
Category: Machine Learning
-
AI Brand Authority Index: Ranking 2.9 Million Brands by Associative Embeddedness in Gemini’s Memory
Abstract When a large language model is asked to “name 100 brands at random,” it doesn’t produce uniform randomness. It produces a distribution shaped by its training data, revealing which brands occupy the most cognitive real estate in the model’s parametric memory. We present a methodology for quantifying brand authority in AI memory using Personalized…
-

TurboQuant: From Paper to Triton Kernel in One Session
Implementing Google’s KV cache compression algorithm on Gemma 3 4B and everything that went wrong along the way. On March 24, 2026, Google Research published a blog post introducing TurboQuant, a compression algorithm for large language model inference. The paper behind it, “Online Vector Quantization with Near-optimal Distortion Rate” had been on arXiv since April…
-
Reverse Prompting: Reconstructing Prompts from AI-Generated Text
We fine-tuned Google’s Gemma 3 (270M) to reverse the typical LLM workflow: given an AI-generated response, the model reconstructs the most likely prompt that produced it. We generated 100,000 synthetic prompt-response pairs using Gemini 2.5 Flash, trained for a single epoch on a consumer GPU, and built a Streamlit app that sweeps 24 decoding configurations…
-
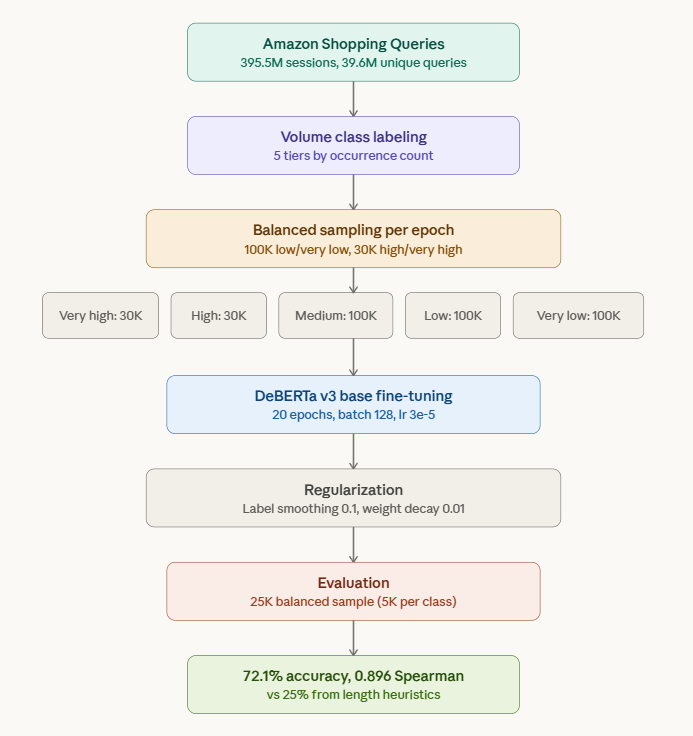
Is Query Length a Reliable Predictor of Search Volume?
