vectors. By ensuring every vector is already normalized, Google eliminates that division step entirely.
This approach gives you the exact same mathematical result as cosine similarity, but with much less computational overhead. It is a simple, elegant optimization that makes semantic search in the browser incredibly fast and efficient. It is a classic example of how Google designs for performance at scale.
How Googler’s work and think internally typically aligns with their open source code (Gemini -> Gemma) and Chrome is no exception. It’s why I look there for answers and clarity on Google’s machine learning approaches.
After examining the Chrome codebase, I found the following key evidence regarding the similarity method used:
The core similarity calculation is implemented in the ScoreWith method of the Embedding class in vector_database.cc:
float Embedding::ScoreWith(const Embedding& other_embedding) const {
// This check is redundant since the database layers ensure embeddings
// always have a fixed consistent size, but code can change with time,
// and being sure directly before use may eventually catch a bug.
CHECK_EQ(data_.size(), other_embedding.data_.size());
float embedding_score = 0.0f;
for (size_t i = 0; i < data_.size(); i++) {
embedding_score += data_[i] * other_embedding.data_[i];
}
return embedding_score;
}This implementation is calculating the dot product of two embedding vectors.
The code shows that embeddings are normalized to unit length:
void Embedding::Normalize() {
float magnitude = Magnitude();
CHECK_GT(magnitude, kEpsilon);
for (float& s : data_) {
s /= magnitude;
}
}And in the FindNearest method in VectorDatabase, there’s a check to ensure the query embedding has unit magnitude:
// Magnitudes are also assumed equal; they are provided normalized by design.
CHECK_LT(std::abs(query_embedding.Magnitude() - kUnitLength), kEpsilon);There’s also a constant defined:
// Standard normalized magnitude for all embeddings.
constexpr float kUnitLength = 1.0f;There are no direct references to “cosine” or “cosine similarity” in the codebase.
Based on the evidence, the code is using dot product between normalized vectors for similarity calculation.
It doesn’t really matter.
When vectors are normalized to unit length (magnitude = 1), the dot product is mathematically equivalent to cosine similarity. This is because:
Cosine similarity = (A·B) / (|A|·|B|)