The answer is no. There’s a widely held intuition in SEO and ecommerce search: short queries have high volume, long queries have low volume. “laptop” gets millions of searches. “left handed ergonomic vertical mouse wireless” does not. It feels obvious. But is query length actually a reliable predictor of search volume? Or is it a…
-
OpenAI’s Sparse Circuits Breakthrough and What It Means for AI SEO
OpenAI recently released research showing that AI models can be built with far fewer active connections inside them. This makes them easier to understand because each part of the model does fewer things and is less tangled up with everything else. Think of it like taking a spaghetti bowl and straightening the noodles into clean,…
-
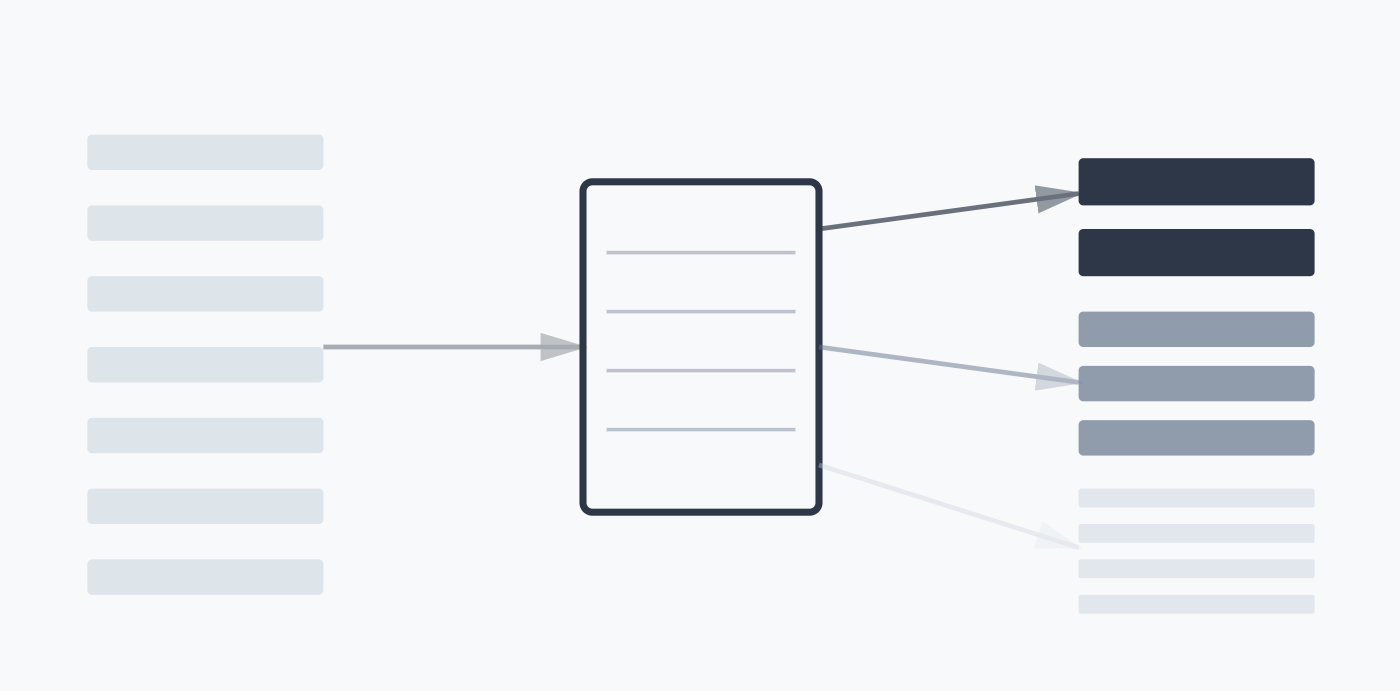
BlockRank: A Faster, Smarter Way to Rank Documents with LLMs
Large Language Models (LLMs) have revolutionized many areas of natural language processing, and information retrieval is no exception. A promising new paradigm called In-Context Ranking (ICR) leverages the contextual understanding of LLMs to re-rank a list of candidate documents for a given query. However, this power comes at a cost: the computational complexity of the…
-

From Free-Text to Likert Distributions: A Practical Guide to SSR for Purchase Intent
Instead of forcing LLMs to pick a number on a 1–5 scale, ask them to speak like a person and map the text to a Likert distribution via Semantic Similarity Rating (SSR). In benchmarks across 57 personal-care concept surveys (9.3k human responses), SSR reproduced human purchase intent signals with ~90% of human test–retest reliability and…
-
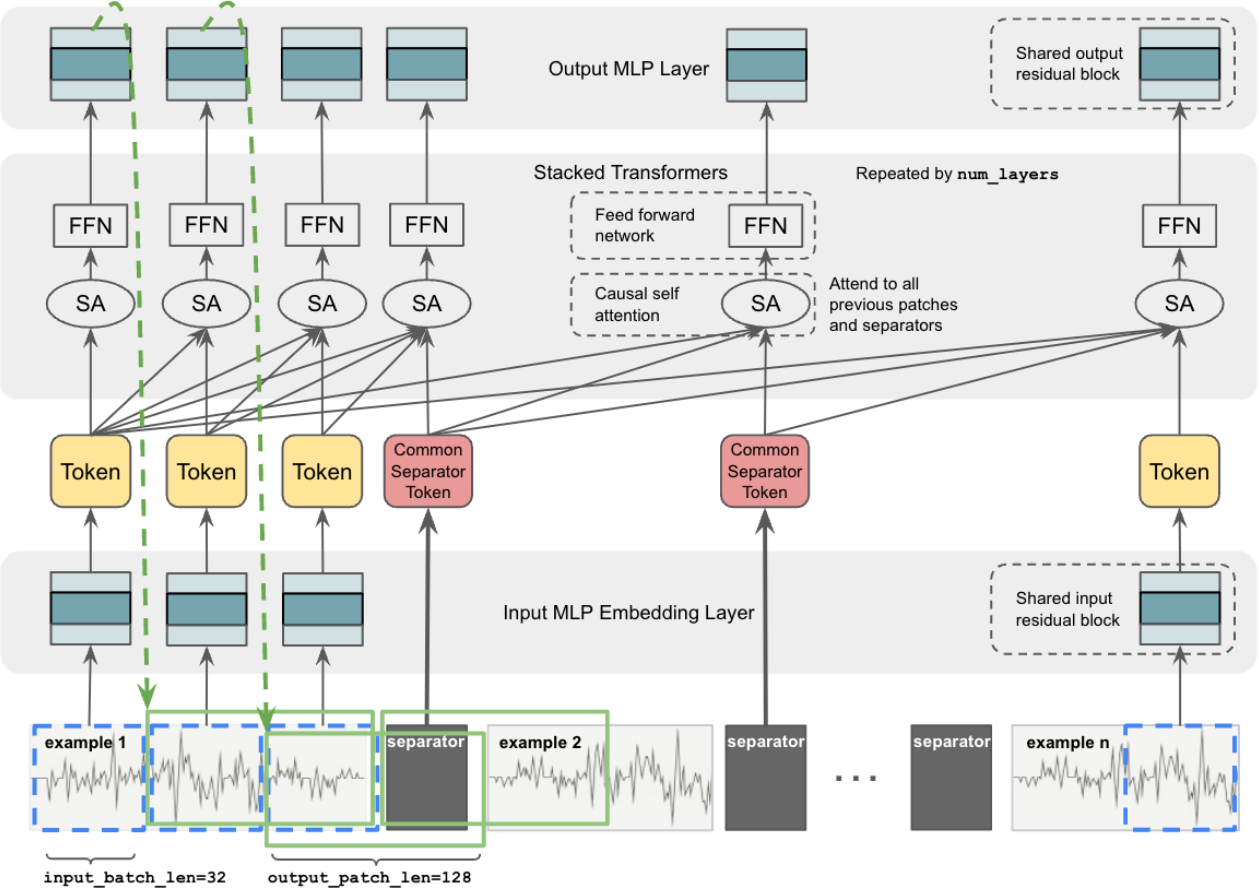
TimesFM-ICF
In-Context Fine-Tuning for Time-Series: The Next Evolution Beyond Prophet and Traditional Forecasting How Google’s TimesFM-ICF achieves fine-tuned model performance without training – and why this changes everything for production forecasting systems If you’re reading this, you’ve likely