When |A| = |B| = 1 (normalized vectors), this simplifies to:
Cosine similarity = A·B = dot product
Therefore, the code is effectively implementing cosine similarity by:
This approach is computationally more efficient than calculating the full cosine similarity formula, as it avoids the division operation while producing the same result for normalized vectors.
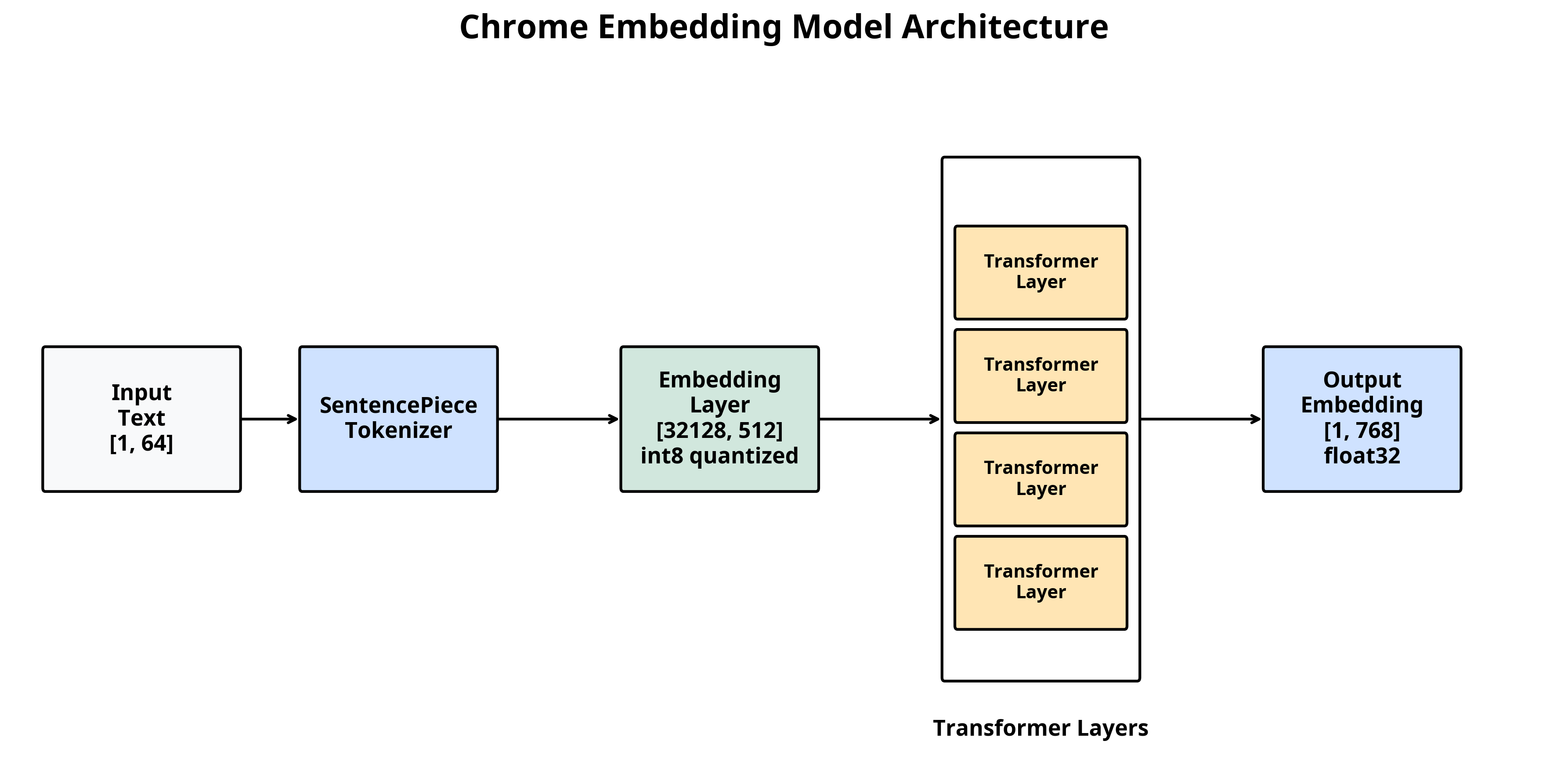
The archive contains a Chromium component called history_embeddings that implements a service for embedding and searching browser history using vector embeddings.
The files can be categorized as follows:
BUILD.gn, DEPS, DIR_METADATA, OWNERS, README.mdhistory_embeddings_service.h/cc: Main service implementationhistory_embeddings_features.h/cc: Feature flags and parameterspassage_embeddings_service_controller.h/cc: Controller for embeddings serviceembedder.h: Base interface for embedding text passagesml_embedder.h/cc: ML-based implementation of embedderscheduling_embedder.h/cc: Priority-based embedding schedulermock_embedder.h/cc: Mock implementation for testinganswerer.h/cc: Interface for generating answers from embeddingsml_answerer.h/cc: ML-based implementation of answerermock_answerer.h/cc: Mock implementation for testingvector_database.h/cc: Vector storage and similarity searchsql_database.h/cc: Persistent storage for embeddingspassages_util.h/cc: Utilities for text passage processingsearch_strings_update_listener.h/cc: Listener for search string updateshistory_embeddings.proto: Defines storage format for passages and embeddingspassage_embeddings_model_metadata.proto: Defines model metadatamock_history_embeddings_service.h/cc: Mock service for testingThe component implements a semantic search system for browser history that:
The approach is effective and computationally efficient. Sounds like Google to me.
 Dan Petrovic ·
Jun 19, 10:06
Dan Petrovic ·
Jun 19, 10:06
Absolutely. If direction is more important than intensity, use cosine similarity or normalize embeddings before computing dot-product.
Dan Petrovic ·
SuggestsExpands · ·
Jun 20, 13:17
Sign in with Google to comment.
With impact of vector magnitudes on similarity score, are there scenarios where using dot-product might accidentally exaggerate similarity, like for vectors with large magnitudes?
Or are web content/passage embeddings too few dimensions to worry about that?