wrestled with time-series forecasting in production. Perhaps you’ve implemented Facebook Prophet for its interpretable seasonality decomposition, experimented with…
-
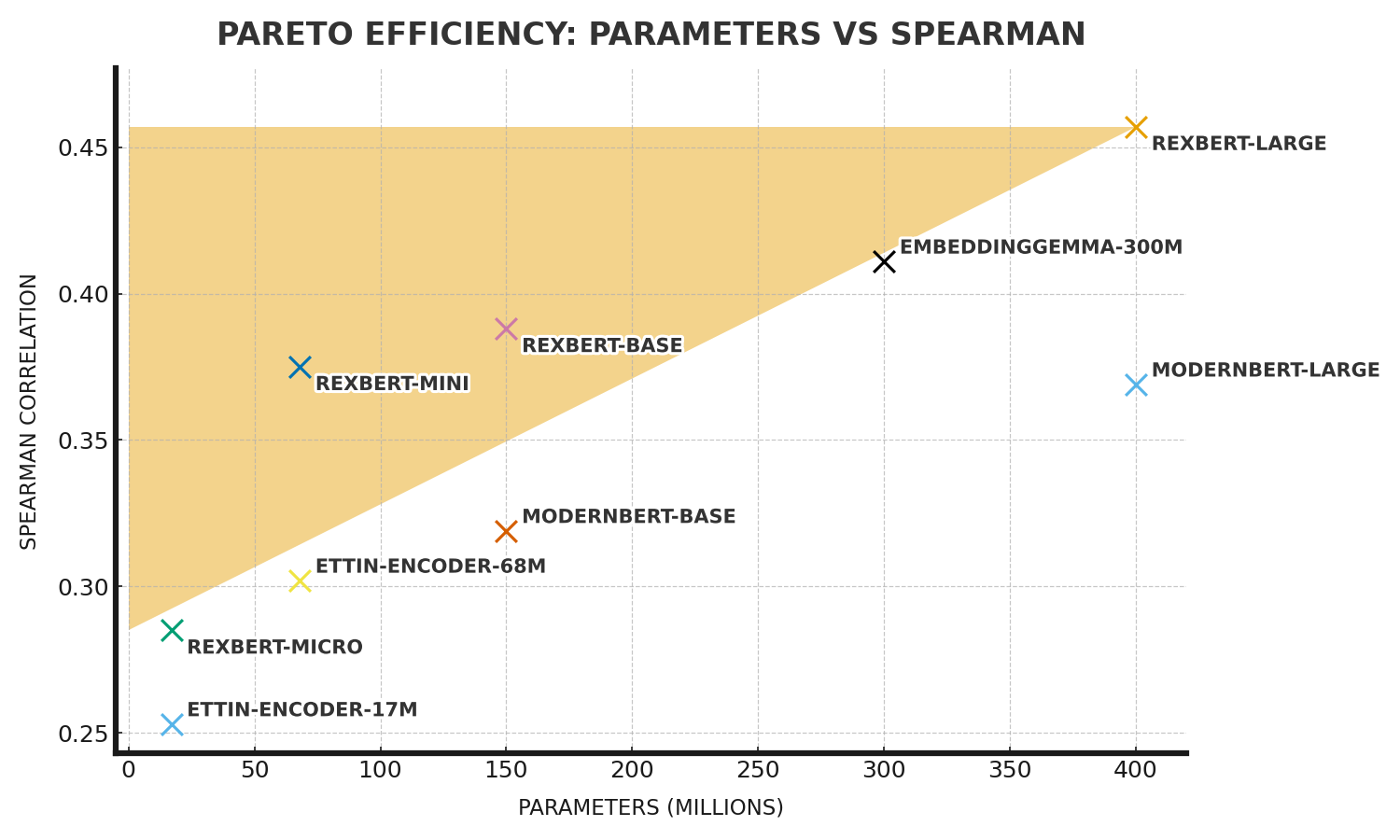
RexBERT
RexBERT is a domain-specialized language model trained on massive volumes of e-commerce text (product titles, descriptions, attributes, reviews, FAQs). Unlike general-purpose transformers, it is optimized to understand the quirks of product data and the way consumers phrase queries. For a technical SEO professional, this means better alignment between how search engines interpret product content and…
-
Introducing Tree Walker
Stop Guessing, Start Optimizing. Introducing Tree Walker for the New Era of AI Search The digital marketing landscape is in the midst of a seismic shift. With the rise of AI-powered search engines and generative experiences, the old rules of SEO are being rewritten. Marketers and content strategists are asking the same urgent question: “How…